Peloton: Uber’s Unified Resource Scheduler for Diverse Cluster Workloads
October 30, 2018 / Global
Cluster management, a common software infrastructure among technology companies, aggregates compute resources from a collection of physical hosts into a shared resource pool, amplifying compute power and allowing for the flexible use of data center hardware. At Uber, cluster management provides an abstraction layer for various workloads. With the increasing scale of our business, the efficient use of cluster resources becomes very important.
However, our compute stack was underutilized due to several dedicated clusters for batch, stateless, and stateful use cases. In addition, the very dynamic nature of our business means vast fluctuations in rideshare demand due to holidays and other events. These edge cases have led us to over-provision hardware for each cluster in order to handle peak workloads. Relying on dedicated clusters also means that we can’t share compute resources between them. During peak periods, one cluster may be starving for resources while others have resources to spare.
To make better use of our resources, we needed to co-locate these workloads on to one single compute platform. The resulting efficiencies would reduce the technical cost per trip on our infrastructure, ultimately benefiting our driver-partners and riders who depend on Uber to make a living or get around.
The solution we arrived at was Peloton, a unified scheduler designed to manage resources across distinct workloads, combining our separate clusters into a unified one. Peloton supports all of Uber’s workloads with a single shared platform, balancing resource use, elastically sharing resources, and helping us plan for future capacity needs.
Compute cluster workloads
There are four main categories of compute cluster workloads used at Uber: stateless, stateful, batch, and daemon jobs.
- Stateless jobs are long-running services without persistent states.
- Stateful jobs are long-running services, such as those from Cassandra, MySQL, and Redis, that have persistent state on local disks.
-
Batch jobs typically take a few minutes to a few days to run to completion. There is a broad category of batch jobs for data analytics, machine learning, maps, and autonomous vehicles-related processing, emanating from software such as Hadoop, Spark, and TensorFlow. These jobs are preemptible by nature and less sensitive to short-term performance fluctuations due to cluster resource shortages.
- Daemon jobs are agents running on each host for infrastructure components, such as Apache Kafka, HAProxy, and M3 Collector.

The need for unified resource scheduling
Compute clusters are critical to powering Uber’s business. They make it much easier for infrastructure owners to manage compute resources in both on-premise and cloud environments. Clusters are the fundamental building blocks for Uber’s microservice architecture and provide several important features for service owners, such as self-healing, dynamic placement, and rolling upgrades, as well as supporting our Big Data workloads.
Co-locating diverse workloads on shared clusters is key to improving cluster utilization and reducing overall cluster costs. Below, we outline some examples of how co-locating mixed workloads drives utilization in our cluster, as well as helps us more accurately plan cluster provisioning:
- Resource overcommitment and job preemption are key to improving cluster resource utilization. However, it is very expensive to preempt online jobs, such as stateless or stateful services that are often latency sensitive. Hence, preventing preemption of these latency-sensitive jobs requires us to co-locate batch jobs that are low-priority and preemptible on the same cluster, enabling us to better utilize overcommitted resources.
- As Uber’s services move towards an active-active architecture, we will have capacity reserved for disaster recovery (DR) in each data center. That DR capacity can be used for batch jobs until data center failover occurs. Also, sharing clusters with mixed workloads means we no longer need to buy extra DR capacity for online and batch workloads separately.
- Uber’s online workloads spike during big events, like Halloween or New Year’s Eve. We need to plan capacity for these high-traffic events well in advance, requiring us to buy hardware separately for online and batch jobs. During the rest of the year, this extra hardware is underutilized, leading to extra, and unnecessary, technical costs. By co-locating both workloads on the same cluster, we can lend capacity from batch workloads to online workloads for those spikes without buying extra hardware.
- Different workloads have resource profiles that are often complementary to each other. For example, stateful services or batch jobs might be disk IO intensive but stateless services often use little disk IO. Given these profiles, it makes more sense to co-locate stateful services with batch jobs on the same cluster.
Realizing that these scenarios would enable us to achieve greater operational efficiency, improve capacity planning, and optimize resource sharing, it was evident that we needed to co-locate different workloads together on to one single shared compute platform. A unified resource scheduler enable us us to manage all kinds of workloads to use our resources as efficiently as possible.
Alternate cluster schedulers
Large-scale cluster management has been a hot topic in recent years due to the increasing scale of data centers and the wide adoption of Linux containers. There are four cluster managers related to our work: Google Borg, Kubernetes, Hadoop YARN, and Apache Mesos/Aurora.
Cluster scheduler architectures
Figure 2, below, compares four cluster scheduler architectures by breaking them down into six functional areas: task execution, resource allocation, task preemption, task placement, job/task lifecycle, and application-level workflows such as MapReduce:
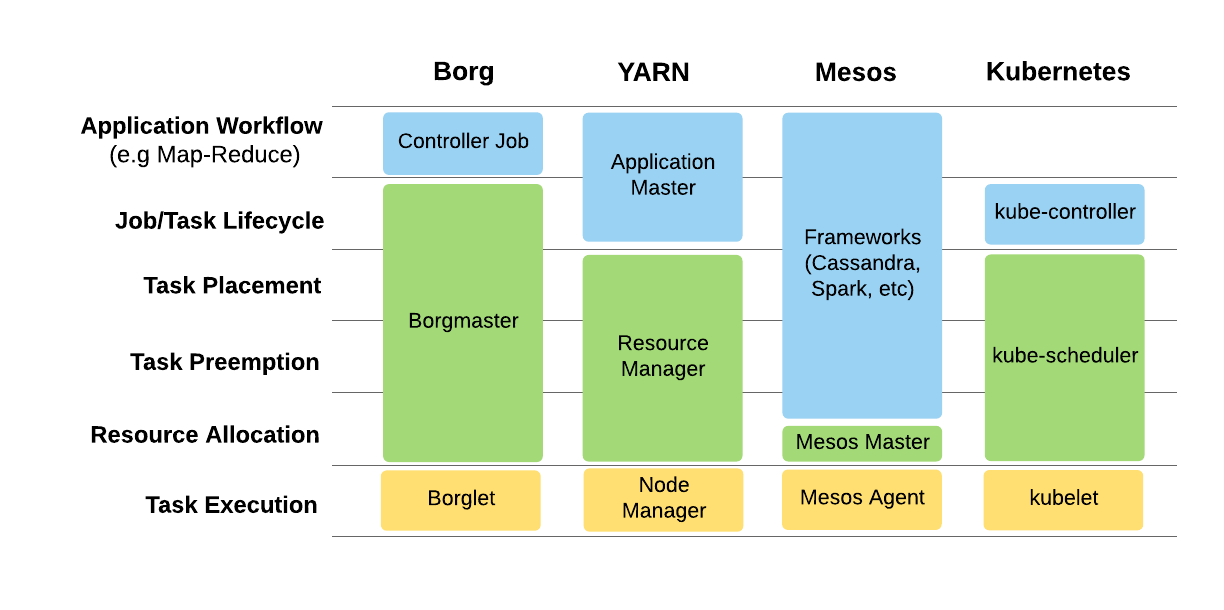
Resource allocation in Mesos is divided into two parts: coarse-grained allocation at the framework level and fine-grained allocation at the job level. Mesos uses DRF to allocate resources to frameworks but delegates the job-level allocation to each framework.
