Productionizing Distributed XGBoost to Train Deep Tree Models with Large Data Sets at Uber
December 10, 2019 / Global
Michelangelo, Uber’s machine learning (ML) platform, powers machine learning model training across various use cases at Uber, such as forecasting rider demand, fraud detection, food discovery and recommendation for Uber Eats, and improving the accuracy of estimated times of arrival (ETAs).
As Michelangelo’s increasingly deep tree models create larger data sets, the efficient training of distributed gradient boosting (GBD) algorithms becomes evermore challenging. To prevent training latencies at Uber, we leverage Apache Spark MLlib and distributed XGBoost‘s efficient all-reduce based implementation to facilitate more efficient and scalable parallel tree construction and out-of-core computation on large data sets.
In this article, we share some of the technical challenges and lessons learned while productionizing and scaling XGBoost to train deep (depth 16+) model trees using over billions of records in Uber’s datastore. By using XGBoost to stratify deep tree sampling on large training data sets, we made significant gains in model performance across multiple use cases on our platform including ETA estimation, leading to improvements in the user experience overall.
Using Apache Spark with XGBoost for ML at Uber
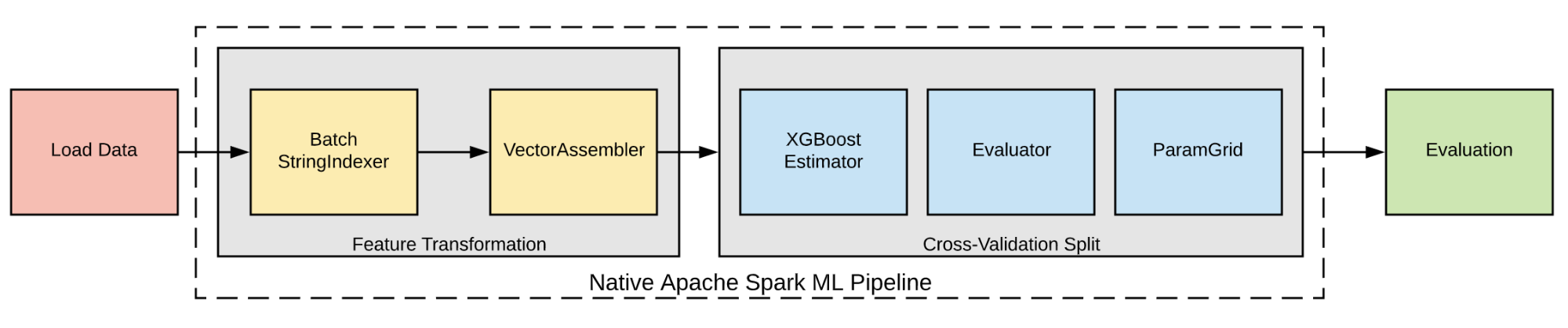
A typical XGBoost training workflow consists of two phases that clean and process raw data for use during ML model evaluation. Figure 1, above, shows a typical XGBoost training workflow, split into the Feature Transformation and Cross-Validation Split phases.
During the Feature Transformation stage, we typically perform one-hot encoding or use our internal implementation of batch StringIndexer to convert categorical columns into indexed columns before a sequence of feature transformations and imputation stages. The transformed features are then passed to the XGBoost trainer. The evaluation framework loads the generated XGBoost model and features to compute feature importance and customized model performance metrics specified by the user.
Michelangelo, Uber’s ML platform, trains and persists models using Spark ML pipeline representation in production training and serving. This representation includes support for estimators and transformers for XGBoost. Michelangelo supports the ability to serve models trained with various versions of XGBoost, including versions 0.6 through 0.9.
We tuned Spark MLlib SerDe for low-latency model loads, extended Spark Transformers for online serving APIs, and created custom Estimators and Transformers to load and serve XGBoost models online at high query per second (QPS). This marriage of low latency-high QPS support satisfies a core requirement for productionizing XGBoost models and leads to faster model assessment. These changes are available to the open source community via the Apache Spark JIRA request, SPIP – ML Model Extension for no-Spark MLLib Online Serving.
