Introducing Piranha: An Open Source Tool to Automatically Delete Stale Code
March 17, 2020 / Global
At Uber, we use feature flags to customize our mobile app execution, serving different features to different sets of users. These flags allow us to, for example, localize the user’s experience in different regions where we operate and, more importantly, to gradually roll-out features to our users and experiment with different variations of the same functionality.
However, after a feature has either been 100 percent rolled out to our users or an experimental feature has been deemed unsuccessful, the feature flag in the code becomes obsolete. These nonfunctional feature flags represent technical debt, making it difficult for developers to work on the codebase, and can bloat our apps, requiring unnecessary operations that impact performance for the end user and potentially impact overall app reliability.
Removing this debt can be time-intensive for our engineers, preventing them from working on newer features.
Seeking to automate this process, we developed Piranha, a tool that scans source code to delete code related to stale, or obsolete, feature flags, leading to a cleaner, safer, more performant, and more maintainable code base. We run Piranha at Uber in an ongoing pipeline for our Android and iOS codebases, and have used it to remove around two thousand stale feature flags and their related code.
We believe Piranha offers great utility for organizations that use feature flags in their app deployments, and so have open sourced it. Currently implemented for Objective-C, Swift, and Java programs, open source contributors may want to apply Piranha to other languages or improve on its ability to perform deep code refactorings.
The life and death of feature flags
To introduce a flag, a developer creates an entry in Uber’s flag management system, and inputs attributes such as the name of the flag, type of flag, target roll-out percentages, targeted platforms, and geographical locations where the flag is operational. Furthermore, the flag is manually introduced in the source code, which establishes a coherent association between the flag on our experimentation platform and the mobile app instance. From then on, this flag works as a variable in the code to manage the app behavior.
From the running app’s point of view, a feature flag is a single key, mapping to one of two or more conditions, such as on/off, color values, sizes, and copy text. At startup, our mobile apps query our flag management system over the network and retrieve a specific treatment condition for each flag for the current instance of the app. The returned value determines the presence and behavior of the feature in the app.
In the simplest case, when gradually rolling out a single feature, we have a control condition (where the feature is not enabled), and a treatment condition (where the feature is enabled). We tend to initially apply the treatment condition to a small subset of users, gradually growing application of the treatment to encompass all users for which the feature is relevant (e.g. everyone in a particular geographic location) if the rollout proves successful. If issues arise during the rollout, we have the ability to stop and rollback, ensuring minimal impact on our users.
Our system can also handle various different implementations of the same feature, such as experimenting with different interfaces to be tested on different sets of users (e.g. A/B testing).
Many features end up being rolled out to 100 percent of users globally. Sometimes, we wish to keep the feature flag guarding that functionality in the code to act as a safety kill-switch for non-critical application functionality. That way, a potential bug or crash in a minor feature, which otherwise could take out the whole app, can be easily mitigated server-side by turning off the previously universally rolled-out feature flag. However, because most features are nested under other features, such intentional kill switches are not the common end state of most feature flags.
We consider most feature flags associated with 100 percent rolled out features as “stale,” meaning that the flag itself no longer serves a purpose and could be replaced by hard-coding the version of the feature that was fully rolled out. A similar case happens with experiments, or treatment conditions, that have been 100 percent rolled back to their control (i.e. no feature) condition.
Technical debt due to stale flags
When a flag becomes stale, it should be disabled in the feature flag management system and all code artifacts related to the flag need to be removed from the source code, including the now-unreachable implementation of alternative versions of the feature. This ensures improved code hygiene and avoids technical debt.
In practice, developers do not always perform this simple post-cleanup process, leaving in code related to obsolete flags, causing accumulation of technical debt. The presence of code related to these unnecessary flags can affect software development across multiple dimensions. First, developers have to reason about the control flow related to these obsolete flags, as well as deal with a large swath of unreachable code in the monorepo. Second, such code might still be made executable in unexpected cases (e.g. due to a flag management backend error), reducing the overall reliability of the application. Third, effort must be spent to maintain test coverage of these unnecessary paths. Finally, the presence of dead code and tests impacts the overall build and testing time, affecting developer productivity.
