Streaming Real-Time Analytics with Redis, AWS Fargate, and Dash Framework
September 2, 2021 / Global
Introduction
Uber’s GSS (Global Scaled Solutions) team runs scaled programs for diverse products and businesses, including but not limited to Eats, Rides, and Freight. The team transforms Uber’s ideas into agile, global solutions by designing and implementing scalable solutions. One of the areas of expertise within GSS is the Digitization vertical. The Digitization team efficiently converts physical signals into digital assets and provides services in labeling, in-field testing, data curation and validations for maps, product incubation, freight BOL (bill of lading), Eats menu uploads, etc.
All these digitization services are performed by thousands of humans (operators) working on our internal applications across many locations around the globe. While an operator is digitizing data, our backend collects a clickstream of all the user interactions in the form of raw events to the scale of 10 million events per day in AWS (Amazon Web Services) cloud infrastructure. Sometimes this data is also moved to Uber’s own data centers. Our data analytics team performs analysis on this data to improve/tweak the process, augment tooling infrastructure, address operator motivation, and improve operator skills. Analytics is usually performed by querying big data lakes and using different frontend tools for visualisation. Generally, any analytics setup has a latency (source to user) component to it and the latency of our existing (pre-COVID) infrastructure was 1 hour. With the onset of COVID-19 crisis, the digitization process had to be transitioned to work-from-home mode, leading to additional operational complexity of remotely managing a huge workforce of operators. This complexity created a gap in team’s communication, decision making, and collaboration. Where 1-hour latency of our analytics platform was previously acceptable, real-time analytics was needed to fill this gap. This blog describes how we improved latency of our data architecture by building a real-time analytics system.
While we researched approaches used for building real-time dashboards (example), we did not find an end-to-end solution, considering how rich visualization can be achieved at lower cost. We considered different visualization approaches and also looked at commercial solutions to come up with our choices. Another differentiating aspect was that our solution also addresses the need for a “single source of truth” on Amazon S3 (Amazon’s “simple storage service”), from which both streaming and batch processed dashboards would to be sourced, rather than hooking directly into the Amazon Kinesis Data Firehose stream itself. This intermediate storage lets us recover data (for the streaming window) with a replay. We production tested our visualizations with thousands of users for low load times and reliability.
Old Data Architecture
Our application is deployed in AWS. Events generated by the application are stored in S3 by Kinesis Firehose every minute. These are then either analyzed in AWS directly, or brought to Uber’s prime data center to combine with other sources for analysis. The scheduled copy jobs running in our data centers with Piper (Uber’s centralized data workflow management system, described here) take a few more minutes to complete the copy. From this data, various reports are generated to assess the quality and output of the work. We also aggregate the data at different levels (like region, team, and individuals) on our internally developed Business Intelligence (BI) tools, which can then be viewed by managers, leads, and other team members.
