Controlling Text Generation with Plug and Play Language Models
December 5, 2019 / Global
This article is based on the paper “Plug and Play Language Models: A Simple Approach To Controlled Text Generation” by Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu.
The transformer neural network architecture, developed by Vaswani et al. (2017), has enabled larger models and momentous progress in natural language processing (NLP) over the last two years. At Uber, we invest heavily in advancing NLP technologies and platforms to improve interactions with our customers with faster and more satisfactory support.
Recent findings from the scientific community show that training language models (LMs) on large, unannotated corpora and with a simple objective—to predict the next word in a passage of text given the preceding text—can demonstrate unprecedented fluency. LMs can generate coherent, relatable text, either from scratch or by completing a passage started by the user.
For example, prompted with the prefix The food is awful, an LM may generate a plausible completion of the sentence as follows (generated from a pre-trained GPT-2-medium model):
The food is awful. The staff are rude and lazy. The
food is disgusting – even by my standards.
Although these models are able to encode complex knowledge about spelling, grammar, and typical speech patterns, they are hard to steer or control. In other words, while we can ask them to generate many possible sentences or to complete a given sentence fragment, there is no easy way to get them to generate text with specific properties or about particular topics. For example, what if we wanted the generated text to start with the same prefix, The food is awful, but then to turn in a positive direction? Or gradually to change the topic of the generated text to being about politics?
To hint at what will come, the following is an example (generated by the model we describe in this article) in which we ask for a positive completion:
The food is awful, but there is also the music, the story and the magic!
The “Avenged Sevenfold” is a masterfully performed rock musical that
will have a strong presence all over the world.
The text switches from being negative to positive but is still fairly coherent. Researchers around the world have proposed multiple ways of conditioning text generation, including starting with a pre-trained LM and fine-tuning it to always produce positive sentences, training a large conditional model from scratch, or turning a given sentence into a more positive one by substituting new text in for key n-grams.
This article discusses an alternative approach to controlled text generation, titled the Plug and Play Language Model (PPLM), introduced in a recent paper from Uber AI. PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional LM. The method has the key property that it uses the LM as is—no training or fine-tuning is required—which enables researchers to leverage best-in-class LMs even if they do not have the extensive hardware required to train them.
We release code accompanying our paper, as well as an online demo of PPLM, developed in collaboration with Hugging Face (creators of Write With Transformer and the Transformers repository). We provide a dozen attribute models in the demo: try it out for yourself!
How to steer a mammoth

The largest, most capable language models are huge (e.g., over a billion parameters), require massive amounts of compute resources (e.g., $61,000 USD to train one model), and must be trained on enormous data sets which are often not publicly released even when the training code is available. In many ways, language models are like wise but unguided wooly mammoths that lumber wherever they please.
The result is that all but the best-equipped machine learning researchers and practitioners around the world must choose between three undesirable alternatives: using large, publicly available pretrained models (which may not perfectly suit their task), fine-tuning pretrained large models on smaller data sets (which may destroy their modeling ability via catastrophic forgetting), and training models far smaller than the state of the art as afforded by their budget.
Fortunately, Uber AI’s Plug and Play Language Model allows researchers to make use of the few pretrained models out there: rather than requiring everyone to train their own wooly mammoth, PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100,000 times smaller than the LM and still be effective in steering it, like a mouse sitting atop our wooly mammoth friend and telling it where to go (Figure 1).
The mouse tells the mammoth where to go using gradients. To understand how this process works, we’ll need a bit of math.
A bit of math
To understand how PPLM works, we first consider a few distributions and models.
First, there’s the unconditional LM p(x), a probability distribution over all text. This is the distribution modeled by unconditional LMs like GPT-2, our mammoth in Figure 1, above. It is general and can generate fluent text about a broad array of topics.
Second, there’s p(x|a), which is the conditional LM that we’d like to create. It’s a hypothetical model that can, given an attribute a, generate sentences with those attributes (like the positive sentiment example above).