For the following reasons, none of these existing schedulers met our needs:
- Borg is not an open source solution, thus, we could not use it.
- YARN is a batch scheduler for Hadoop with no or very limited support for stateless, stateful, and daemon jobs.
- Kubernetes hasn’t been able to scale to the large clusters that Uber requires, i.e. 10,000-plus, nor does it support elastic resource sharing. It is also not the ideal scheduler for batch workloads due to the high-churn nature of batch jobs.
- Mesos was designed to manage clusters rather than schedule workloads. Its coarse-grained resource allocation to frameworks are suboptimal for our use case because it doesn’t support elastic resource sharing and requires building a scheduler for each workload.
So, we built Peloton, a unified resource scheduler that runs on top of Mesos, to support our workloads.
Peloton overview
Peloton is built on top of Mesos, leveraging it to aggregate resources from different hosts and launch tasks as Docker containers. To manage cluster-wide resources more efficiently and make global scheduling decisions faster, Peloton uses hierarchical resource pools to manage elastic resources among different organizations and teams.
Figure 3, below, shows the architecture of Peloton compared to other cluster management systems:
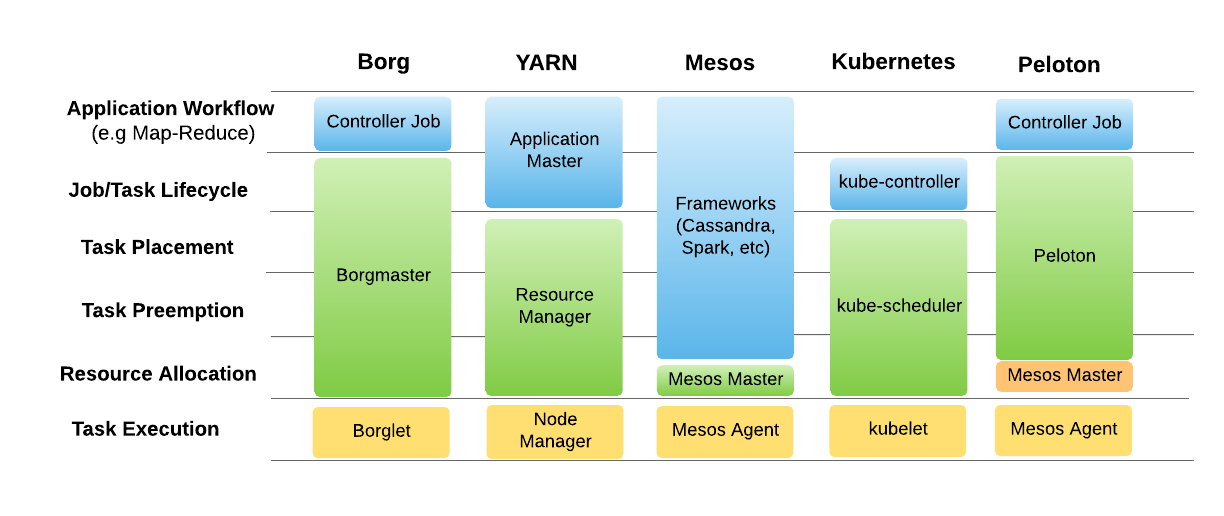
With Peloton, we follow the approach used by Borg, with the primary difference being the use of Mesos as a resource aggregation and task execution layer. Borg makes use of its own Borglet for task execution. Peloton takes a similar approach to the Borg controller job or YARN application master (minus job and task lifecycle management) for extensibility of user-specified applications.
Architecture
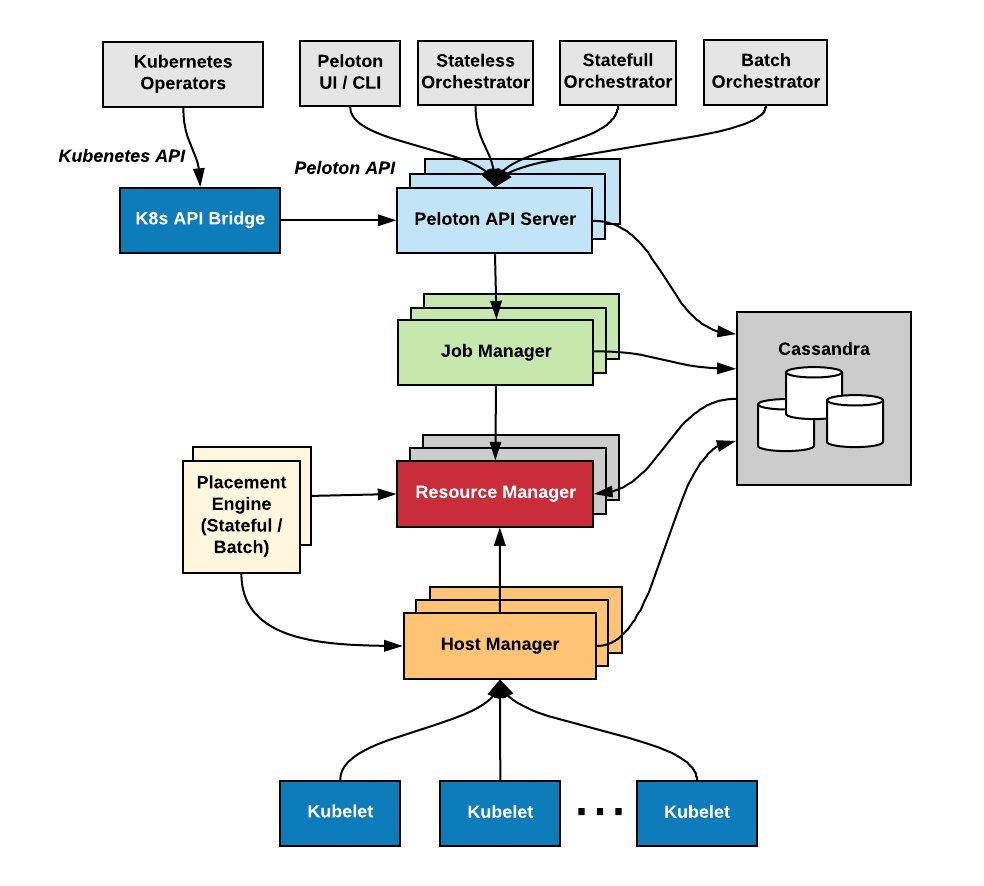
To achieve high-availability and scalability, Peloton uses an active-active architecture with four separate daemon types: job manager, resource manager, placement engine, and host manager. The interactions among those daemons are designed so that the dependencies are minimized and only occur in one direction. All four daemons depend on Apache Zookeeper for service discovery and leader election.
