
Introduction
Uber uses machine learning (ML) models to power critical business decisions. An ML model goes through many experiment iterations before making it to production. During the experimentation phase, data scientists or machine learning engineers explore adding features, tuning parameters, and running offline analysis or backtesting. We enhanced the platform to reduce the human toil and time in this stage, while ensuring high model quality in production.
Hyperparameter Optimization
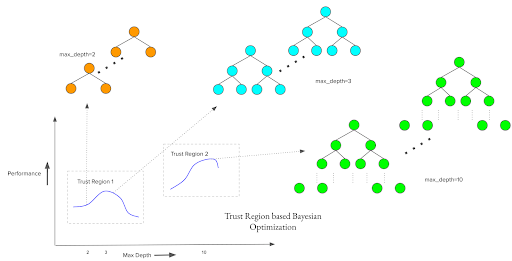
Searching through a large hyperparameter search space is expensive due to the curse of dimensionality, which holds true even for Bayesian optimization techniques that are able to balance explore vs. exploit and incorporate belief updates via a posterior. Hyperparameter importance and selection can be important to help reduce the complexity of the search space as certain hyperparameters have a larger impact on model performance. We have found that for tree-based models such as XGBoost, tuning the maximum tree depth, maximum tree count, learning rate, and minimum child weight etc. tend to yield more performance than others.
The goal is to proactively surface the appropriate parameters for known classes of problems, saving time overall. In addition to optimizing AUC for binary classification problems or mean-square-error (MSE) for regression problems, we expose additional objective functions so that data scientists and machine learning engineers can choose appropriate optimization goals for their problems. To prevent overfitting, we introduced a “penalty” term into the optimization function, which captures the difference between training and test performance. To speed up hyperparameter search for extremely large datasets, we allow early stopping the Hyperparameter Optimization study, if we do not see significant improvements with new trials.
Learning Curves and Early Stopping
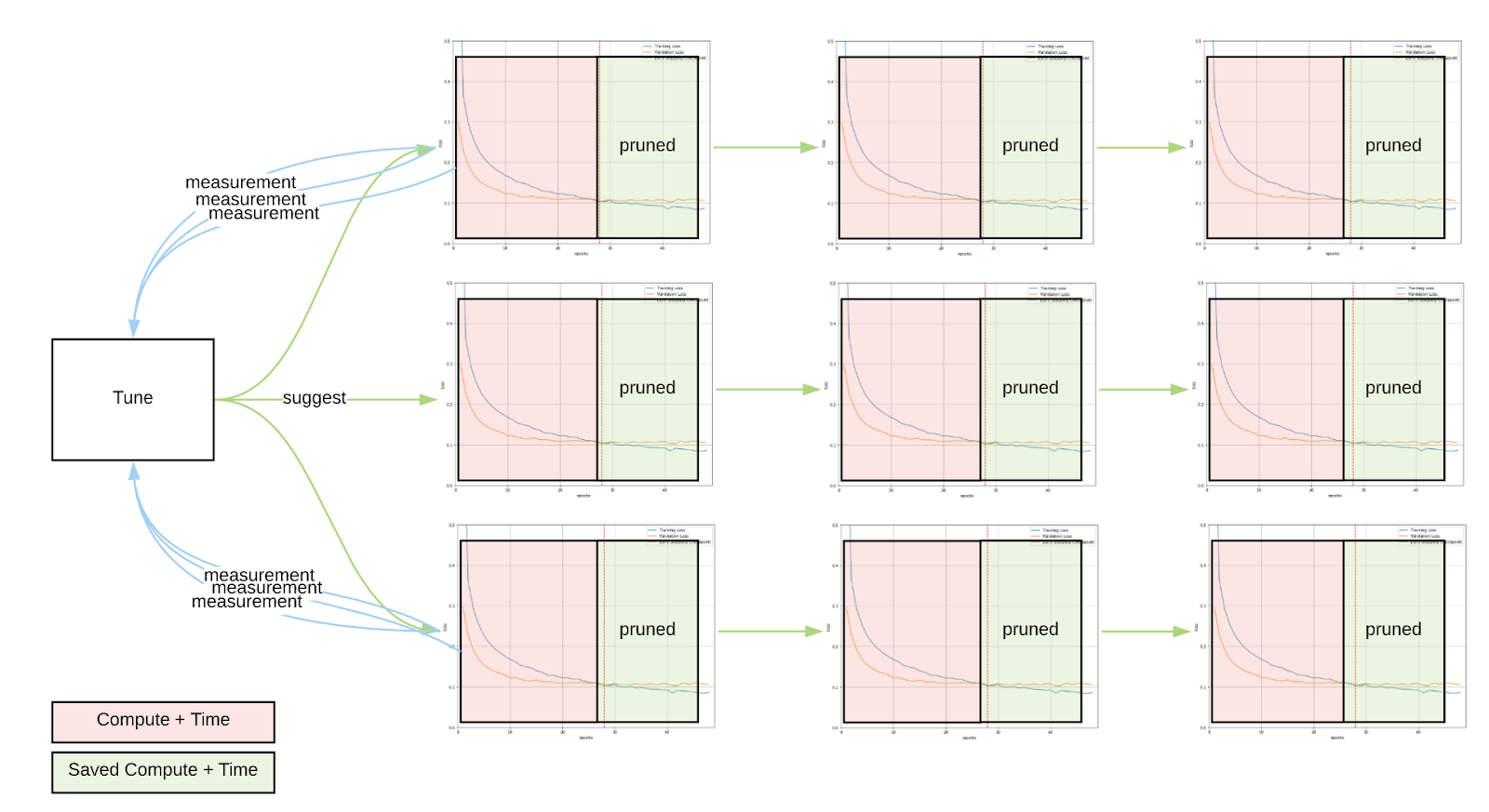
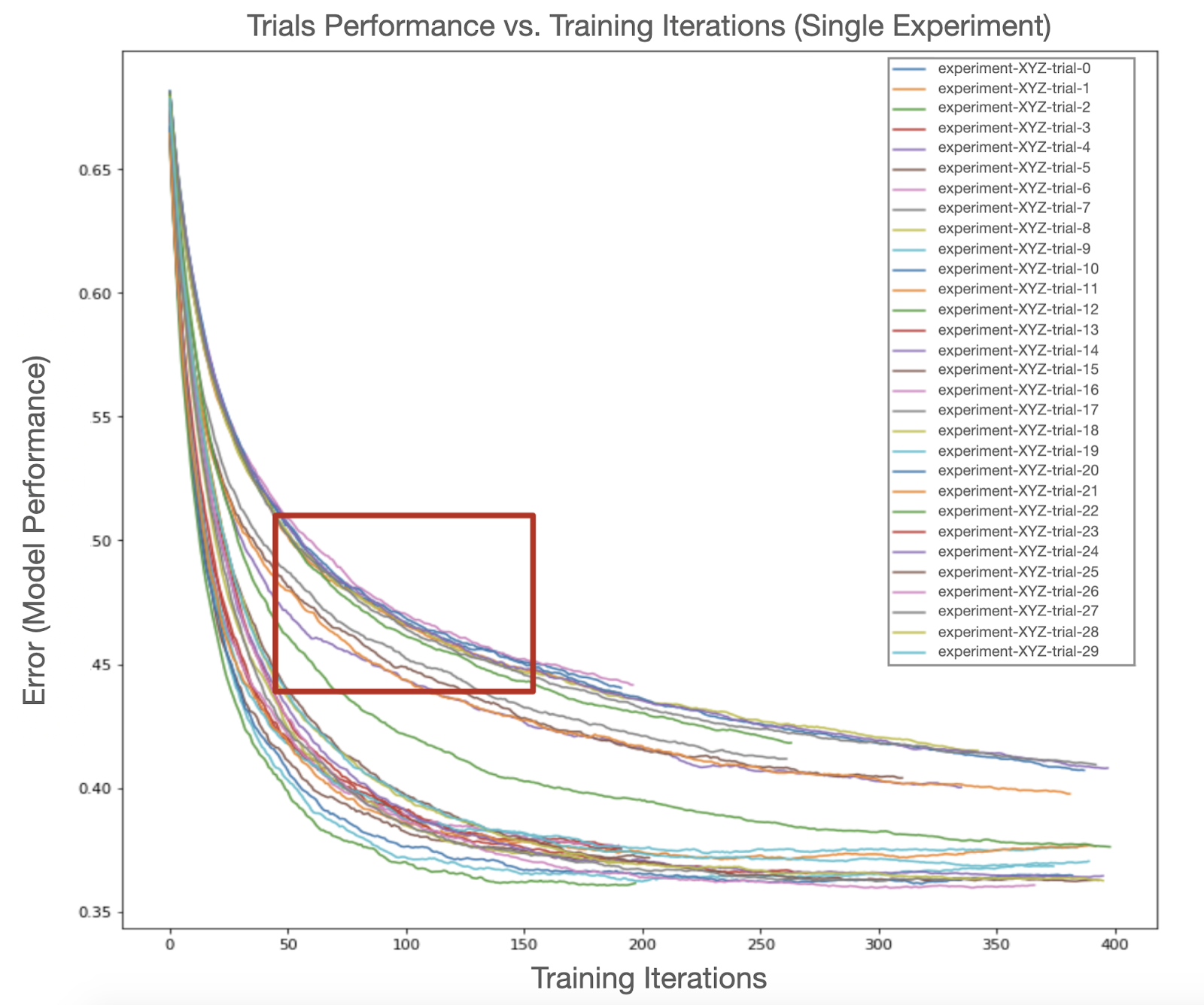
Learning curves are typically employed in machine learning model evaluation and diagnostics by plotting the model or estimator’s performance on the evaluation datasets across many iterations of the training process. It analyzes the model’s incremental performance benefits from additional iterations of training, and provides insights on where it stands with regards to the bias-variance tradeoff. Visibility into the incremental learning process enables users to make informed judgments on the model’s fit, as well as to eagerly apply early stopping on a per-trial basis, as shown in Figure 2. In a hyperparameter optimization setting whereby there are multiple concurrent trials within an experiment, early stopping can also be applied jointly across trials.
On a per-trial basis, learning curves can be used to provide an estimate of convergence for hundreds of interactions before it reaches a steady state, and in a common hyperparameter optimization setup, with a large set of trials, the efficiency gain on a per-trial basis scales with the number of trials.