Third, there’s an attribute model p(a|x), which takes a sentence x and outputs the probability that it possesses the attribute a. This model might judge a sentence as being 10 percent likely to have positive sentiment or of being 85 percent likely to be about politics. These models can be tiny and easy to train because, intuitively, recognizing positivity is easier than being positive and recognizing political speech is easier than writing it; this is particularly true when the recognition is learned atop representations provided by a pre-trained LM, as demonstrated in Radford et al. (2019). As we will show below, attribute models with only a single layer containing 4,000 parameters perform well at recognizing attributes and guiding generation.
Fortunately, using Bayes rule, we can write the second model in terms of the first and the third:
p(x|a) ∝ p(a|x) p(x).
While this allows us to easily evaluate probabilities (does this sentence look like what we expect a positive sentence to look like?), it is difficult to sample from. Trying the usual suspects — rejection sampling or importance sampling, say, using p(x) as a proposal — work in theory, but in practice would either be biased or would take forever. Such a process to generate a sentence about politics could loosely work like this: (Step 1) generate a sentence x from p(x), (Step 2) give it to p(a|x) to see if it’s about politics, (Step 3) if it’s not, go to (1). Unfortunately, it may take exponentially long to randomly generate a sentence about politics, because there are so many other topics to talk about, just as it would take eons for monkeys randomly typing to produce the works of Shakespeare, because there are just so many other pages that can be typed.
PPLM resolves this issue by approximately implementing the more efficient Metropolis-adjusted Langevin sampler of Roberts and Tweedie (1996) as implemented for pairs of neural networks by Nguyen et al. (2016) in their Plug-and-Play Generative Networks (PPGN) model. In this vein, the PPLM algorithm entails three simple steps to generate a sample:
-
- Given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models.
- Use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x)).
- Sample the next word.
Intuitively, as a PPLM generates text one token at a time, it continuously steers its representation of the text in a direction that will be more likely to possess the desired attribute—high log(p(a|x))—while still retaining fluency under the original language model—high log(p(x)).
As we demo PPLM, we’d like to note a few details. First, the PPLM control scheme is tunable: the strength of the updates may be increased or decreased, and in the limit of zero strength, the original LM is recovered. Second, PPLMs assume the base language model is autoregressive, which is the case for many modern LMs. In fact, if the LM is transformer-based, the above algorithm can be implemented efficiently because the future depends on the past only via the transformer’s past keys and values, not any of its other activations, so these are the only tensors that must be updated and carried forward each step. Third, there are some important differences between how the sampler is implemented in this research as opposed to the PPGNs of Nguyen et al. (2016) or the Metropolis-adjusted Langevin sampler in Roberts and Tweedie (1996); be sure to check out our full paper if you’re interested in that discussion. Lastly, in this research we focus on using the GPT-2 345M parameter model as the base LM, though any other autoregressive model may be substituted.