Figure 4, below, shows the high-level architecture of Peloton built on top of Mesos, Zookeeper, and Cassandra:
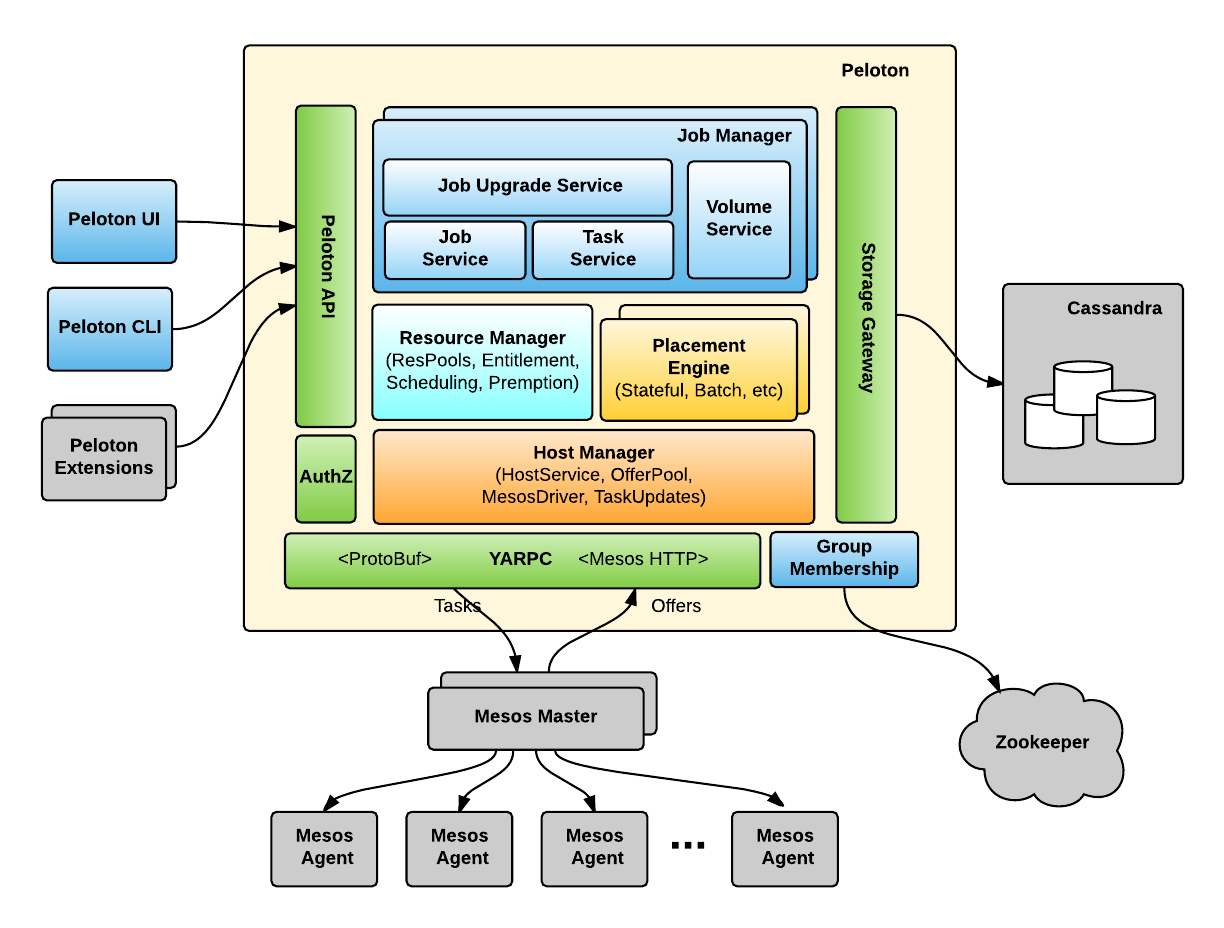
The Peloton architecture is made up of the following components:
- Peloton UI is a web-based UI for managing jobs, tasks, volumes, and resource pools in Peloton.
- Peloton CLI is a command-line interface for Peloton with similar functionality to the web-based interface.
- Peloton API uses Protocol Buffers as the interface definition language and YARPC as its RPC runtime. Peloton UI, Peloton CLI, and other Peloton extensions are all built on top of the same Peloton API.
- Host Manager abstracts away Mesos details from other Peloton components. It registers with Mesos via Mesos HTTP API.
- Resource Manager maintains the resource pool hierarchy and periodically calculates the resource entitlement of each resource pool, which is then used to schedule or preempt tasks correspondingly.
- Placement Engine finds the placement (i.e., task to host mapping) by taking into consideration the job and task constraints as well as host attributes. Placement engines could be pluggable for different job types such as stateful services and batch jobs.
- Job Manager handles the lifecycle of jobs, tasks, and volumes. It also supports rolling upgrades of tasks in a job for long-running services.
- Storage Gateway provides an abstraction layer on top of different storage backends so that we can migrate from one storage backend to another without significant change in Peloton itself. We have a default backend for Cassandra built-in, but can extend it to other backends.