When productionizing XGBoost for large-scale systems, there are several factors to consider. Through our own experiences with Michelangelo, we identified some general best practices that other teams might find useful when working with XGBoost at scale:
Ensure SparseVector and DenseVector are used consistently
In Apache Spark, there are two kinds of vector storage structures:
- SparseVector is a sparse representation which only retains the nonzero elements and ignores all zero elements. SparseVector is applicable to many ML use cases whereby the dataset contains a high proportion of zero elements.
- DenseVector representation stores each value in the vector sequentially, as illustrated below in Figure 2:

Zero values in SparseVectors are treated by XGBoost on Apache Spark as missing values (defaults to Float.NaN) whereas zeroes in DenseVectors are simply treated as zeros. Vector storage in Apache Spark ML is implicitly optimized, so a vector array is stored as a SparseVector or DenseVector based on space efficiency. If an ML practitioner tries to feed a DenseVector at inference time to a model that is trained on SparseVector or vice versa, XGBoost does not provide any warning and the prediction input will likely go into unexpected branches due to the way zeroes are stored, resulting in inconsistent predictions. Hence, it is critical that the storage structure input remains consistent between serving and training times.
Measure model feature importance

Java Virtual Machine (JVM)-based XGBoost version 0.81 and older iterations of the software computes the feature importance (in other words, relative influence) for a particular feature so far as it affects the overall model performance based on the frequency that is proportional to the total number of splits across all trees on the corresponding feature. This calculation is unreliable if there are distinctly strong and weak features. The model will exploit the stronger features in the first few boosting steps, and then the weaker features to improve on the residuals, hence inflating the importance of some of the weaker features.
A workaround to prevent inflating weaker features is to serialize the model and reload it using Python or R-based XGBoost packages, thus allowing users to utilize other feature importance calculation methods such as information gain (the mean reduction in impurity when using a feature for splitting) and coverage (the mean number of samples affected by splits on a feature across all trees). Note that these methods based on information gain and cover are also available in JVM-based XGBoost version 0.82 and greater. However, these methods are still biased as they have the tendency to overestimate the importance of continuous variables or categorical variables with high-cardinality.²
Purely random or white noise variables can empirically beat more important variables based on these methods as they have more potential to create splits even though they are spurious. Furthermore, these methods only provide an estimate of the average effect across all samples without accounting for conditional effects on individual cases. Other recent model-agnostic techniques such as shapley additive explanations (SHAP) ³, can be explored to help address some of these limitations.
Meet requirements for custom objective functions and evaluations
There are requirements for leveraging custom objectives and evaluations in XGBoost. In order to greedily search through and recompute the loss efficiently for every candidate split for large data sets, XGBoost employs Newton boosting, which relies on performing a second-order Taylor expansion to approximate the loss function, and chooses to split on features that optimize the approximate loss. Newton boosting imposes restrictions on the objective to be twice Gateaux differentiable to guarantee that the second-order approximation of our loss is reasonable, i.e., the local curvature of the loss contains some information about the location of its optimas. For loss functions in which the elements of the Hessian matrix are all zero on a non-null set of the support of the feature space, Newton boosting will not be accurate.
An example of a function where the Hessian equals zero is the quantile regression loss equation, depicted below:
![]()
where![]() is the target quantile. It has well-defined derivatives almost everywhere:
is the target quantile. It has well-defined derivatives almost everywhere:
-
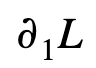 is either
is either 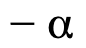 or
or 
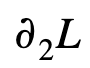 is 0 for all
is 0 for all
- At
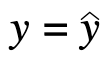 , both
, both 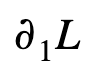 and
and  are undefined
are undefined
If we calculate the gain in splitting a set of samples A into two separate partitions B and C by approximating the loss using second-order approximation, we will notice it is purely a function of the pointwise gradient and Hessian of the loss:

where ![]() is the approximate loss for some samples D and
is the approximate loss for some samples D and ![]() is the sum of the base learners.
is the sum of the base learners.