Visualizing PPLM sampling
The PPLM sampling algorithm described above entails forward and backward passes through a network consisting of two subnetworks — the base LM and the attribute model — and is depicted in Figure 2, below:
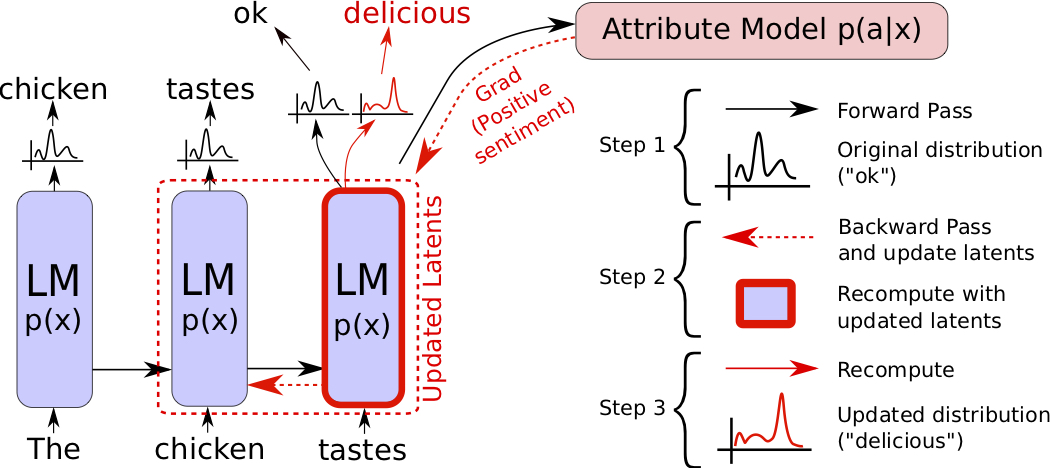
In Step 1, a forward pass is performed through the language model to compute the likelihood of the desired attribute using an attribute model that predicts p(a|x). In Step 2, a backward pass updates the internal latent representations of the LM based on gradients from the attribute model in order to increase the likelihood of the generated passage having the desired attribute. Following the latent update, in Step 3, a new distribution over the vocabulary is generated from the distribution resulting from updated latents, and a single token or word is sampled. This process is repeated at each time-step, with the LM latent variables representing the past (for transformers: the past keys and values) being repeatedly modified at each time step (see Section 3.2 from our paper for more details).
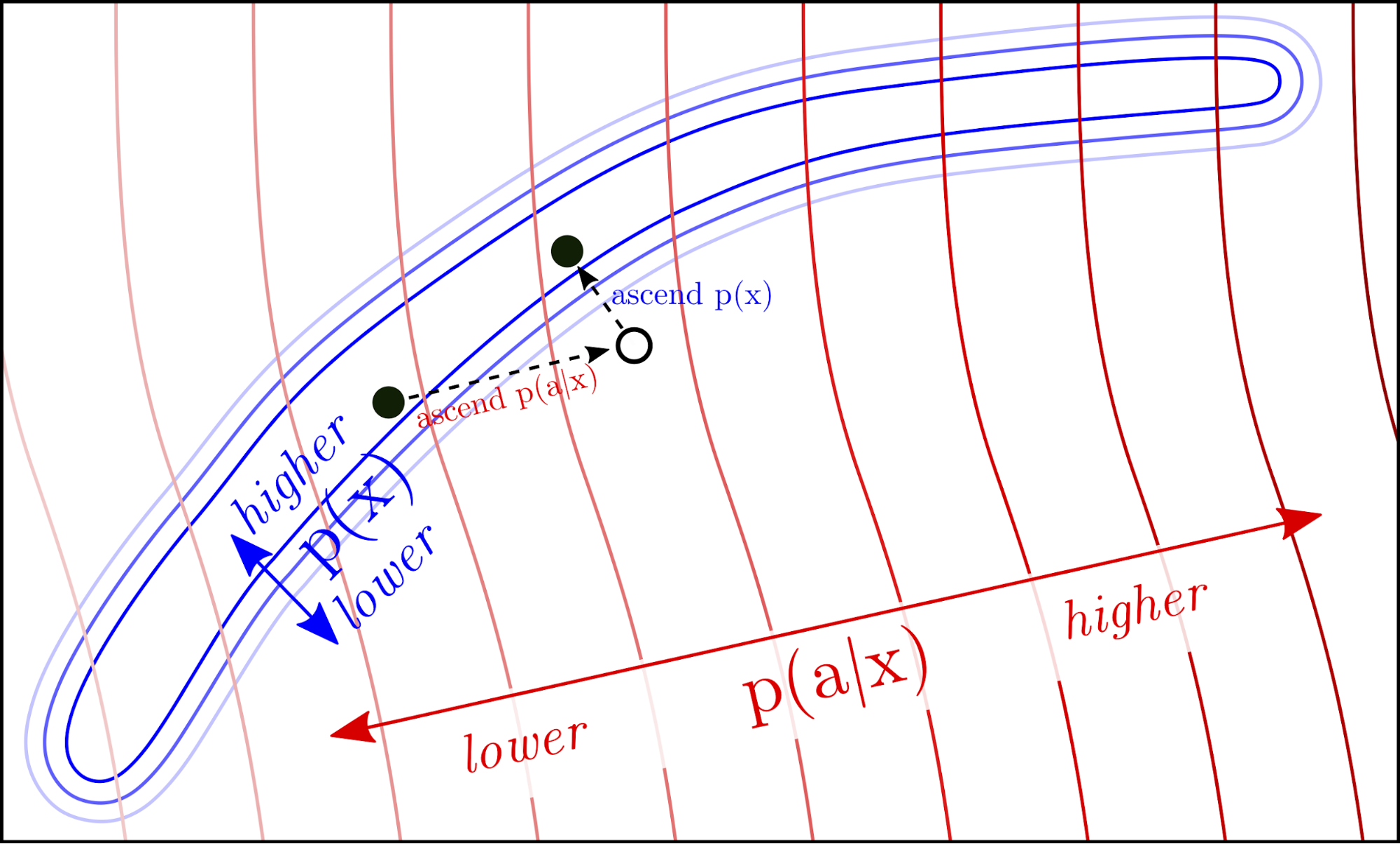
In addition to steering generated text using gradients from a particular p(a|x) attribute model, text must be steered by the p(x) from a base LM. As alluded by Bayes’ rule above and described in more detail in our paper, without also taking gradient steps in the direction of high likelihood by the LM, language degenerates; for example, optimizing only for positivity but not LM likelihood can produce strings like “great great great great great”. Thus, we use the unmodified language model to ensure the fluency of language is maintained at or near the level of the original language model (in this example, GPT-2-medium). We do this in two ways: first, by taking steps to minimize the Kullback–Leibler (KL) Divergence between the output distribution of the modified and unmodified language models, and second by performing post-norm fusion (introduced in Stahlberg et al. (2018)) between the modified and unmodified next word distributions. Through both factors the generated text is kept in high p(x) regions, as described in Section 3.3 of our paper and illustrated in Figure 3, below:
Attribute models
Now that we have worked out the method and the math behind PPLM, let’s see what samples we can generate using different attribute models!
Bag-of-words
The simplest attribute model (p(a|x)) we consider is a bag of words (BoW) representing a topic, where the likelihood is given by the sum of likelihoods of each word in the bag. For example, a BoW representing the topic Space may contain words like “planet”, “galaxy”, “space”, and “universe”, among others. We use PPLM-BoW to refer to the method of PPLM controlled generation where the attribute model is a BoW. In Table 1, below, we show samples of PPLM-BoW under the topic [Space] with several prefixes. In each sample, the text is relevant to the topic as well as fluent.

We can switch to other topics, such as [Military] and [Science], shown below in Table 2, all with the same prefix. Here we see that increasing the probability of generating words in the bag also increases the probability of generating related topical words not in the BoW (e.g., in the [Science] sample shown below, note that “question” and “philosophers” are sampled before the first BoW word, “laws“). This is because shifting the latents coherently shifts the topic in the direction desired; as we’ll see later, this works better than directly promoting the set of desired keywords.

Lastly, we play with unnatural prefixes that start the sentence nowhere near the intended topic, for example, turning “The chicken” into [Politics], as shown in Table 3. We observe that even with odd sentence starters, PPLM is able to steer the generation effectively.

We showed thousands of such PPLM-generated samples to human evaluators and asked them to label which they found related to each topic and to judge the fluency of each sample. Figure 4, below, shows the human evaluated topic relevance (percent) of the GPT-2 baseline (B), a baseline with reranking via the attribute model (BR), and two PPLM variants: gradients applied to the latents with (BCR) and without (BC) ranking.
