The New Version of Orbit (v1.1) is Released: The Improvements, Design Changes, and Exciting Collaborations
January 11, 2022 / Global
Introduction
The previous post gave an overview of Orbit, a Python package developed by Uber in order to perform Bayesian time-series analysis and forecasting. This post provides the details of the version 1.1 updates—in particular, changes in syntax of calling models, the new classes design, and the KTR (Kernel Time-varying Regression) model. Some news about external interests and additional use cases will be discussed as well.
Major Changes in the Syntax
In version 1.1, the syntax of calling models will be different due to the redesign of the classes. An example of calling a DLT (Damped Local Trend) model can be found in the following code snippet. Note that the new interface asks users to supply estimator arguments in a string format, such as “stan-map”, “stan-mcmc”, “pyro-svi”, etc., instead of a Class as in version 1.0.

With the block of code above, users will be able to get a type of Forecaster objects, which can serve a fit-and-predict purpose in a similar fashion to previous versions. To be specific, there are three main types of Forecaster: Maximum a posteriori (MAP), Full Bayesian (MCMC), and Stochastic Variational Inference (SVI). The three forecasters are included as they all have their own strengths. The MAP Forecaster is the fastests of the three. The MCMC Forecaster is better at handling correlated samples and is relatively unaffected by initial conditions. The SVI Forecaster is faster than MCMC (though slower than MAP) but preserves some of the MCMC forecaster’s ability to handle correlated samples and poorly specified initial conditions.
More About the Class Design
Behind the scenes of calling Forecaster, a summary can be visualized in Figure 1.
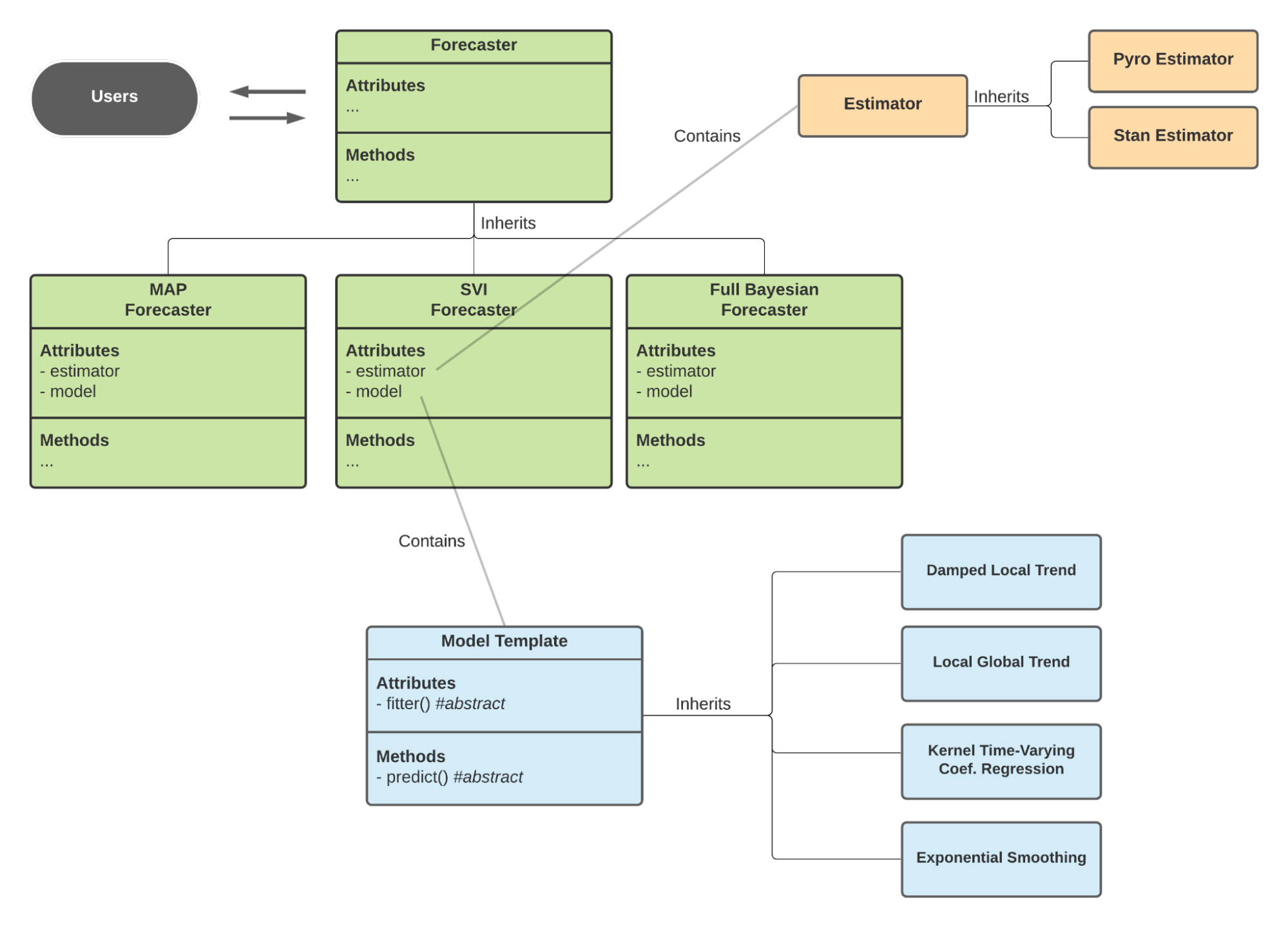
In the new design, there are mainly 3 classes that developer/advanced users may notice:
- Forecaster
- Model Template
- Estimator
The Forecaster objects are the main interface for users to trigger processes such as fitting, forecasting (prediction), and posterior sample extraction. The Forecaster is a wrapper class, which captures different Bayesian estimation flows. In both fitting and forecasting processes, Forecaster relies heavily on its inner object ModelTemplate and Estimator to define the actual tasks to be performed. In particular, ModelTemplate helps define a specific model form and Estimator helps define the API to be used, such as PyStan and Pyro.
The advantage of this design is to decouple the development of the model research and numerical solutions separately. For example, developers who want to create a model type can focus on making a new class derived from the parent class Model, while developers who want to use different types of API (such as PyMC and TFP) can consider adding a new Estimator. Furthermore, if someone wants to improve the workflow overall, they can work on improving the Forecaster.