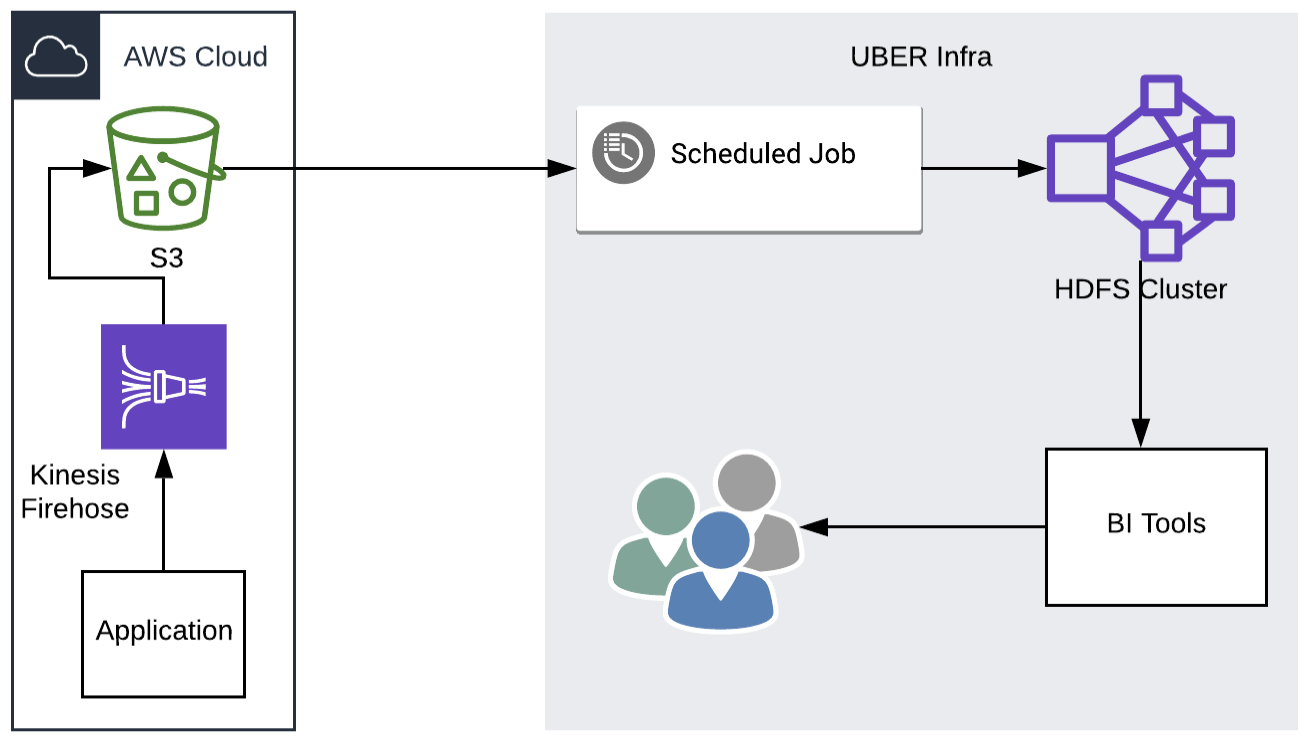
Problems Seen with the Old Architecture
- The quality, output, and other reports that are monitored daily are generated on dashboard tools with scheduled update intervals, the best possible being 1 hour. This was actually tied to the resources available in the Yarn pool, and this dependency prevents us from creating faster dashboards.
- An additional delay is introduced for completing the copy to Uber infrastructure. If the same architecture is used, then the total delay in observing data is sometimes more than an hour.
- The impact of delay was more pronounced in the work-from-home conditions. The existing architecture failed to provide a live view of the team to its remote leads.
- The BI tools are general-purpose reporting tools, and are not suitable for creating the customized, feature-rich visualizations possible with programmatic frameworks like Dash.
Alternatives Considered
Our need to be able to put up a visualization within a minute of data being generated was not satisfied. The following options were considered for building a solution:
Data Pipelining Alternatives
- Event-based jobs to copy data from S3 to Apache Hive. At each object creation event in S3 a job could be triggered in Piper to copy it over to Uber Prime data infrastructure. Calling Piper APIs from AWS was not possible.
- Event-based stream to Apache Hive with Apache Kafka. This was based on Uber’s internal frameworks, built along with Piper and Apache Kafka. But even this had an unacceptable minimum latency, due to fixed minimum batch processing limits based on cluster resources.
Data Visualization Alternatives
- Using Grafana® to plot user activity as a time series. The idea was to track user activity using the events generated from the application. Grafana is a robust solution to track cluster resources, and worked extremely well to plot data fast, but could not be used to build custom graphs.
- AWS Quicksight was also considered, but the cost to allow licenses for thousands of users was too high.
Even taking all of these options into account, we still did not find a suitable approach for our use case, which would provide real-time streaming analytics and visualizations. We further explored components that could be stitched together to come up with a solution
Our Choice of Components
We needed a fast database that could efficiently store the data in the structure we wanted. In some cases we wanted aggregations. We also needed fast retrieval to enable high refresh rates on dashboards serving thousands of active users. Our data retention need for the real-time use cases was not more than a couple of days. The daily and weekly dashboards could be used to look at historical data if needed, so we could continue to rely on them. These requirements were met by Redis™*, which is a fast, in-memory database.
We needed a flexible deployment option where the deployment servers could be scaled up and down as per the need. Also as the application itself was deployed in AWS, it made sense to use AWS deployment options, rather than moving the data to Uber infrastructure. This allowed us to use components like Amazon Simple Notification Service (AWS SNS) and AWS Lambda to enable event-based data processing, rather than scheduled processing. We decided to use AWS Fargate containers for different parts of the application in a near microservices approach. We wanted to use different containers for ingestion, storage, and visualization in combinations, if possible, to optimize resource utilization.