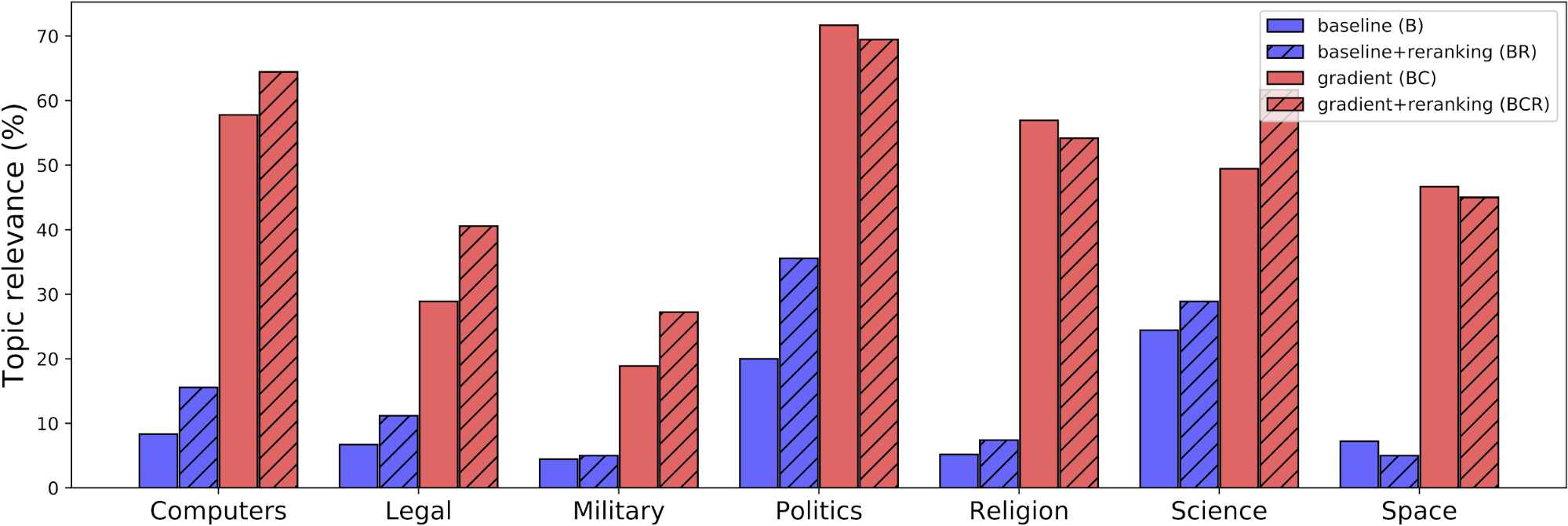
We also performed comprehensive automated evaluations and compared to alternative baselines such as weighted decoding and CTRL; see Section 4 of our paper for a complete description of the evaluation methodology and results of this experiment. We find that PPLM significantly outperforms weighted decoding (WD) and slightly outperforms CTRL, while being comparably fluent with both WD and CTRL (note that CTRL uses a larger LM model with over four times as many parameters as the GPT-2 base LM used here).
Simple discriminators
While BoW is a simple and intuitive way to represent a topic attribute, some attributes are more difficult to express; for example, positive and negative sentiments. While they can, to some extent, be reflected by the presence of certain words, the real sentiment of sentences lies far beyond word presence.
In these scenarios we can express attributes with a discriminator trained on a dataset labeled with the desired attributes. Models of this type, denoted PPLM-Discrim, employ a single layer classifier attribute model that predicts the target label from the mean of the embedded representation extracted from the original LM model. The number of parameters in this layer can be 5,000 or lower, which is negligible compared to the number of parameters in the LM itself.