Automatically deleting code related to stale flags
To address the problem of technical debt due to stale feature flags, we designed and implemented Piranha, an automated source-to-source code refactoring tool, which is used to automatically generate differential revisions (in other words, diffs) to delete code corresponding to stale feature flags. Piranha takes as input the name of the flag, expected treatment behavior, and the name of the flag’s author. It analyzes the abstract syntax trees (ASTs) of the program to generate appropriate refactorings which are packaged into a diff. The diff is assigned to the author of the flag for further inspection, who can then land (commit to master) as is, or perform any additional refactorings before landing it. We also built workflows around Piranha for it to periodically remove stale code in a configurable manner.
Feature flag example
Let’s go over a simple example illustrating the basic usage of feature flags in the source code at Uber.
Initially we define a new flag named RIDES_NEW_FEATURE amongst a list of flags in RidesExpName, and register it in the flag management system. Subsequently, we write the flag into the code using a feature flag API, isTreated, and provide the implementations of treatment/control behaviors under the if and else branches, respectively:
public enum RidesExpName implements ExpName {
RIDES_NEW_FEATURE,
…
}
if (experiments.isTreated(RIDES_NEW_FEATURE)) {
// implementation for treatment (on) behavior
} else {
// implementation for control (off) behavior
}
To test the code with various flag values, for each unit test, we can add an annotation to specify the value of the feature flag. Below, test_new_feature runs when the flag under consideration is in a treated state:
@Test
@RidesExpTest(treated=RidesExpName.RIDES_NEW_FEATURE)
public void test_new_feature() {
…
}
When RIDES_NEW_FEATURE becomes stale, all the code related to it needs to be removed from the codebase. This includes:
-
- The definition in RidesExpName.
- Its usage in the isTreated API.
- The annotation @RidesExpTest.
Additionally, the contents of the else-branch, implementing the now unreachable control behavior, must be deleted. We also want to delete code for any tests which involve this removed behavior.
Not deleting these code artifacts can gradually increase the complexity and overall maintainability of our source code.
Automation challenges
Unsurprisingly, there exist many difficulties in automating detection of obsolete flags and associated code removal. These range from determining whether a flag was in use to who owns the flag and down to the specifics of how its code was written. Overcoming these challenges was key to Piranha’s development.
Flag staleness
Determining whether a flag is stale or not is surprisingly non-trivial. First, the flag should have been rolled out 100 percent either as treatment or as control. A flag that is not 100 percent rolled out presumably means its experiment is still in progress. Even when it is rolled out, the developer may not be ready to eliminate the flag. For example, flags may be used as kill switches or for monitoring debug information. Therefore, even when flags are completely rolled out, they still might be in use.
Flag ownership
During Uber’s early growth determining ownership information for stale flags became challenging. Even if we could perfectly determine flag authorship, the author in question may have moved to another team or left the organization.
Coding style
The lack of any restrictions pertaining to code related to feature flags increases the complexity underlying the design of an automated tool. For example, helper functions for flag-related code cannot be easily differentiated from any other function in the code. Also, the complexities introduced by tests where developers allow manual state changes to the flag can restrict the tool in performing a comprehensive cleanup. For instance, when flag-related code is being unit tested, sometimes it is unclear whether the test can be discarded in its entirety because the functionality is removed, or specific state changes within the body of the test need to be removed so that the remaining functionality can continue to be tested.
Building Piranha using static analysis
Given our shared background in program analysis, we envisioned that this problem can effectively be solved by applying static analysis to delete unnecessary code due to stale flags.
We identified three key dimensions for performing the cleanup:
-
- Delete code that immediately surrounds the feature flag APIs.
- Delete code that becomes unreachable due to performing the previous step. We refer to this as deep cleaning.