Calculating the approximate gain can be problematic under certain situations such as determining the splits for quantile regression loss. This is because when the estimated quantile value is far from the observed values within the partition, with both gradient and Hessian being constant for large residuals, it is difficult for the gain achieved by splitting into separate partitions to be high enough for any split to occur. Considering that XGBoost’s feature importance calculation relies on the frequency of splits on a particular feature, a common symptom of no splits due to low gain is zero feature importance scores for all features.
Some possible workarounds include using approximations of the target loss function if available, e.g., pseudo-Huber or log-cosh loss to approximate Huber loss or Mean Absolute Error (MAE), or setting elements of the Hessian to be a fixed constant so that it will be conducting first-order approximation, a function similar to gradient descent without the need for second-order approximation. Note that if the gradient is piecewise constant, it also risks the issue of low gain at large residuals. In these instances, it is often useful to add a scaling factor to a Hessian term to encourage splitting.
Decouple heap and off-heap memory requirements
XGBoost’s repartitioning stage mostly relies on heap memory, i.e. executor memory, but distributed training triggered using the Java Native Interface requires off-heap memory. Off-heap memory can be adjusted by tuning the spark.executor.memoryOverhead setting in Apache Spark. As such, there are different Apache Spark requirements for the XGBoost training stage as compared to the rest of the training workflow. Decoupling XGBoost training and the rest of the stages with the ability to tune Apache Spark settings provides the flexibility required for a variety of training use cases.
XGBoost results on Michelangelo
Many teams at Uber choose XGBoost for the tree algorithm when training against large volumes of data in Michelangelo.
Best practices
Our experience scaling XGBoost for training larger models with Michelangelo surfaced several best practices related to effectively productionizing distributed XGBoost that we intend to carry into future iterations of this work:
Leverage golden data sets and a baseline model for measuring model performance
It is important to have golden data sets (that has a good coverage of different data configurations e.g. high cardinality, wide features, less seen categorical features) and baseline models that can be utilized as benchmarks in performance across various stages of the workflow. This is used during integration tests before each change is pushed to production as well as upgrading Apache Spark and XGBoost versions to ensure there is no regression in both training and serving performance. When measuring the efficacy of our real-time prediction service, we compared prediction scores generated using sample input data to ensure any given model is generating the same prediction value for each sample data point against both the old and new versions of Apache Spark and XGBoost. We also measure the overall model loading time and latency to make sure there was no regression introduced between versions.