In the example shown in Table 4, below, we use a sentiment discriminator with 5K parameters (1025 parameters per class) trained on the labeled SST-5 dataset to steer generation of texts toward positive and negative sentiments:

As before, we perform an ablation study with the four variants: ‘B’, ‘BR’, ‘BC’, and ‘BCR’. Figure 5, below, shows the ablation study results:
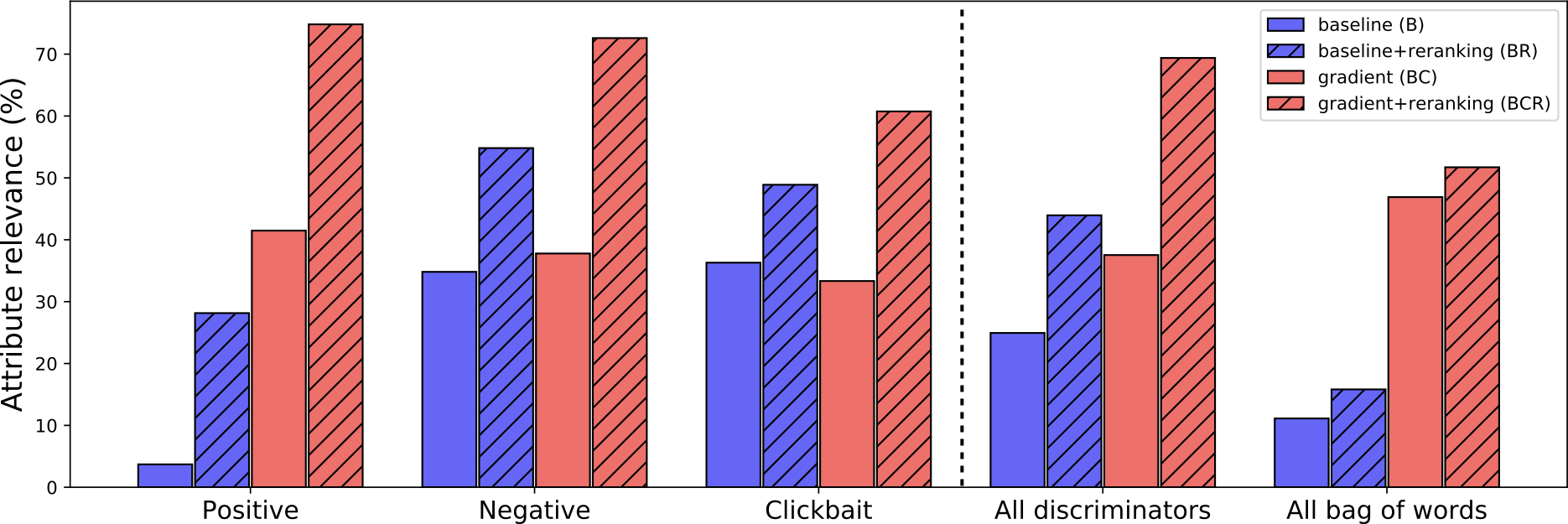
Additionally, we compare PPLM with baselines: weighted decoding, CTRL (Keskar et al., 2019) and GPT2-FT-RL (Ziegler et al., 2019), an LM fine-tuned for positivity. We find that PPLM significantly outperforms weighted decoding and GPT2-FT-RL, while performing comparably with CTRL (see Section 4 of our paper).
Multiple attribute models
We may combine multiple attribute models in controlled generation, e.g., multiple BoWs together with discriminator. For example, we can control the generation toward a mixed topic about Winter, Politics and Kitchen, while turning Positive, as seen in Table 6, below. (We provide many more such examples in our paper.)

Steering biased language models away from toxic speech
The inherent flexibility of the PPLM architecture allows one to make use of any differentiable attribute model, whether that model detects simpler attributes like positivity or negativity or more subtle but societally meaningful concepts like biased or offensive speech. We consider this application next.
It has been noted that LMs trained with a large corpus of Internet data can reflect biases and toxicity present in their training data. Wallace et al. (2019) demonstrated that using adversarial attacks could make GPT-2 produce racist output when given a carefully optimized trigger string as a prefix. Without a solution, this unfortunate property limits the scenarios in which LMs can be safely deployed.