- Delete tests related to feature flags.
In order to perform precise cleanup across all three dimensions, it would be necessary to perform reachability analysis to identify code regions that become unreachable and implement algorithms to identify tests related to testing feature flags. While this would ideally ensure complete automation where a developer simply needs to review the deletions and land the changes in master, it requires overcoming two challenges: ensuring that the underlying analysis to perform cleanup is sound and complete, and that the engineering effort required to implement and scale such analysis to processing millions of lines of code in a useful timeframe is available.
Since determining reachability in a sound and complete manner is often impractical, we decided against building a complex analysis where the amount of developer intervention post-cleanup is unknown and the return on engineering investment is unclear. Instead, we chose a practical approach of designing the technique iteratively, based on the coding patterns observed in the codebase.
We observed that there are three kinds of flag APIs:
-
- Boolean APIs that return a boolean value and are used to determine the control path taken by the execution.
- Update APIs which update the feature flag value in the running system.
- Parameter APIs that return a non-boolean primitive value (integer, double, etc) which corresponds to an experimental value being controlled from the back end.
Our refactoring technique parses the ASTs of the input source code to detect the presence of feature flag APIs that use the flag under consideration. For boolean APIs, we perform a simple boolean expression simplification. If the resulting value is a boolean constant, we refactor the code appropriately. For example, if the boolean API occurs as part of an if statement and simplifies to true, we refactor the code by deleting the entire >if statement, replacing it with the statement(s) inside the then clause.
For update APIs, we simply delete the corresponding statement. We do not handle parameter APIs as the engineering effort required to address them was much larger and the frequency of their occurrence in the codebase much lower.
Since we observe that the boolean APIs need not always be used within a conditional guard, we designed a second pass for our refactoring. We identify assignments where the right hand side is a boolean API that Piranha has simplified to a constant and track the assignee variables. Similarly, we track wrapper methods that return a boolean API which is simplified to a constant. Subsequently, we identify uses of the assignee variables or wrapper methods in conditional guards to perform the refactoring.
Finally, we handle flag annotations for tests by discarding the entire test if the flag annotation does not match the input treatment behavior. Otherwise, we simply delete the annotation for the test.
In summary, Piranha takes as input the following: the stale flag under consideration, the treatment behavior, and the owner of the flag. It analyzes the code for uses of this flag in pre-defined feature flag APIs and refactors it to delete code paths based on the treatment behavior.
Using Piranha at Uber
We implemented Piranha to refactor Objective-C, Swift, and Java programs. PiranhaJava refactors stale feature flag related code in Java applications, specifically those targeting the Android platform. It is implemented in Java on top of Error Prone as an Error Prone plugin. PiranhaSwift is implemented in Swift using SwiftSyntax for refactoring Swift code. PiranhaObjC is used to clean up code in Objective-C programs and is implemented in C++ as a Clang Plugin, using AST matchers and rewriters internally to parse and rewrite the ASTs.
While Piranha as a standalone tool can perform code refactorings, developers don’t always prioritize flag cleanup, so may not use it as frequently as needed. Just as Piranha automates flag cleanup, we needed a system to automatically initiate these cleanups.
Internally, we built a workflow pipeline that periodically (in our case, weekly) generates diffs and tasks to cleanup stale feature flags. The Piranha pipeline queries the flag management system for a list of stale flags, and for each of these flags, it individually invokes Piranha, providing as input the name of the stale flag, its owner, and the intended output behavior, either treatment or control.