Separate pre-training and post-training stages from XGBoost training
Before calling the XGBoost trainer, the Michelangelo training workflow goes through several stages including data joining with features fetched from the system’s FeatureStore, a train-validation-test data split, and feature distribution computation. Each stage has different requirements, so we found it desirable to decouple these stages into tasks (referred to as Apache Spark applications) with the ability to inject their own custom Apache Spark settings, as depicted in Figure 4, below:
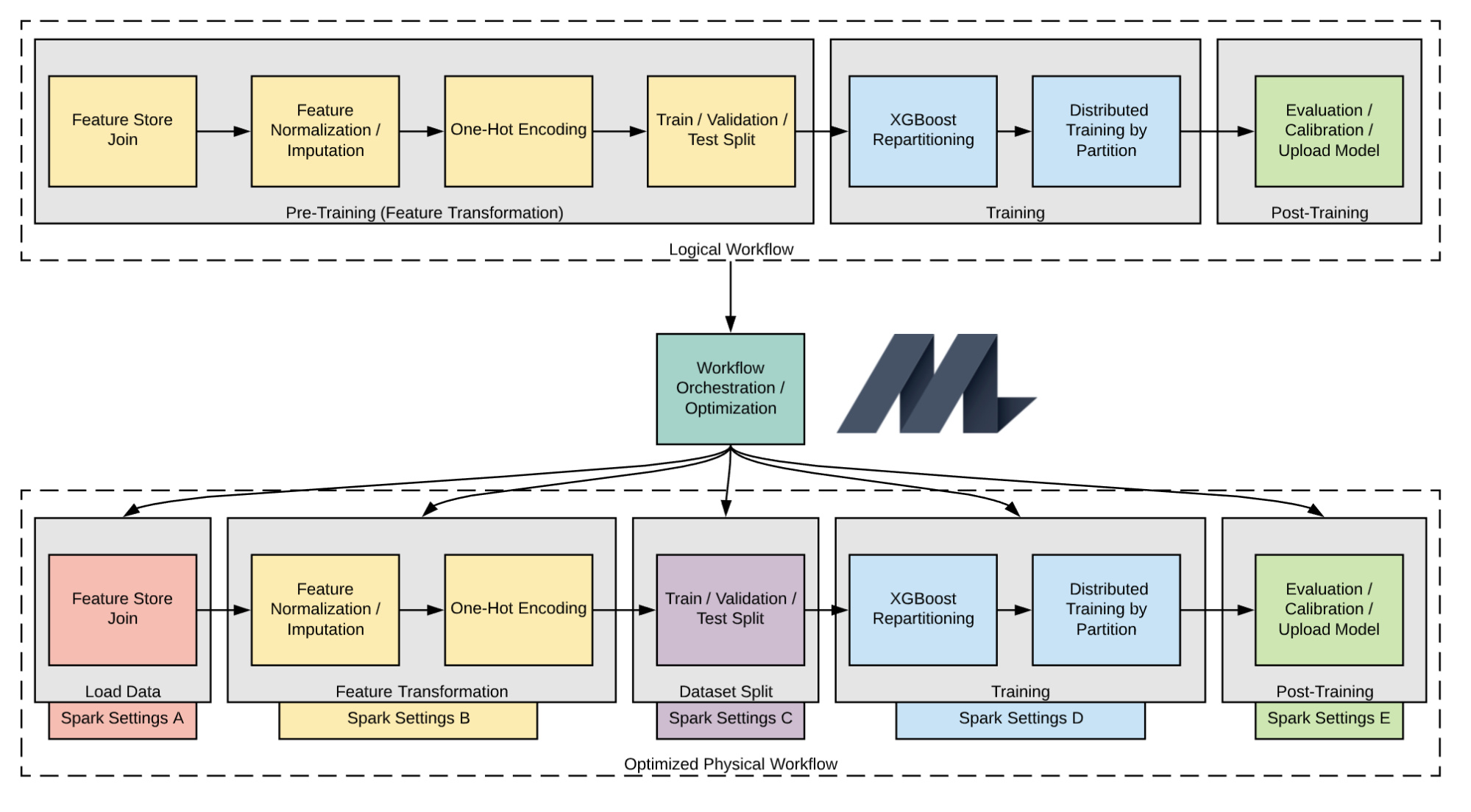
Michelangelo’s internal workflow orchestration service generates an optimized physical execution plan that breaks the respective stages into separate Apache Spark applications with its own settings based on different requirements. To streamline the ML model development process, we engineered Michelangelo to provide default tuning settings for Apache Spark and XGBoost. However, there are cases for which we need to change Apache Spark or XGBoost settings to accommodate the tuning needs of larger data sets and/or more complex models.
As part of Michelangelo’s workflow system, we have the option to checkpoint metadata and intermediate data produced during each workflow stage to HDFS. We found it desirable to always have transformed features serialized to HDFS, easing debuggability and retries without the need to go through pre-training transformation steps which tend to be much more resource and time-intensive compared to the XGBoost distributed training stage.
Stay informed of new features and existing bugs
One of the issues we encountered while building our XGBoost solution for Michelangelo was that Apache Spark sessions were never cleaned up at the end of a training job. In XGBoost version 0.8 and greater, there is a conservative logic once we enter XGBoost such that any failed task would register a SparkListener to shut down the SparkContext.
However, Apache Spark version 2.3.2 was not able to handle exceptions from a SparkListener correctly, resulting in a lock on the SparkContext. As such, when the entire job finished and a SparkContext.stop is invoked, the job is not able to secure and stop the SparkContext correctly, resulting in a lingering Apache Spark Session that could not be shut down correctly.
Fortunately, this issue was fixed in XGBoost version 0.91 and greater with the following features:
-
- SparkContext is stopped explicitly instead of relying on an exception surfaced via SparkListener.