- Group Membership manages the set of Peloton master instances and elects a leader to both register to Mesos as a framework and instantiate a resource manager.
All four Peloton daemons have high availability guarantees with either active-active instances or leader-follower topology. Peloton guarantees that all tasks are executed at least once, even after any application instance fails. For stateless Peloton daemons like Job Manager and Placement Engine, any instance failure can be tolerated by its built-in retry mechanism.
The scalability of Peloton has a few dimensions, including the size of the cluster in number of hosts, the number of running jobs and tasks, and the maximum throughput of scheduling decisions and launching tasks. Peloton aims to support large-scale batch jobs, e.g., millions of active tasks, 50,000 hosts, and 1,000 tasks per second. Both Job Manager and Placement Engine can be scaled out by adding more instances. All the API requests to Job Manager will be handled by the storage backend, making the scalability of the storage backend critical to Peloton. The Peloton resource manager has a single leader but it should scale to millions of tasks, since these tasks are minimal, only having resource configuration and task constraints. Also, all the tasks in the resource manager are in memory, so it should be able to handle high throughput of task enqueue and dequeue.
Mesos is known to scale to about 45,000 hosts when running about 200,000 long-running tasks that have a very low churn rate. However, when we scale to larger cluster sizes, for instance, 50,000 hosts and highly dynamic batch jobs, Mesos might become a bottleneck due to the centralized design of its master and single event channel.
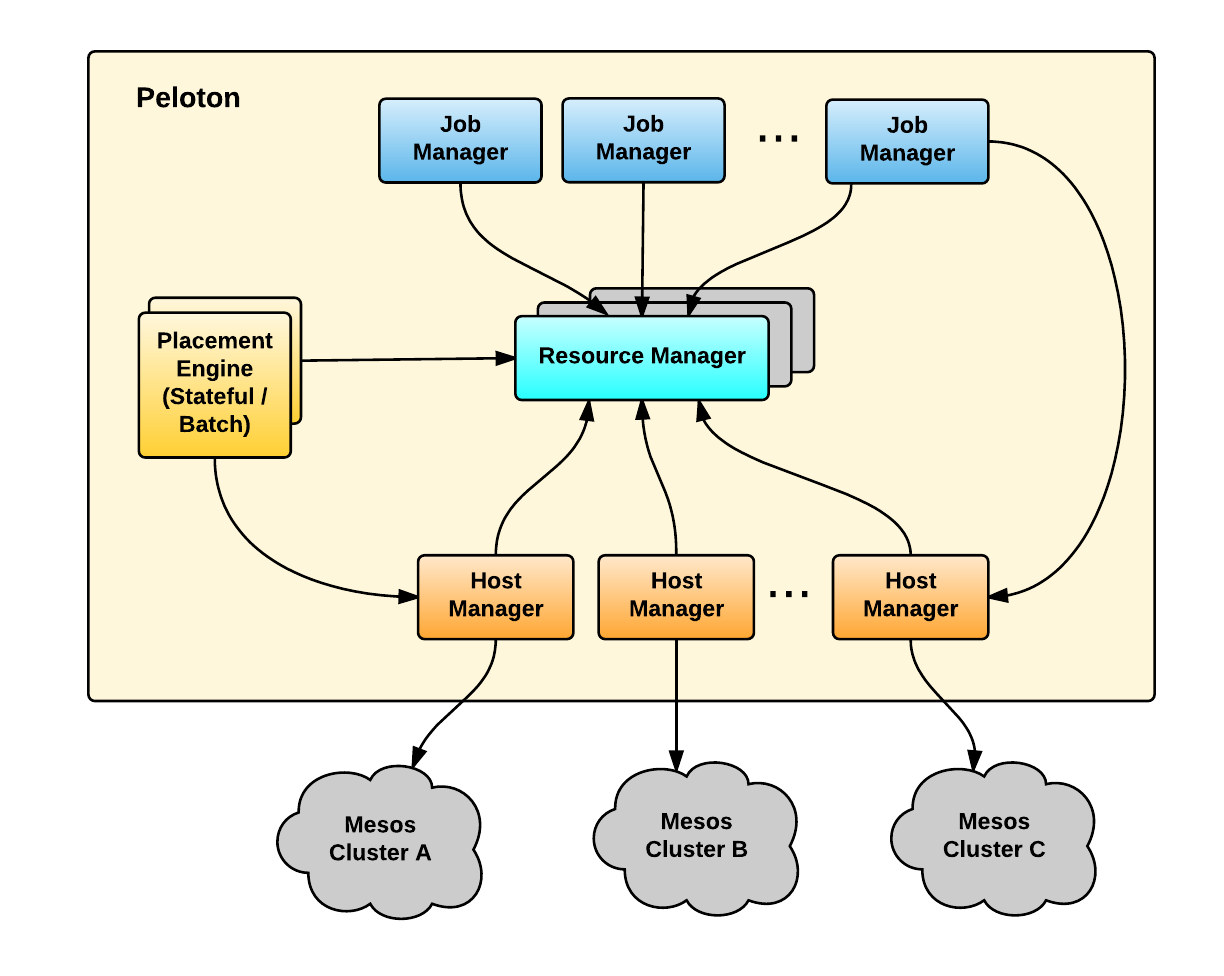
In Peloton, Mesos is an aggregator for all hosts, allowing the system to manage resources from multiple Mesos clusters. Therefore, Peloton can be scaled up by managing multiple Mesos clusters which are well-sized for our workload profile. For Peloton to manage multiple Mesos clusters , it can have a set of host managers for each Mesos cluster. Figure 5, below, shows an example of scaling up Peloton by managing multiple Mesos clusters via sharded host managers:
Elastic resource management
Peloton’s resource model defines how all resources in a cluster are divided among different users and jobs, as well as how different users can share resources elastically. There are two prominent resource allocation mechanisms that have been used in large-scale production data centers: priority-based quota and hierarchical max-min fairness.
This model has been adopted by the Borg and Aurora cluster management systems. In this approach, resources are divided into two priority-based quotas: production and non-production. Total capacity of production quota can not be more than the total capacity of a cluster. However, non-production quota is not guaranteed in the face of cluster-wide resource contention.
With Peloton, we use hierarchical max-min fairness for resource management, which is elastic in nature. Max-min fairness is one of the most widely used resource allocation mechanisms for cluster management because of its generality and performance isolation capabilities. Many current cluster schedulers such as YARN, VMware DRS, and DRF provide max-min fairness.