We wanted to be able to build custom graphs and programmatically process the data as well before putting it on the graphs. We wanted an open-source, low-cost, feature-rich framework that we could start using in a short time considering our existing knowledge of Python, which we were using for our analytics work already. We found Dash Framework as a suitable option for these needs. Dash’s backend being in Python also allows us to connect to other sources, such as application REST APIs, if such a need arises in future.
New Architecture
We performed trials in a local machine with individual components, simulating data inflow with a copy of data from S3. We built components for ingestion, Redis, and visualization in docker containers, wrote a script to trigger post messages to the ingestion container to simulate object creation events, and developed ingestion code to read, filter, transform, and insert events into Redis. We initially chose Grafana for visualization to quickly test the flow of data from source to a live graph. This was successful, so we replaced Grafana with a Python Dash container to build dynamic visualization for one of our use cases. With corresponding components in AWS, we came up with the below architecture:
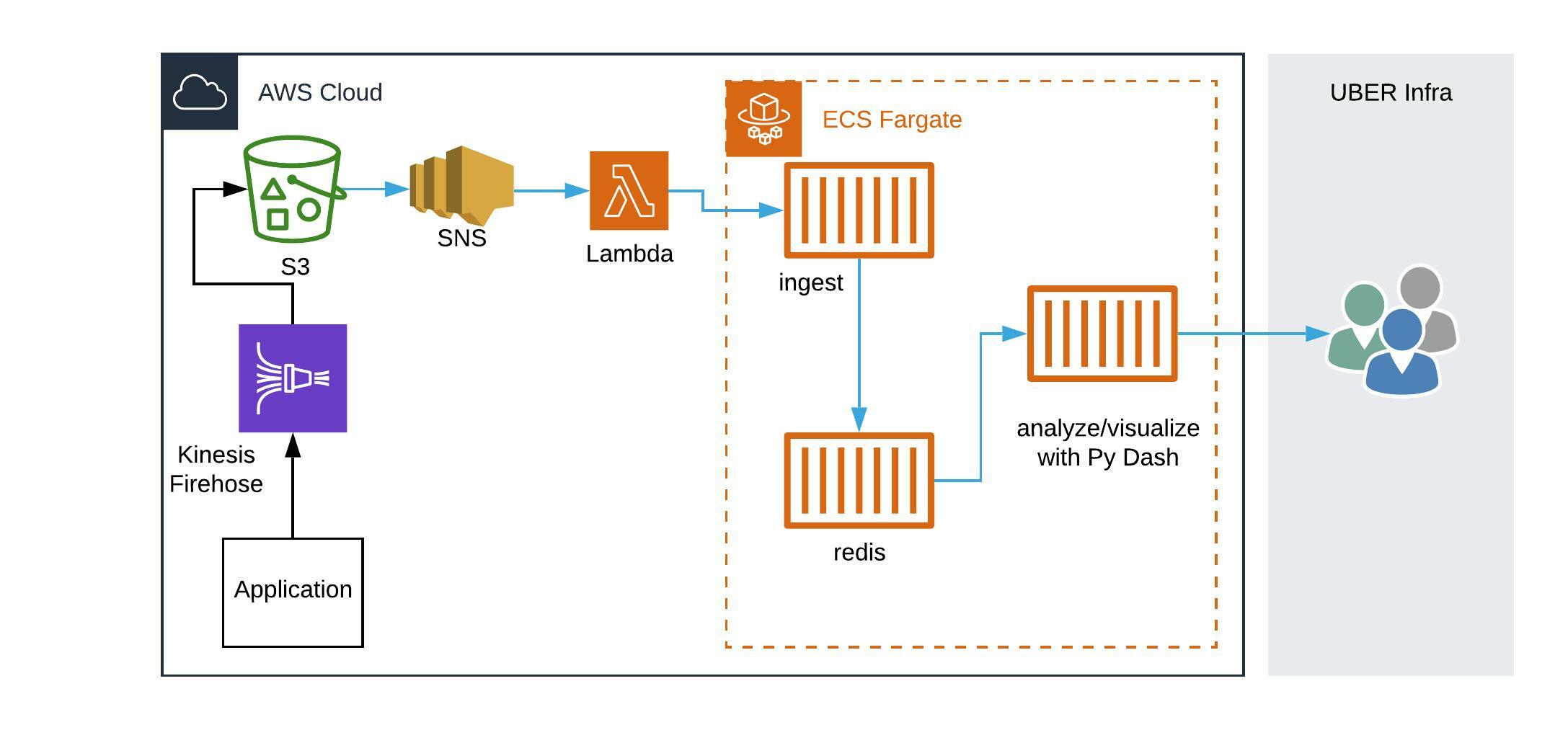
Components
Application
The application deployed in AWS emits different types of events based on the operator activity on the application, e.g.:
- Task pick-up
- Task updates
- Activity like mouse movement, clicks, etc.