A tutorial can be found here, which shows how a user can create a simple Bayesian linear model by mixing an Estimator and a Model on the fly.
Kernel-Based Time-Varying Regression (KTR)
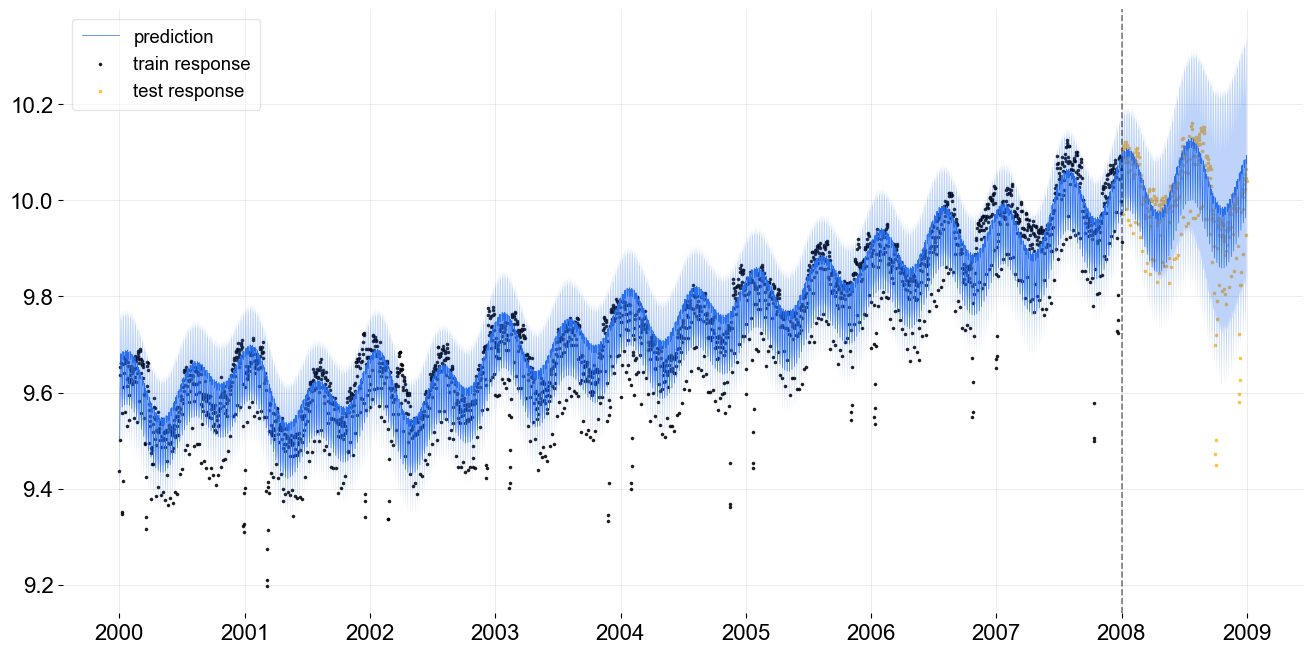
Version 1.1 introduces the kernel-based time-varying regression (KTR) model to Orbit. In overview, the KTR model uses latent variables to define a smooth, time-varying representation of regression coefficients. These representations are made using Kernel Smooths. Time-varying regression coefficients can be used to provide a very clean (simple to understand) way of modeling systems that potentially change with time. The full details of model structure with an example application in marketing data science are found in Ng, Wang, and Dai (2021), as well as a deck and recording from AdKDD. Figure 2 shows a KTR fit and prediction to historic electric demand data (in log units).
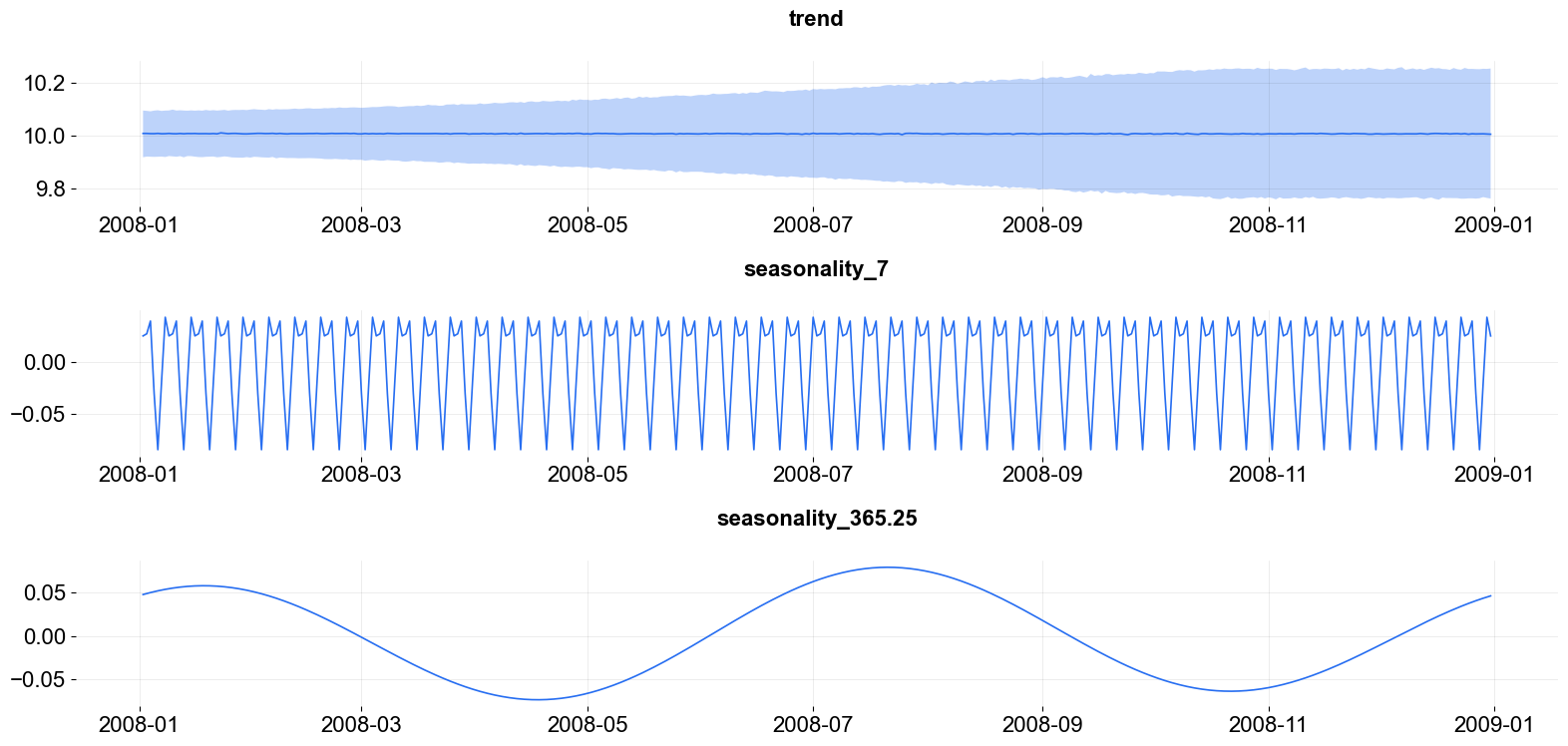
A few highlights of the KTR model are: It naturally decomposes a signal into trend, seasonality, and externalities. Figure 3 shows such a decomposition for the predicted electric load data. Notably, KTR can handle complex seasonality (i,e., in the example there are both yearly and weekly seasonalities). In KTR, smooth representations of coefficient curves are flexible and parsimonious. They are