By using this approach at Uber, as shown in Figure 6, below, all resources in a cluster are divided into different organizations and then further subdivided into different teams within that organization:
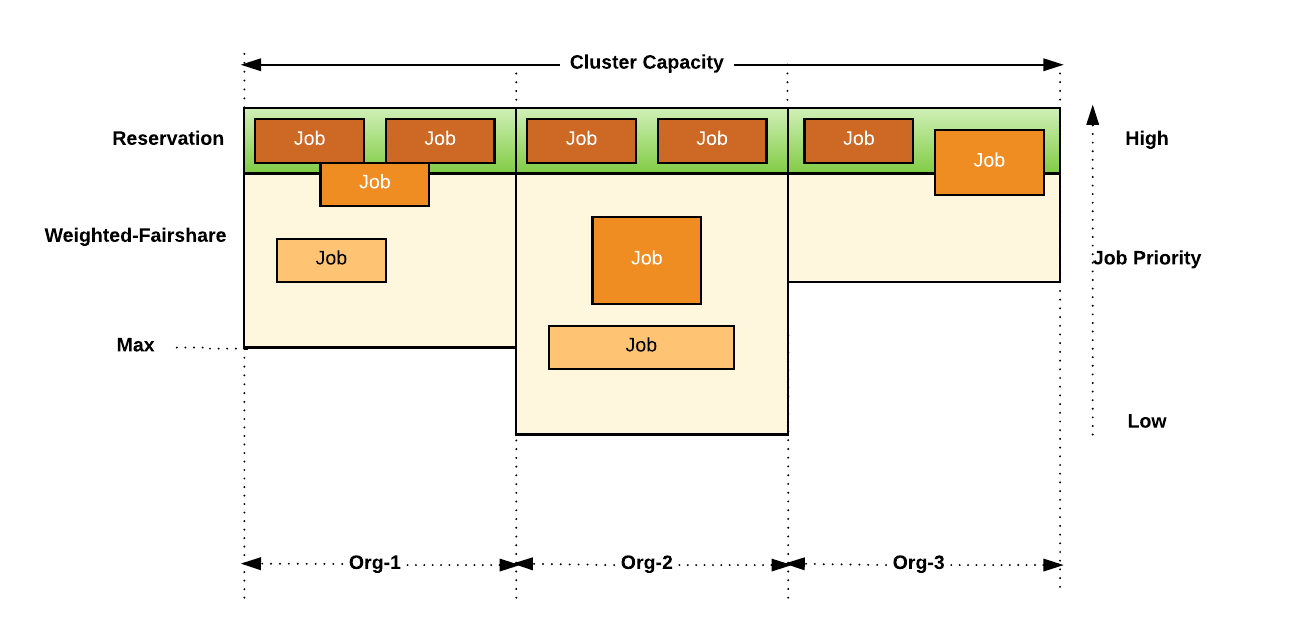
Each organization has a fixed guarantee of resources, and job priority is enforced within that organizational boundary. For example, if an organization does not have high priority jobs, it will be given a guarantee of the resources for other jobs with relatively lower priority. This model works very well with future chargeback, and gives more flexibility to each organization to define their workloads within their resource boundaries.
Resource pools
A resource pool in Peloton is a logical abstraction for a subset of resources in a cluster. All resources in a cluster can be divided into hierarchical resource pools based on organizations and teams. A resource pool can contain hierarchical child resource pools to further divide the resources within an organization. Resource sharing among pools is elastic in nature—resource pools with high demand can borrow resources from other pools if they are not using those resources.
Every resource pool has different resource dimensions, such as those for CPUs, memory, disk size, and GPUs. We expect the number of resource dimensions to increase in the future should Mesos support more types of resource isolation, such as Disk IO.
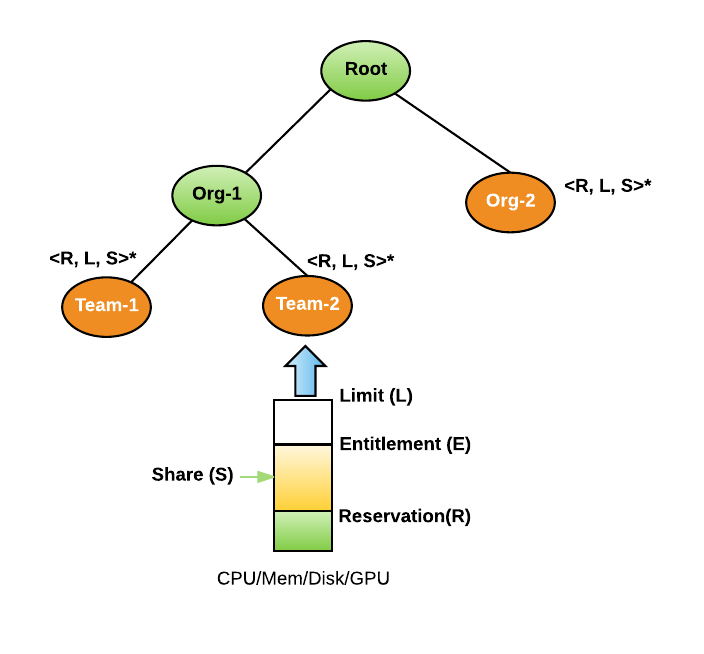
As shown in Figure 7, below, we outline four basic resource controls for each resource dimension in a Peloton resource pool:
- Reservation is the minimal guarantee of resources for a resource pool. Cumulative resource reservation across all pools cannot be greater than a cluster’s capacity.
- Limit is the maximum number of resources a resource pool can consume at any given time. Every resource pool can expand more than its reservation to this limit if the cluster has free capacity.
- Share is the relative weight a resource pool is entitled to allocate when there is free capacity in the cluster.
- Entitlement defines the resources a resource pool can use at that time. This control changes every moment based on workloads in resource pools or cluster.