- Task submission, and so on
Kinesis Firehose
The application events are produced to a Kinesis Firehose with some amount of transformation. The events are partitioned at day level to satisfy the query pattern, and to optimize the distributed query processing.
S3 Raw Event Store
The raw events are stored in a S3 bucket, which gives us an opportunity to process the data based on object creation events generated from the bucket. S3 also stands as the source of truth, in case there are failures or data loss downstream.
SNS
The event notifications are used to trigger different lambdas created in our VPCs. The lambdas then either filter “object create notifications,” or pass them onto Fargate containers as is. It also helps us fan out and trigger multiple downstream processes once events for a duration land in S3.
Fargate Containers
- Ingest: This container reads the contents from S3 files and creates efficient structures in the Redis container, which can be queried to create different dashboards.
- Redis: This is a standard Redis container, which helps us store relevant real-time events in structures as needed.
- Analysis/Visualization: We started off with simple dashboards and then added more complex ones, using a variety of methods:
- We used the Python Dash framework to create automatically refreshing visualizations for time spent on application and workflow status, with multi-level filters and key aggregate metrics
- We needed monitoring of time series data, so we ended up using a Grafana-Redis datasource with a Redis TimeSeries module
Impact
How it was Measured
Data visibility increased for operators, leads, and managers. We also developed analytics around the application’s usage. We tracked the count of hits on the application to monitor usage, and found the hits to be in sync with the total number of users. The number of auto refreshes were also tracked, which helped us to understand the typical session durations per day.