flexible in that they can accommodate one-off extraordinary events (such as the onset of the global pandemic) without requiring a precisely defined impact or extent. The coefficient curves are parsimonious as they use a small number of parameters. The small number of parameters results in the KTR being relatively fast, allowing for KTR to practically handle large numbers (approximately 50) of regressors with low posterior variance. The representations also naturally ensure smooth coefficient curves. It is the combination of all 3 of these properties that make KTR exceptional.
If you are interested in KTR there are a series of 4 tutorials that have been released with the Version 1.1 updates. These can be found at 1, 2, 3, and 4.
Refining Diagnostic Tools
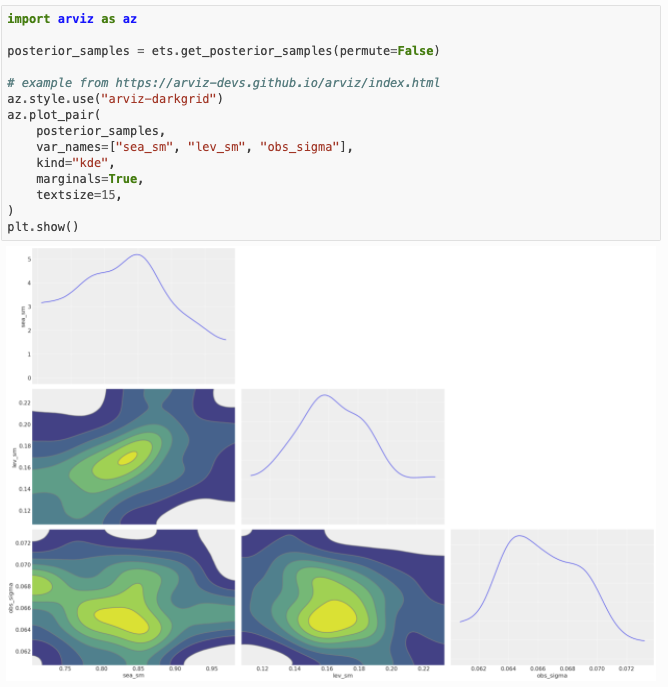
Version 1.1 also refactors and improves the model diagnostic and validation tool. One major change is that it now allows users to specify the format when they extract and export the posterior samples. A newly supported format enables users to run most of the plotting functions in the ubiquitous ArViz package (ArViz visualizations such as density plot, pair plot, and trace plot are highly recommended). These visualizations provide information and insights for users to perform diagnostics and compare results across models. An example of the creation of a posterior pair plot is shown in the below code snippet and the plot is shown in Figure 4.