- The conservative check in the repartitioning stage is removed so that it tolerates failed tasks with retries. You can eliminate days of combing through logs from various infrastructure layers to identify the root cause by staying informed of new features and existing bugs, as communicated through version updates.
Factor in memory requirements during model training phase
Out-of-memory and segmentation faults are the two most common issues that we encountered during model training with XGBoost. Since each step of the training workflow has different memory resource requirements, it’s wise to ensure that a user’s architecture has accounted for these. For example, during the FeatureStore join step of our XGBoost training workflow, a lot of data shuffling happens, which results in a data spill to the disk. During the actual XGBoost training phase, the spill ratio will be different. We found that during the model fitting phase, we can eliminate segmentation fault issues in XGBoost by providing a sufficient number of executors with large container memory and disabling external memory usage.
Push platform limitations and provide guidelines
It is important to push your ML platform to its limits in terms of the depth and number of GBD trees against the volume of data that can reliably be trained on it. To optimize our models for the most possible use cases, we tracked their accuracy and overall training time under various resource constraints, such as the number of executors and their container memory limit. Moreover, this robust testing helps set proper expectations for platform users and enables us to accurately handle capacity planning.
Automate model retraining
For many problems, we have city/region specific models and a global model. Retraining these models at regular cadence requires the platform to support dynamic date range and filtering logic and tooling to automate data validation, training, model performance check, and model deployment. In our case, we leverage Michelangelo ML Explorer (MLE), an internal tool for ML workflow creation, and Uber’s automated data workflow management system. Without tooling, it would be challenging to manage model life cycle for thousands of use cases.
Next steps
In future iterations of our XGBoost training workflow for Michelangelo, we intend to speed up training, reduce memory footprint, improve model interpretability, and further tune Apache Spark settings to consider more advanced ML training use cases. In turn, these updates will further enable Michelangelo to generate valuable insights for users at scale.
If working with XGBoost, Apache Spark, and other Big Data technologies to develop ML model training workflows at scale interests you, consider applying for a role on our team!
Acknowledgements
We could not have accomplished the technical work outlined in this article without the help of our team of engineers and data scientists at Uber. Special thanks to Felix Cheung, Nan Zhu, Jeffrey Zhong, Tracy Liu, Min Cai, Mayank Bansal, Olcay Cirit, Cen Guo, Armelle Patault, Bozhena Bidyuk, Anurag Gupta, Michael Mallory, Jyothi Narayana, Sally Lee, Anupriya Mouleesha, Smitha Shyam, and the entire Michelangelo team for their support.
Header image logo attributions: Apache Spark is a registered trademark of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of this mark.
References
-
- Chen, Tianqi, and Carlos Guestrin. “XGBoost: A scalable tree boosting system.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining – KDD ’16 (2016)
- Strobl, C., Boulesteix, AL., Zeileis, A. et al. “Bias in random forest variable importance measures.” BMC Bioinformatics (2007)
- Lundberg, Scott, and Lee, Su-in. “A unified approach to interpreting model predictions.” Proceedings of the 30th Neural Information Processing Systems – NIPS ‘17 (2017)
- XGBoost Documentation

Joseph Wang
Joseph Wang serves as a Principal Software Engineer on the AI Platform team at Uber, based in San Francisco. His notable achievements encompass designing the Feature Store, expanding the capacity of the real-time prediction service, developing a robust model platform, and improving the performance of key models. Presently, Wang is focusing his expertise on advancing the domain of generative AI.

Anne Holler
Anne Holler is a former staff TLM for machine learning framework on Uber's Machine Learning Platform team. She was based in Sunnyvale, CA. She worked on ML model representation and management, along with training and offline serving reliability, scalability, and tuning.

Mingshi Wang
Mingshi Wang is a senior software engineer on Uber's Machine Learning Platform team.

Michael Mui
Michael Mui is a Staff Software Engineer on Uber AI's Machine Learning Platform team. He works on the distributed training infrastructure, hyperparameter optimization, model representation, and evaluation. He also co-leads Uber’s internal ML Education initiatives.
Posted by Joseph Wang, Anne Holler, Mingshi Wang, Michael Mui
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global



Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