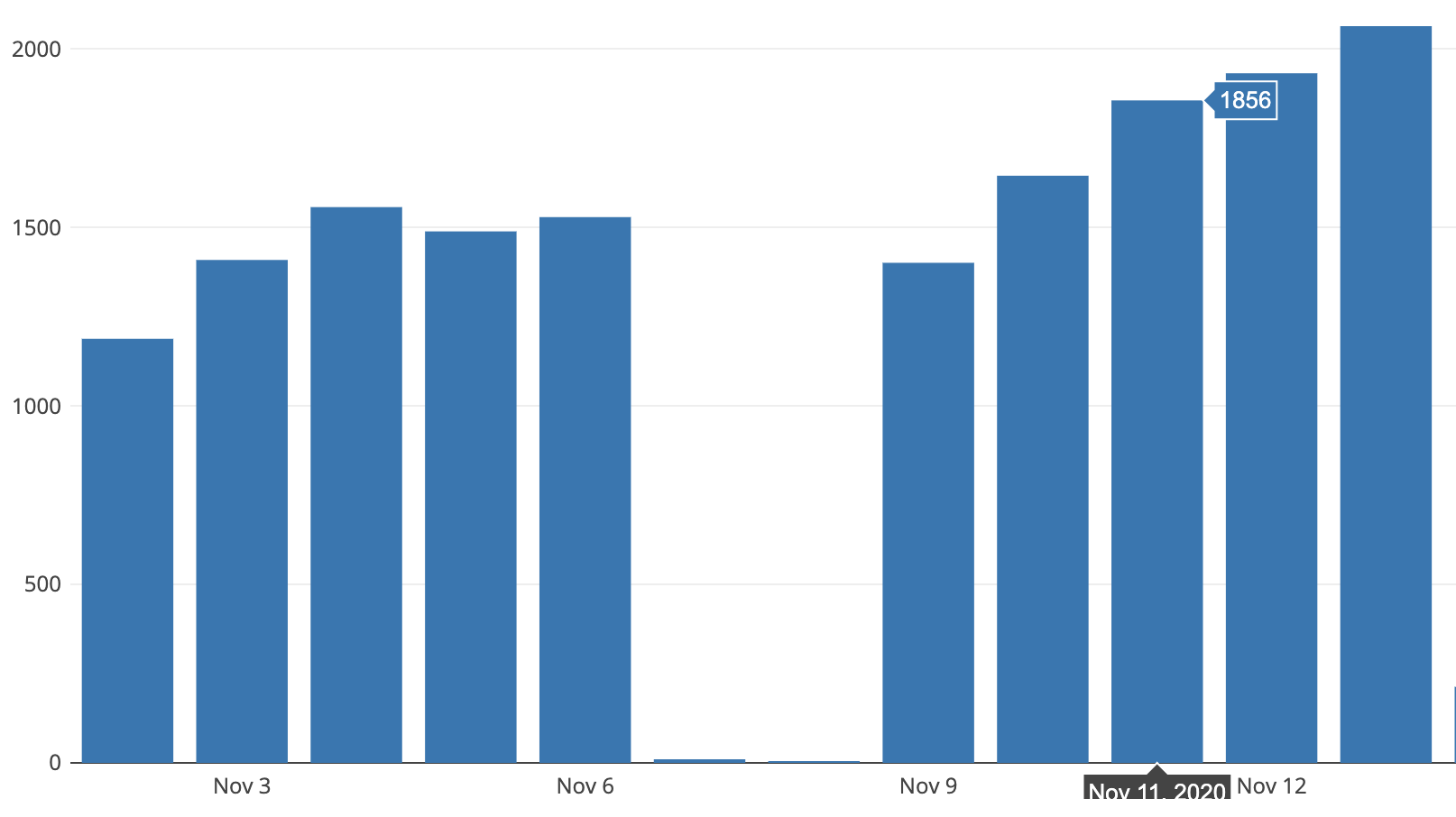
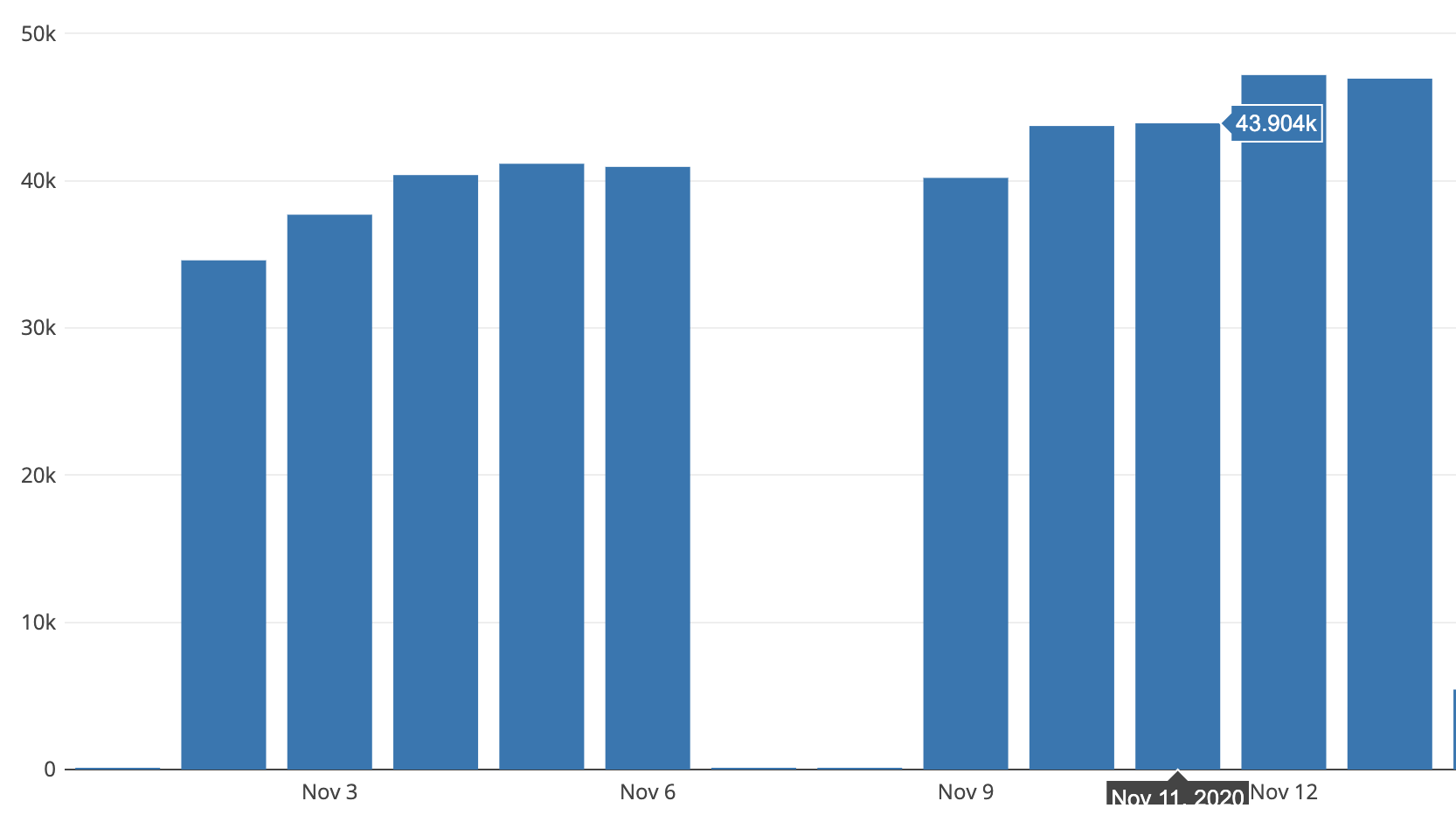
With an auto-refresh rate of 5 mins, an average 1,800 hits daily, and 44,000 auto-refreshes for these sessions, this means (44,000 / 1,800) x 5 minutes, or approximately 120 minutes per user per day are spent on our application.
How it Helped Work-Life
Real-time analytics helps our operators get fast feedback for their work on the application. With real-time updates the operators could track the amount of time spent on the application daily, and could work with greater flexibility. This allowed operators to achieve a better work-life balance. Another dashboard we built to track work progress was also equally popular among managers and leads, enabling faster workflow management in their teams.
Challenges Faced and Lessons Learned
- We wanted to replace the ingest container with a Lambda function. However, when we tried this out by placing the Lambda in our VPC, we found them to be slow in initialization, and they could not keep up with the application’s input rate. This was a known issue, and has been improved upon in AWS.
- We also saw that performance of the Dash framework dropped when we replaced a simple HTML dashboard with a rich dashboard using multiple key metrics, chained filters, and auto-refresh. When multiple operators opened the dashboards at peak times, it started to freeze. We fixed our code to remove redundancies and implemented several changes, like using client-side JavaScript callbacks and optimized data structures to bring the page loading times down by 96% during peak hours.
- Our ingest containers, which work in Flask, would crash after 50 to 60 days. We enabled memory and CPU plots for the container with Amazon CloudWatch and confirmed that there was a memory leak. On investigation we figured that this was a known issue, which could occur with the underlying Python interpreter.