A new tutorial is available online for the latest plotting functionality with Orbit and the insights you can get from each plot.
Benchmarking Changes in an Automatic Fashion
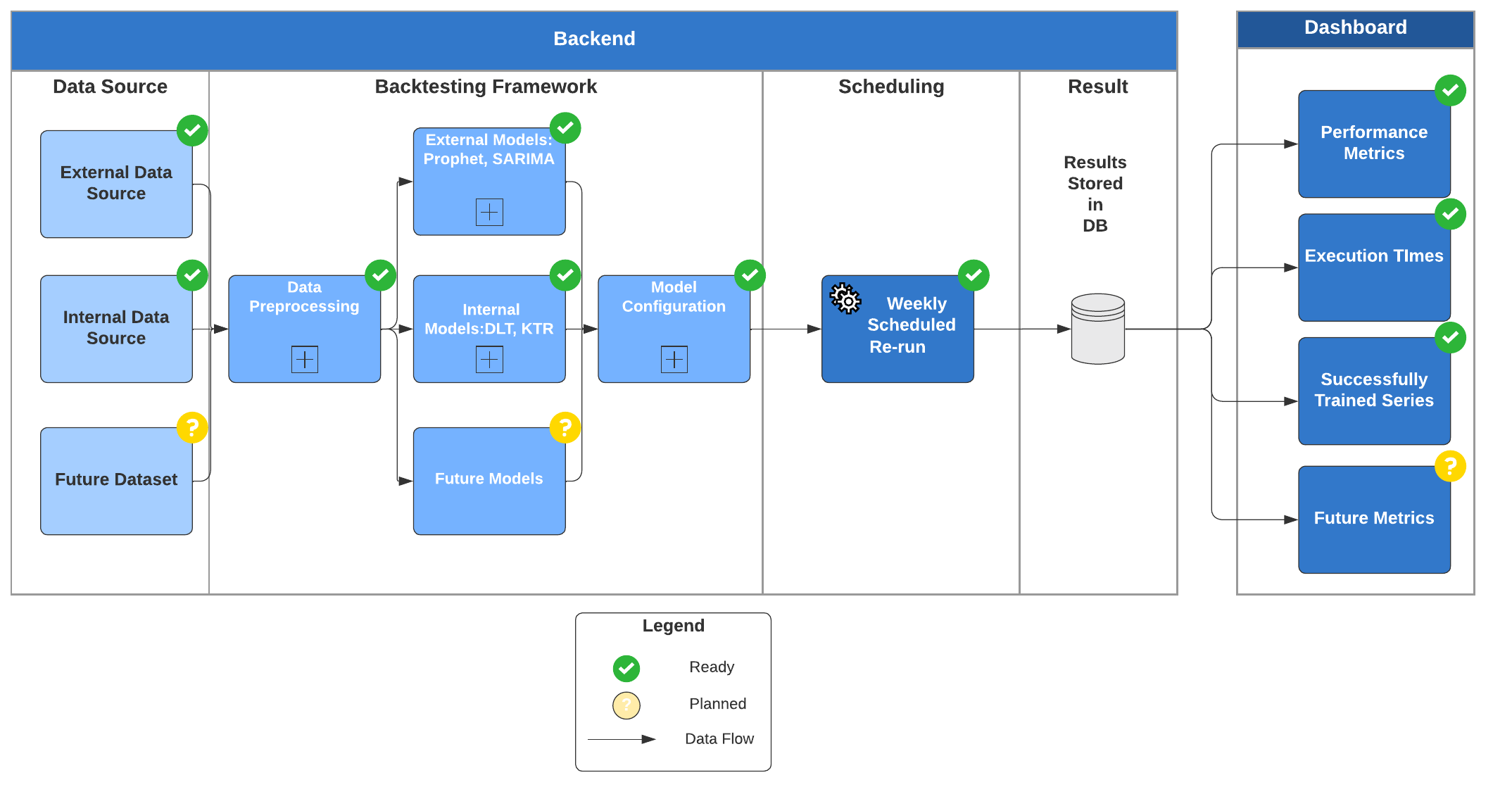
Since version 1.1, the Orbit team has created an internal backtesting dashboard to display the accuracy of Orbit models on a selection of data sets (with multiple folds). The architecture of this dashboard is shown in Figure 5. For each week, both internal and external datasets are processed and fed into predefined models. The backtest results are stored in the database and shown in the internal monitoring dashboard. This dashboard shows whether changes from the previous Orbit version impact model performance; metrics such as symmetric MAPE (sMAPE) are calculated. Figure 6 displays a screenshot of the dashboard on sMAPE and execution time. Other metrics, such as successful run rate, are also reported, to ensure that stability and run time are up to par. Currently, 2 popular models in Python (SARIMA and Prophet) are included in the dashboard for benchmarking.