Fortunately, PPLM can easily be adapted for language detoxification by plugging in a toxicity classifier as the attribute model and updating latents with the negative gradient. We conducted a test in which willing human evaluators flagged the toxicity of 500 text samples generated by PPLM with detoxification vs a GPT-2 baseline using ten different adversarial triggers as prefixes. On average the fraction of toxic speech produced dropped from 63.6 percent to 4.6 percent. Further numerical results are discussed in Section 4.4 of our paper; we chose to omit all samples, judging the benefit to the scientific community of publishing specific examples to be minor relative to the offense some may cause.
While we are pleased PPLM was able to reduce toxicity in this scenario, much work remains to further prevent toxic output by models and more broadly to ensure models are used in alignment with their designers’ intentions.
The ethics of controlled language models
There has recently been substantial discussion around the ethics of capable language models, both in their potential to recapitulate problematic social biases and for them to be directly abused for societal harm (e.g., to generate disinformation). While one aim of our research is to suggest a mechanism to detoxify language models, we also acknowledge that nearly the same mechanism could be exploited to instead create more toxic language. Such possibilities are inherent to general-purpose technologies like machine learning, and we believe that on balance this work creates a net positive by advancing the discussion of model capabilities, properties, and potential solutions to risks faced by current models.
Moving forward
With this research, we introduce PPLM, an on-the-fly configurable method for controlled language generation that allows flexible combination of a large, pre-trained language model with one or more BoW models, tiny discriminators, or other attribute models. PPLM achieves fine-grained control of attributes such as topics and sentiment while retaining fluency, all without LM retraining or fine-tuning.
PPLM can be thought of as a generic machine for flipping literary critic models p(a|x) that can judge the worthiness of text they read into author models p(x|a) that can write something similarly worthy. In this sense, PPLM’s machinery is quite generic, permitting use of any differentiable attribute models, which will enable diverse and creative applications beyond the examples given here.
If you’re interested in learning more about work, check out our code (standalone code / code in Hugging Face /transformers), play with the interactive demo and the Colab, read our paper, and let us know what you find!
Acknowledgements
Artwork in this article was created by Eric Frank and Colan Chen. We would like to thank all of our annotators at Uber for providing reliable human evaluation, Joel Lehman for discussing the ethical implications of this work with us, Molly Vorwerck for her tireless editing help, and members of the Deep Collective research group at Uber AI for their helpful discussion, ideas, feedback, and comments on early drafts of this work.
We would also like to thank Julien Chaumond, Lysandre Debut, Thomas Wolf, and the entire Hugging Face team for producing the PPLM demo with us and helping us integrate the code into their Transformers repository, as well as thank Bryan McCann (Salesforce Research) for helping with the CTRL baseline.

Rosanne Liu
Rosanne is a senior research scientist and a founding member of Uber AI. She obtained her PhD in Computer Science at Northwestern University, where she used neural networks to help discover novel materials. She is currently working on the multiple fronts where machine learning and neural networks are mysterious. She attempts to write in her spare time.

Sumanth Dathathri
Sumanth Dathathri is currently a graduate student at Caltech, and is interested in problems at the intersection of control theory, formal methods and machine learning. He was a summer 2019 intern at Uber AI exploring language processing.

Andrea Madotto
Andrea Madotto is a third-year PhD student at The Hong Kong University of Science and Technology studying Electronics and Computer Engineering and he was a summer 2019 intern with Uber AI. He works on natural language understanding and conversational AI.

Piero Molino
Piero is a Staff Research Scientist in the Hazy research group at Stanford University. He is a former founding member of Uber AI where he created Ludwig, worked on applied projects (COTA, Graph Learning for Uber Eats, Uber’s Dialogue System) and published research on NLP, Dialogue, Visualization, Graph Learning, Reinforcement Learning and Computer Vision.

Jason Yosinski
Jason Yosinski is a former founding member of Uber AI Labs and formerly lead the Deep Collective research group.
Posted by Rosanne Liu, Sumanth Dathathri, Andrea Madotto, Piero Molino, Jason Yosinski
Related articles





Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