In Figure 8, below, graphs demonstrate how Peloton’s elastic resource sharing borrows resources from one resource pool to fulfill the demands of another in production at Uber:
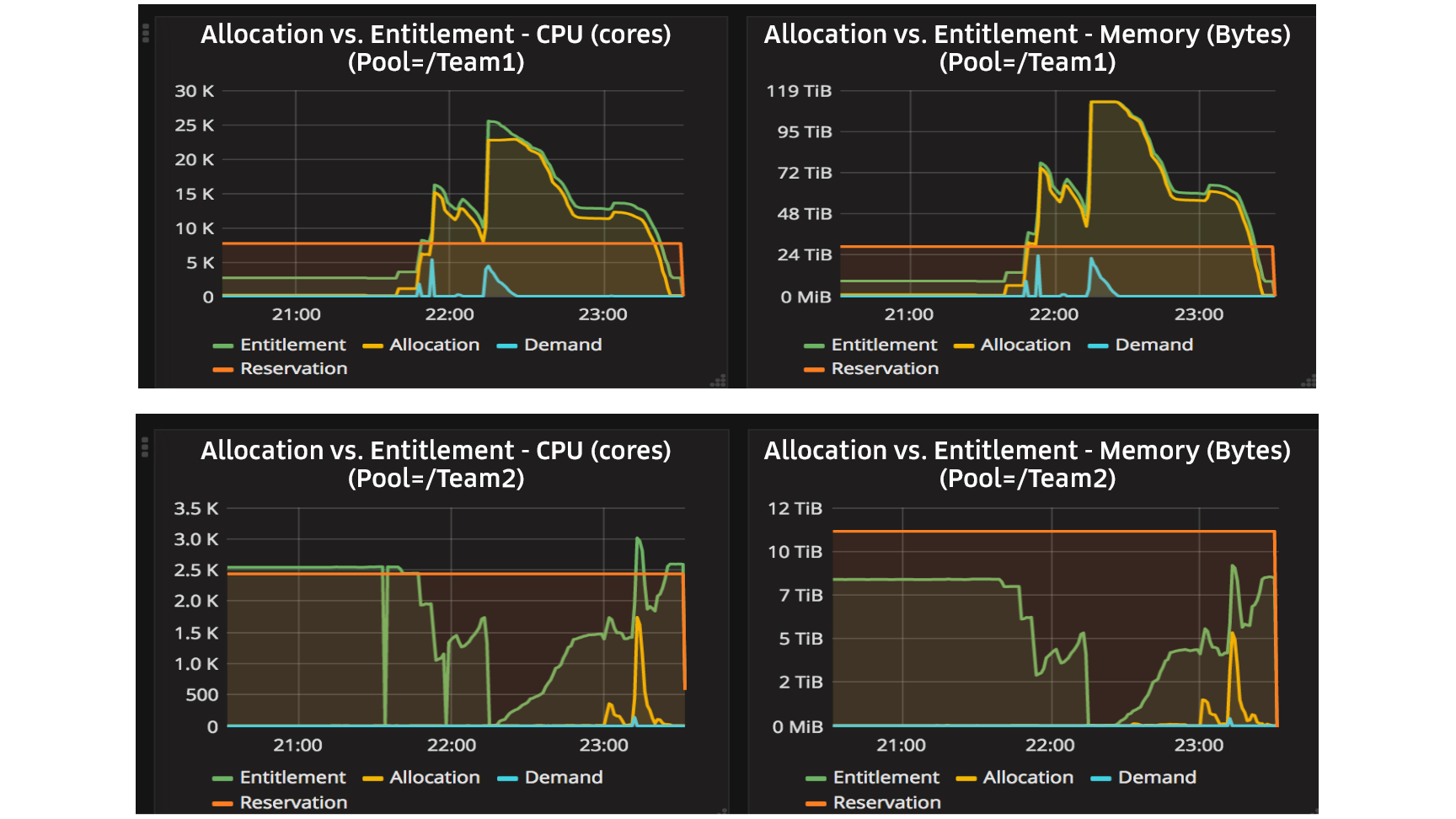
There are two graphs for two resource pools at Uber. As depicted in Figure 8, above, when Team 1 resource pool demand increases for a given service or increase in number of batch jobs, resources are borrowed from the other team’s resource pools. In these situations, the allocation for Team 1 increases beyond its promised reservation (guaranteed capacity); however, when demand increases in the other resource pool, the resources return to their original pool. This can be achieved by preemption which is explained in the section below.
Resource pool preemption
Elastic resource pool hierarchies let us share resources between different organizations. Every organization has their own designated resources and resource pools which they can lend to other organizations at times when their resources are being underutilized.
However, sharing resources comes with the cost of not being able to retrieve the resources when the lender needs them. Often, schedulers leverage static quotas for stricter SLA guarantees, as is the case with Kubernetes and Aurora. At Uber, we chose to share resources between teams and achieve stricter SLA by enabling preemption in Peloton. In Peloton, preemption lets us take back resources from entities which are using more than their assigned allotment, giving them back to the original lender for their compute needs.
Peloton uses two types of preemptions:
- Inter-resource pool preemption: This mechanism enforces max-min fairness across all resource pools. It applies preemption policies on the resources and claims back resources from the resource pools. The administrator of the pool can plug in different preemption policies.
- Intra-resource pool preemption: This type of preemption enforces resource sharing within a resource pool based on job priorities. Each resource pool can have many users, with each user running many jobs. If one user takes up the full capacity of the resource pool, other users may have to wait for those jobs to finish before they can run their jobs. This will lead to a missed SLA for the jobs which are stuck in the pool. In another scenario, lower priority jobs are running and a higher priority job comes in, requiring the scheduler to make space for the higher priority jobs. Intra-resource pool preemption preempts the lower priority tasks within a resource pool if there is resource contention.
Peloton use cases at Uber
Peloton has been running batch workloads in production since September 2017 on clusters comprised of over 8,000 machines across different availability zones. Each month, these clusters run three million jobs and 36 million containers.
Peloton’s workloads address multiple use cases across Uber, covering everything from our day-to-day ridesharing business to our most advanced projects, such as autonomous vehicle development.