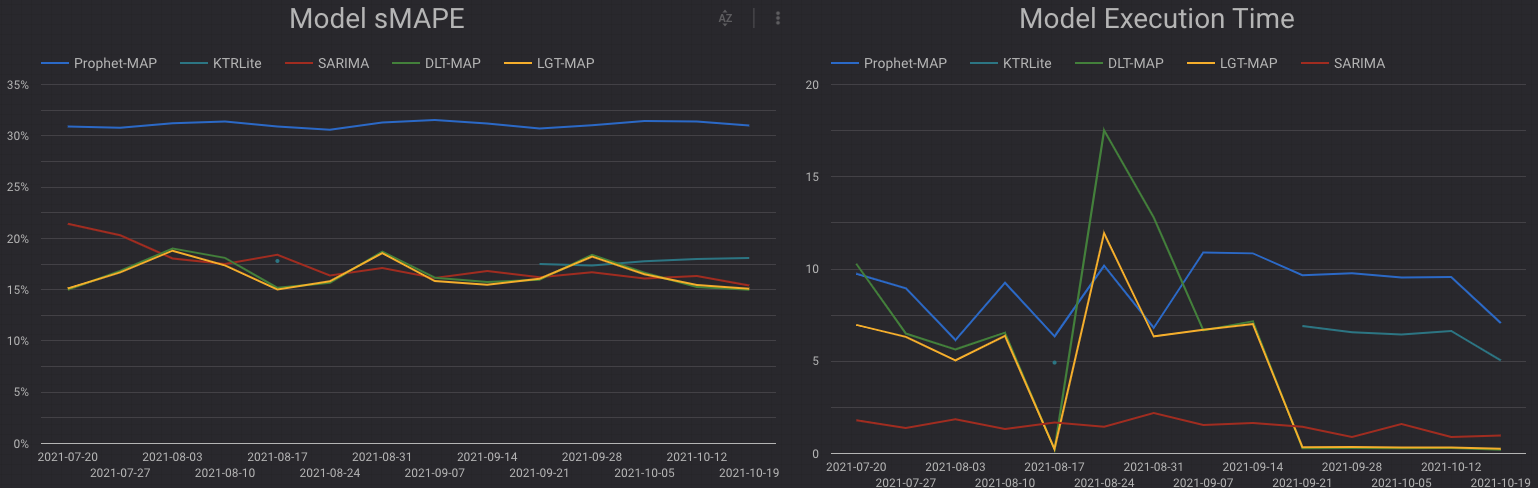
The leveraging of data-driven success criteria allows for close monitoring of model performance. There are objective measures of whether the new features are “heading in the right direction.” This understanding helps streamline the process of developing Bayesian time-series models.
In the future, we are planning to expand this backtesting framework to a wider selection of models, datasets, and metrics.
More Use Cases and News About Orbit
It is fun to build Orbit, however it is even better when it is used! To that end the Orbit team has recently presented at AdKDD (deck and recording) and the 41st International Symposium on Forecasting.