While we can apply early stopping to individual trials to prune redundant iterations (illustrated in Figure 3), there is often additional headroom gained by allowing information sharing across all the concurrent trials. Learning curve information, when used jointly across all trials in an experiment, allows us to estimate the probability that a trial will outperform others. Techniques such as ASHA (Asynchronous Successive Halving Algorithm) on top of sequential Bayesian Optimization facilitated by a central scheduler for distributed trial execution, can optimize the entire study jointly by prioritizing more promising trials, thereby making the entire hyperparameter tuning process much faster. In a later blog post, we will explain more particulars about the architecture of our auto-hyperparameter optimization service, and the results of employing the black-box optimization service in production.
Feature Transformation
Uber’s machine learning models utilize rich geospatial features that typically require some feature engineering to extract meaningful signals. One approach is to discretize longitude and latitude but this will generate very high cardinality features. We transform longitude and latitude into different embedding spaces, and then we extract geospatial signals from the embedding.
Tree-based models are performing piecewise linear functional approximation, which is not good at capturing complex, non-linear interaction effects. Instead of applying the kernel trick, we auto incorporate top composite features into the tree-based model training and composite features with low importance will get removed.
Additional Strategies
Uber’s business data has a strong time element. Trip information is ingested and partitioned by date string into the Data Lake. Most Uber ML models are trained across a date range. Using a wider date range can allow the model to capture phenomena that have a weekly or monthly cadence, for instance. Increasing the date range of the data is a common way to improve a model’s accuracy, and this is a key best practice.
But we see cases where increased date range results in reduced model accuracy, as well. One reason this can occur is that the greater range magnifies the impact of outliers. In that case we examine the data and compensate in DSL. Another reason this can occur is when the predicted behavior is shifting over time. Applying time-weighted decay on the training data can be useful in such cases. We use the XGBoost column weighting feature, along with DSL transformations, to achieve this.
Tooling to Support Best Practices
Applying the best practices for model tuning involves a non-trivial amount of toil and tracking. We call this process gold-mining. Gold-mining starts by cloning the customer’s Michelangelo project. This avoids running experimental training jobs in the customer’s production environment. Each experimental run involves many error-prone steps, including:
- careful setup (e.g., extending the date range implies changing the train/test split, if it is date-based)
- apply the relevant heuristics (e.g., setting the hyperparameter search ranges)
- update compute resources (e.g., partition models need more workers or parallelism to avoid higher latency)
- record experimental results and identifying current best model
We have automated the above steps, model exploration, and model analysis into a tool to expedite gold-mining.
Summary
Creating and maintaining a high performing model is an iterative process. Michelangelo provides a large catalog of functionalities such as hyperparameter tuning, early stopping, feature transformation, etc. that can be used during model development and tuning stages.
Michelangelo also provides tools to perform comprehensive re-tuning which includes model architecture search, determining feature synergy and redundancy, etc. The net result is that we have been able to provide a framework for iterative tuning and one-off comprehensive tuning of ML models deployed at Uber.
Acknowledgements
We could not have accomplished the technical work outlined in this article without the help of our team of engineers and data scientists at Uber. Special thanks to Smitha Shyam and the entire Michelangelo team for their support and technical discussion. We’d like to also thank the Infra/Computing team for providing elastic resources for us.

Joseph Wang
Joseph Wang serves as a Principal Software Engineer on the AI Platform team at Uber, based in San Francisco. His notable achievements encompass designing the Feature Store, expanding the capacity of the real-time prediction service, developing a robust model platform, and improving the performance of key models. Presently, Wang is focusing his expertise on advancing the domain of generative AI.

Michael Mui
Michael Mui is a Staff Software Engineer on Uber AI's Machine Learning Platform team. He works on the distributed training infrastructure, hyperparameter optimization, model representation, and evaluation. He also co-leads Uber’s internal ML Education initiatives.

Viman Deb
Viman Deb is a Senior Software Engineer on Uber's Machine Learning Platform team. He is based in the San Francisco Bay Area. He works on blackbox optimization service, Uber’s custom Bayesian Optimization algorithm, and Michelangelo’s Hyperparameter tuning workflows.

Anne Holler
Anne Holler is a former staff TLM for machine learning framework on Uber's Machine Learning Platform team. She was based in Sunnyvale, CA. She worked on ML model representation and management, along with training and offline serving reliability, scalability, and tuning.
Posted by Joseph Wang, Michael Mui, Viman Deb, Anne Holler
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global



Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