- We realized that backup and restore were not needed for the data stored in Redis because the source data was present in S3 regardless, allowing a replay to the real-time DB using a Lambda function in case of failure, and the visualizations were not mission-critical.
Amazon Web Services, the “Powered by AWS” logo, Amazon S3, Amazon Kinesis, AWS Lambda, Amazon CloudWatch, Amazon Simple Notification Service, and AWS Fargate are trademarks of Amazon.com, Inc. or its affiliates in the United States and/or other countries
Apache®, Hive, Kafka, Apache Hive, and Apache Kafka are registered trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks
*Redis is a trademark of Redis Labs Ltd. Any rights therein are reserved to Redis Labs Ltd. Any use by Uber is for referential purposes only and does not indicate any sponsorship, endorsement, or affiliation between Redis and Uber
Dash is a registered trademark or a trademark of Plotly Technologies, Inc. in the United States and/or other countries. No endorsement by Plotly Technologies, Inc. is implied by the use of this mark
The Grafana Labs Marks are trademarks of Grafana Labs, and are used with Grafana Labs’ permission. We are not affiliated with, endorsed, or sponsored by Grafana Labs or its affiliates

Piyush Choudhary
Piyush Choudhary specialises in building data platform products. He has built the data platform for the labeling vertical of the Global Scaled Solutions (GSS) team at Uber. Previously he has worked on operations and scaling large teams from scratch.

Sujeet Srivastava
Sujeet Srivastava is a former Consulting Architect for GSS’s Vendor Engineering Team from Accenture, and was involved in building Big Data Platforms and Distributed Computing.
Posted by Piyush Choudhary, Sujeet Srivastava
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global



Most popular

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
Products
Company