The team is also involved in additional collaborations, both within Uber and externally. Within Uber, Orbit has recently been leveraged for anomaly detection (RADAR) and infrastructure capacity planning.
RADAR (Real-time Anomaly Detection And Response) is an automated anomaly detection platform that aids the Risk Org in detecting payment fraud across Uber’s products. The team leverages Orbit to detect fraud attacks early by combining dozens of time-series signals. Based on these detected anomalies, we use these signals to prioritize both manual and automated processes that stop fraudulent activities in our systems.
Infrastructure capacity planning is how Uber ensures that it is prepared to meet the server load requirements. At Uber there are both on-premises and cloud solutions for providing compute and storage capacity to the engineering teams. The on-premises solutions require planning several years in the future to ensure there is proper power, space, network, and rack supply to meet demand. This has become more uncertain considering the global component supply shortage, but Orbit has nevertheless successfully met the forecasting challenges. It has improved the capacity planning team’s confidence in forecasting engineering metrics and business trends.
Externally the Orbit team is working with Pinterest, Lemonade, MARS, and Facebook to tackle difficult forecasting problems in rigorous, Bayesian ways.
Conclusion and Moving Forward
Orbit has been designed as an ARM to build custom Bayesian models that can serve for various use cases, such as forecasting, anomaly detection, quantifying uncertainties and risk, and causal analysis. Besides pursuing forecasting accuracy, practicality is Orbit’s main focus.
In July 2021, the Orbit team hosted a virtual meetup (slides). We are considering future workshops, and continually maintaining the Orbit package. If you have any feedback or are interested in developing Bayesian models for forecasting, feel free to interact with us through our GitHub page and the Slack channel.
Acknowledgements
In addition to all of the users and participants in our Orbit-related events, we would like to thank the following individuals:
- Karim Mattar and Calvin Worsnup who lead in supporting the use cases of capacity planning
- Sergey Zelvenskiy and Tiffany Yu who lead in supporting the use cases of RADAR
- The Performance Marketing Team for continuous support for the development
- Brendan Rocks (Pinterest), Ray Ravid (Lemonade), the MARS DS team, Huigang Chen and Diana Ichpekova (Facebook), and the Facebook AR/VR Analytics team for having the technical jams and usage discussions with us

Edwin Ng
Edwin Ng is a Senior Applied Scientist at Uber where he leads the team to build statistical and machine learning models to support measurement and strategic decisions in marketing. He was one of the speakers in the 40th International Symposium on Forecasting and AdKDD 2021 where he presented probabilistics forecasting and its applications in marketing.

Zhishi Wang
Zhishi Wang is an Applied Scientist on Uber’s Marketing Science team. He mainly works on time series R&D, package development, and model platformization.

Yifeng Wu
Yifeng Wu is an Applied Scientist on the Marketing Data Science team. Yifeng works on building the creative optimization platform and real time bidding strategies on display channels using causal inference. Yifeng is a contributor to Orbit.

Ariel Jiang
Ariel Jiang is an Applied Scientist on Uber’s Marketing Data Science team. She works on planning and forecasting, marginal benefit, and experimentation.

Gavin Steininger
Gavin Steininger is a Senior Applied Scientist at Uber where he works with a team to build statistical models for measuring the impact of marketing spend (in particular Offline Awareness campaigns). His background is Bayesian Geostatistics and free-to-play gaming.

Michale Guo
Michale Guo is an Applied Scientist at Uber. He works on scalable forecasting systems. His background is in Mathematics and Financial Engineering.
Posted by Edwin Ng, Zhishi Wang, Yifeng Wu, Ariel Jiang, Gavin Steininger, Michale Guo
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global




Most popular

Jupiter: Config Driven Adtech Batch Ingestion Platform

Uber Rider x Miami HEAT Ticket Sweepstakes OFFICIAL RULES

A beginner’s guide to Uber vouchers for transit agency riders

Uber Earner x Miami HEAT Ticket Sweepstakes OFFICIAL RULES
Products
Company