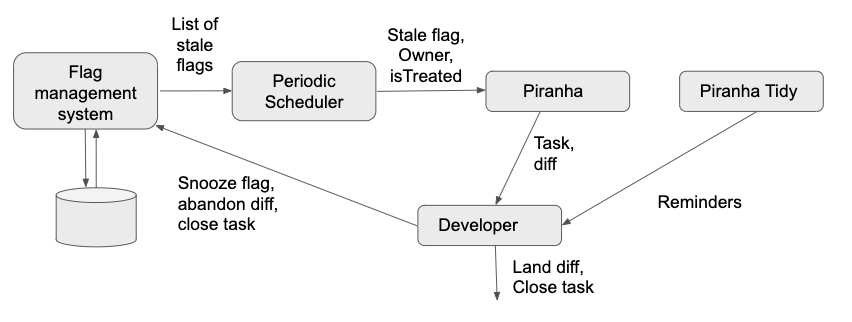
Figure 1, above, presents the architectural diagram of the Piranha pipeline. Piranha generates a diff (i.e. a pull request) and puts it up in our code review system, with the flag’s original author as the default reviewer. The author can either accept the diff as is, modify it as needed, or reject and mark the flag as not being stale. The pipeline also generates a cleanup task in our task management system to track the status of each generated diff. Since developers may not always act on these diffs in a timely manner, we also introduced a reminder bot, named PiranhaTidy, to periodically add reminders on open Piranha related tasks.
Piranha pipelines use a heuristic to consider flags that are unmodified in the flag management system for more than a specific period (e.g., 8 weeks) as stale and generate diffs for those flags. Individual teams responsible for processing Piranha’s output diffs configure the exact time period for staleness of a flag. We observed that the current time taken to generate a diff using Piranha is less than 3 minutes.
Using Piranha for your own code
We are happy to announce that Piranha is now open source for all three supported languages. We believe the tool will be useful for your team, if your code meets the following criteria:
-
- Uses feature flags extensively
- Has specific APIs to control the behavior of feature flags
- Is implemented in Java, Swift, or Objective-C
Setting up Piranha for your codebase is fairly straightforward: define the feature flag related APIs and expected behavior in the properties file, then run Piranha with the name of the stale flag and expected output behavior. See the documentation for more details pertaining to how to use Piranha for each language.
We welcome developer contributions for Piranha. Developers of all abilities are welcome, and working on the implementation of Piranha may be a great way to understand the nuances of program analysis for non-experts in the area. There are many interesting projects pertaining to refining the code refactorings generated by Piranha, extending Piranha to other languages (e.g., Kotlin, Go, etc), and design and implementation of other feature flag-related program analyses. Please download the source code for Piranha to get started.
If you are interested in joining our Programming Systems team to work on other exciting projects in programming languages, compilers and software engineering, and have academic or industrial experience in program analysis, compilers and related areas, please reach out to our team.
A detailed research paper on Piranha will appear in the International Conference of Software Engineering, Software Engineering and Practices track (ICSE-SEIP ‘20), Seoul, South Korea.

Murali Krishna Ramanathan
Murali Krishna Ramanathan is a Senior Staff Software Engineer and leads multiple code quality initiatives across Uber engineering. He is the architect of Piranha, a refactoring tool to automatically delete code due to stale feature flags. His interests are building tooling to address software development challenges with feature flagging, automated code refactoring and developer workflows, and automated test generation for improving software quality.

Lazaro Clapp
Lazaro Clapp is a senior engineer on Uber's Programming Systems team. His current focus is to improve application reliability by preventing broad categories of bugs using fast type-system based tools, as well as dynamic bytecode-level instrumentation of end-to-end tests. His research interests more broadly include static and dynamic analysis, modeling of third-party code behavior, as well as automated test generation and UI exploration for mobile applications. http://lazaroclapp.com/

Rajkishore Barik
Rajkishore Barik is a programming systems research scientist and technical manager on Uber's Programming Systems team. He currently works on building tools for understanding performance anomalies in data centers, including developing static analysis and transformation tools for Swift and Go. In the past, he has worked on optimizing compilers and runtime systems.

Manu Sridharan
Manu Sridharan, formerly a staff engineer at Uber, is an Associate Professor of Computer Science and Engineering at the University of California, Riverside.
Posted by Murali Krishna Ramanathan, Lazaro Clapp, Rajkishore Barik, Manu Sridharan
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ
Products
Company