Apache Spark
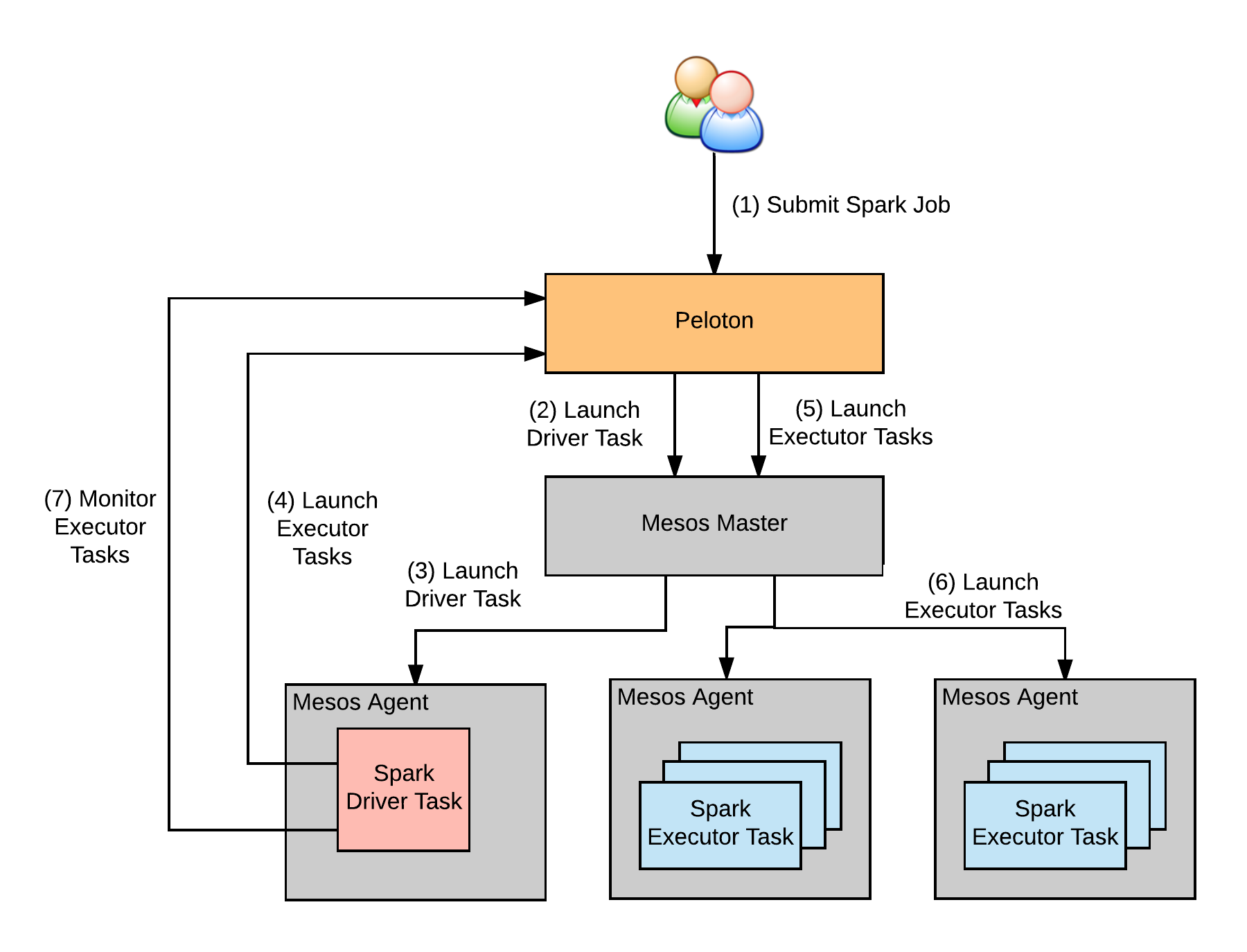
Peloton has its own Apache Spark driver, similar to those used for YARN, Mesos, and Kubernetes. The Spark driver runs as a controller job in Peloton, which adds and removes executors to the same job. Spark’s shuffle service runs as a container on all the hosts. At Uber, we run millions of Spark jobs in production every month, using Peloton as a resource scheduler, improving the efficiency for all the jobs related to maps, marketplace, and data analytics.
TensorFlow
Peloton supports distributed TensorFlow, gang scheduling, and Horovod, Uber’s distributed TensorFlow, Keras, and PyTorch framework. Peloton lets these frameworks collocate CPUs and GPUs on the same cluster and schedule mixed workloads. For this project, Peloton runs very large clusters of more than 4,000 GPUs and schedules deep learning jobs.
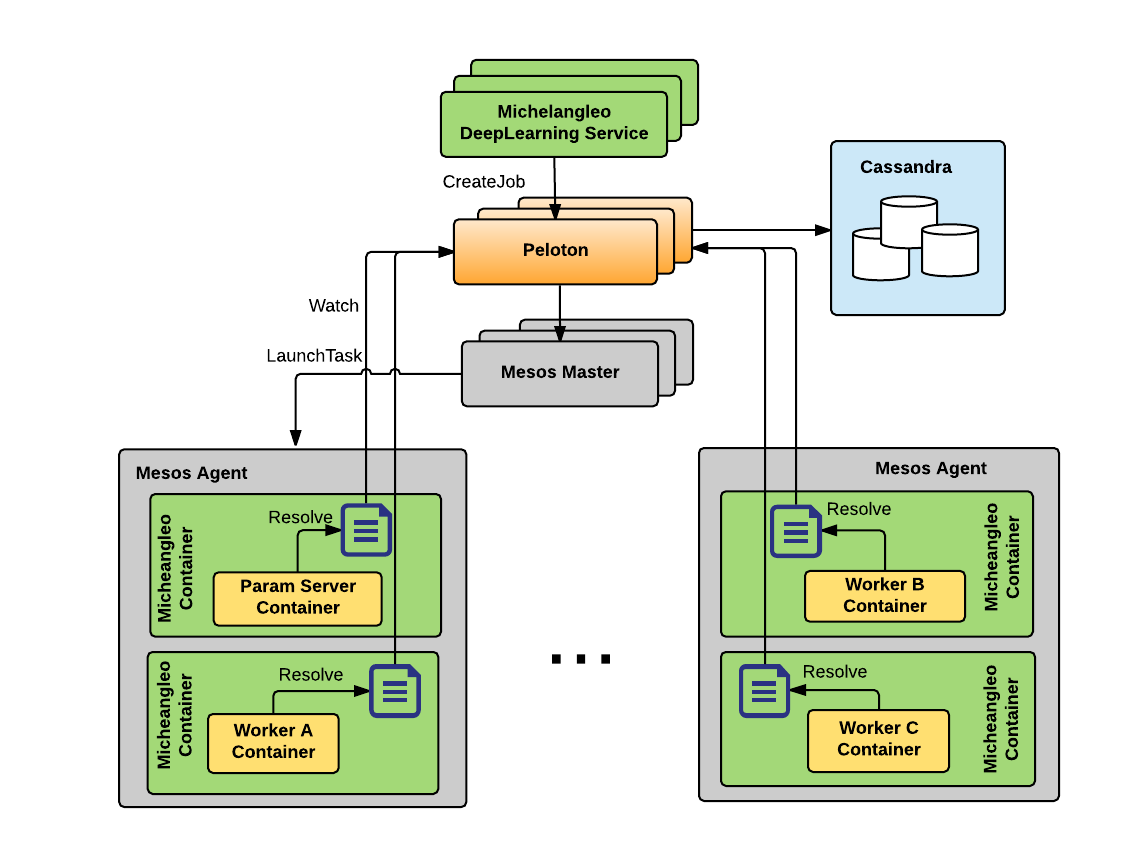
Figure 10, above, shows how a distributed TensorFlow job is launched on Peloton by using a gang scheduling preemptive, letting it schedule all the tasks at the same time while providing a way for them to discover each other.
We re-ran the official TensorFlow benchmarks modified to use Horovod and compared the performance with regular distributed TensorFlow. As depicted in Figure 11, below, we observed large improvements in our ability to scale on Peloton. We were no longer wasting half of the GPU resources—in fact, scaling using both Inception V3 and ResNet-101 models achieved an 88 percent efficiency mark. In other words, model training was about twice as fast as standard distributed TensorFlow because of Peloton.
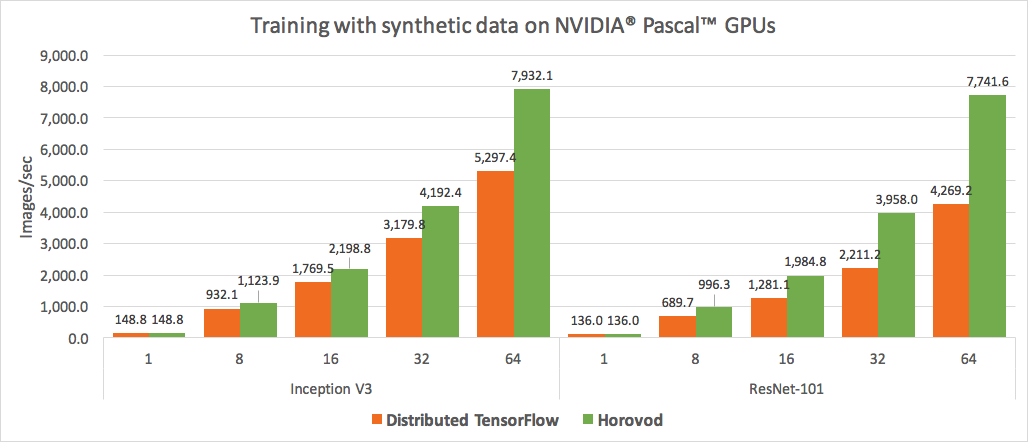
Figure 11: As we increase the number of NVIDIA Pascal GPUs, Peloton shows how it becomes more efficient when running TensorFlow modified to use Horovod versus standard distributed TensorFlow, both for Inception V3 and ResNet-101 TensorFlow models.
Autonomous vehicle workloads
Our in-house scheduler ran very large batch jobs of 100,000 tasks. Before Peloton, Uber Advanced Technologies Group (ATG), our team responsible for developing self-driving vehicle systems, ran all its batch workloads on the scheduler, with many small clusters for tasks. Peloton consolidated all these small clusters into one big cluster with about 3,000 hosts, and unified the processing for all the scheduler workloads from different teams.
Maps
Peloton runs large batch workloads, such as Spark and distributed TensorFlow, for Uber’s Maps team. Peloton powers all these workloads across multiple clusters and millions of containers. The Maps team’s workloads have very specific needs for preemption and hierarchical resource sharing, as well as collocation of GPUs and CPUs on the same cluster.
Marketplace
Uber’s Marketplace team runs the platform that matches drivers with riders for our ridesharing business and determines dynamic pricing. This team uses Peloton to run its pricing workloads, which are primarily Spark jobs, facilitating low latency and faster cluster throughput.
Next steps
In the coming months, we plan to build Peloton support for other workloads, such as stateless and stateful. We are also working on a control plane, which will be used to deploy and orchestrate Peloton on Mesos, a process that is now performed using deployment scripts.
We are also planning to migrate Mesos workloads to Kubernetes using Peloton, which would help Peloton adoption in the major cloud services, as Kubernetes already enjoys extensive support in that realm. Peloton already shares many common design patterns with Kubernetes in its API, as well as ability to conform with higher scalability requirements. The current design of Peloton has very few dependencies on Mesos except for the Mesos agent, and Kubelet could work as an agent in Peloton. In this approach, we can model Peloton as a more scalable core implementation of Kubernetes:
- Provide a Kubernetes compatible API on top of Peloton’s core API.
- Add a new Peloton host manager implementation which supports Kubelets.
- Existing systems, such as Michelangelo, Uber’s machine learning platform, can still use the native Peloton core API.
If you are interested in building large-scale infrastructure, consider applying for a role on our team!
Subscribe to our newsletter to keep up with the latest innovations from Uber Engineering.
* Apache Hadoop, Cassandra, Spark, and Kafka logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks. TensorFlow and the TensorFlow logo are trademarks of Google Inc. Redis is a trademark of Redis Labs Ltd. Any rights therein are reserved to Redis Labs Ltd. Any use by Uber Technologies is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Uber Technologies.
Min Cai is a senior staff engineer on the Compute Platform team at Uber, working on active-active data centers and cluster management. Before joining Uber, he was a senior staff engineer at VMware working on live VM migration (vMotion) and virtual infrastructure management (vCenter). He has published over 20 journal and conference papers, and holds six US patents.
Mayank Bansal is currently working as a staff engineer on Uber’s Compute Infrastructure team. Prior to that he was working towards scaling Uber’s data infrastructure. He is an Apache Hadoop committer and on the project management committee and a committer for Apache Oozie.

Mayank Bansal
Mayank Bansal is a staff engineer on Uber's Big Data team.
Posted by Leslie Williams, Mayank Bansal
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global
Most popular

Scaling AI/ML Infrastructure at Uber

Information for driving during the week of Super Bowl LVIII

Uber Reveals 2023 “Airport of the Year” Award Winners

DataCentral: Uber’s Big Data Observability and Chargeback Platform
Products
Company
