‘Orders Near You’ and User-Facing Analytics on Real-Time Geospatial Data
July 20, 2021 / Global
Introduction
By its nature, Uber’s business is highly real-time and contingent upon geospatial data. PBs of data are continuously being collected from our drivers, riders, restaurants, and eaters. Real-time analytics over this geospatial data could provide powerful insights.
In this blog, we will highlight the Orders near you feature from the Uber Eats app, illustrating one example of how Uber generates insights across our geospatial data.
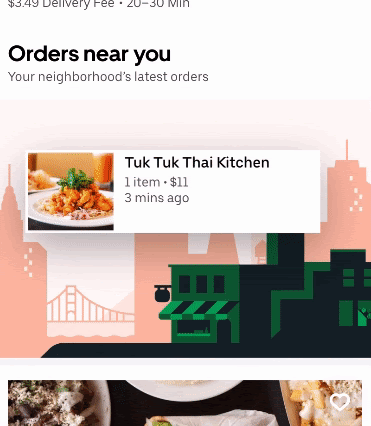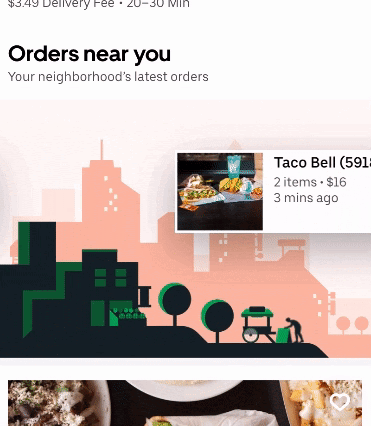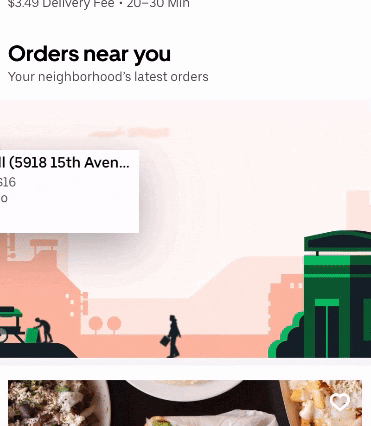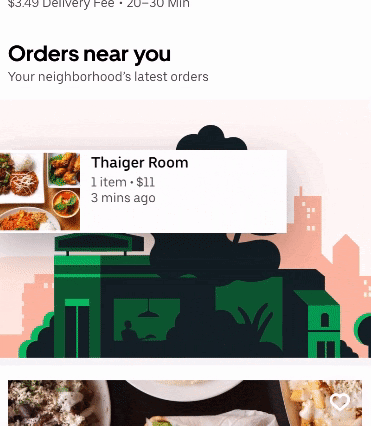
Orders near you was a recent collaboration between the Data and Uber Eats teams at Uber. The project’s goal was to create an engaging and unique social experience for eaters. We hoped to inspire new food and restaurant discovery by showing what your neighbors are ordering right now. Since this feature is part of our home feed, we needed it to be fast, personalized, and scalable.
Requirements
There were two main requirements of the project. Firstly, the orders needed to be near real time. The number of minutes since the order was placed is displayed in the subtext of each carousel item. It was important that we were displaying relevant, recent options to eaters.
Another important consideration in our design was deliverability. The contents of the carousel needed to be deliverable to the eater. Hence, we needed an efficient and scalable way to retrieve geographically close orders.
Real-Time Analytics with Apache Pinot
The core building block of Orders near you is Apache Pinot, a distributed, scalable OnLine Analytical Processing (OLAP) system. It is designed for delivering low latency, user-facing real-time analytics on TeraByte-scale data. Apache Pinot supports near-real-time table ingestion. It is well suited for low latency, high Queries-Per-Second (QPS) workloads of analytic queries. It supports data ingestion from batch data sources like Apache Hadoop® HDFS, as well as stream data sources like Apache Kafka®, as depicted below.
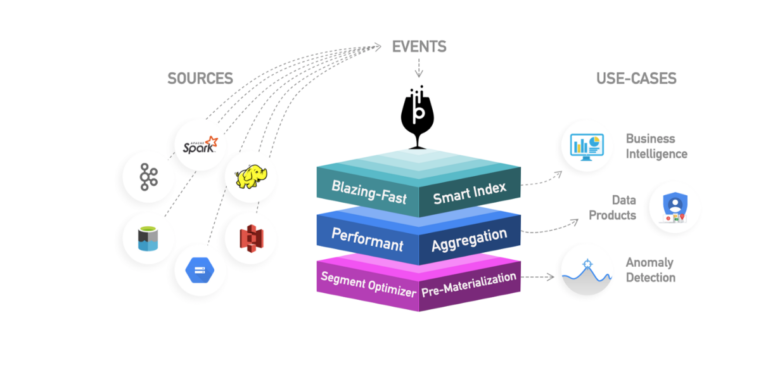 At Uber we operate multi-tenant Apache Pinot clusters with multi-region redundancy. We provide seamless table onboarding and querying tools to platform users. This enables our teams to build applications on top of Apache Pinot without worrying about operational or functional details.
At Uber we operate multi-tenant Apache Pinot clusters with multi-region redundancy. We provide seamless table onboarding and querying tools to platform users. This enables our teams to build applications on top of Apache Pinot without worrying about operational or functional details.
Apache Pinot empowers many other mission-critical use cases at Uber. For example, we published another blog post on how Uber addressed COVID-19 challenges for merchants and kept restaurants open via live monitoring and automation. Also, if you are interested in how we operate Apache Pinot at Uber scale, please read our previous blog post.
Geospatial Support in Apache Pinot
Geospatial data has been widely used across industry. Some examples include ride-sharing and delivery, transportation infrastructure, defense, intel, and public health. Orders near you is one such example of real-time analytics over geospatial data, to allow the fast, fresh, actionable insights.
To derive insights from timely and accurate geospatial data, Uber has contributed geospatial support to Apache Pinot. Since Apache Pinot 7.1, geospatial types such as points, lines, and polygons have been introduced to abstract and encapsulate spatial structures. In addition, a subset of geospatial functions conforming to the SQL/MM 3 standard are added for measurements (e.g., ST_Distance, ST_Area), and relationships (e.g., ST_Contains, ST_Within). For example, the orders-near-you application can retrieve the nearby orders of a user with the SQL query below:

Note that this query is parameterized with the longitude and latitude of the user location, as well as a timestamp of the recent time, such as the past 5 minutes. With these parameters, the query will retrieve all the recent Eats orders placed within certain distance of the user’s location.
A naive execution of this query is to scan all the recent orders over the globe, and for each order evaluate the ST_Distance function to determine if it’s within the desired range. However, geospatial functions are typically expensive to evaluate, which can be a scalability challenge for a high-QPS application like orders-near-you. To address this, Uber contributed geospatial indexing to Pinot to greatly accelerate the geospatial query evaluation. Geospatial indexing in Pinot is based on Uber’s H3, a hexagon-based hierarchical geospatial indexing library. A given geospatial location (longitude, latitude) can map to one hexagon (represented as H3Index). And its neighbors in H3 can be approximated by a ring of hexagons as the diagram below shows.
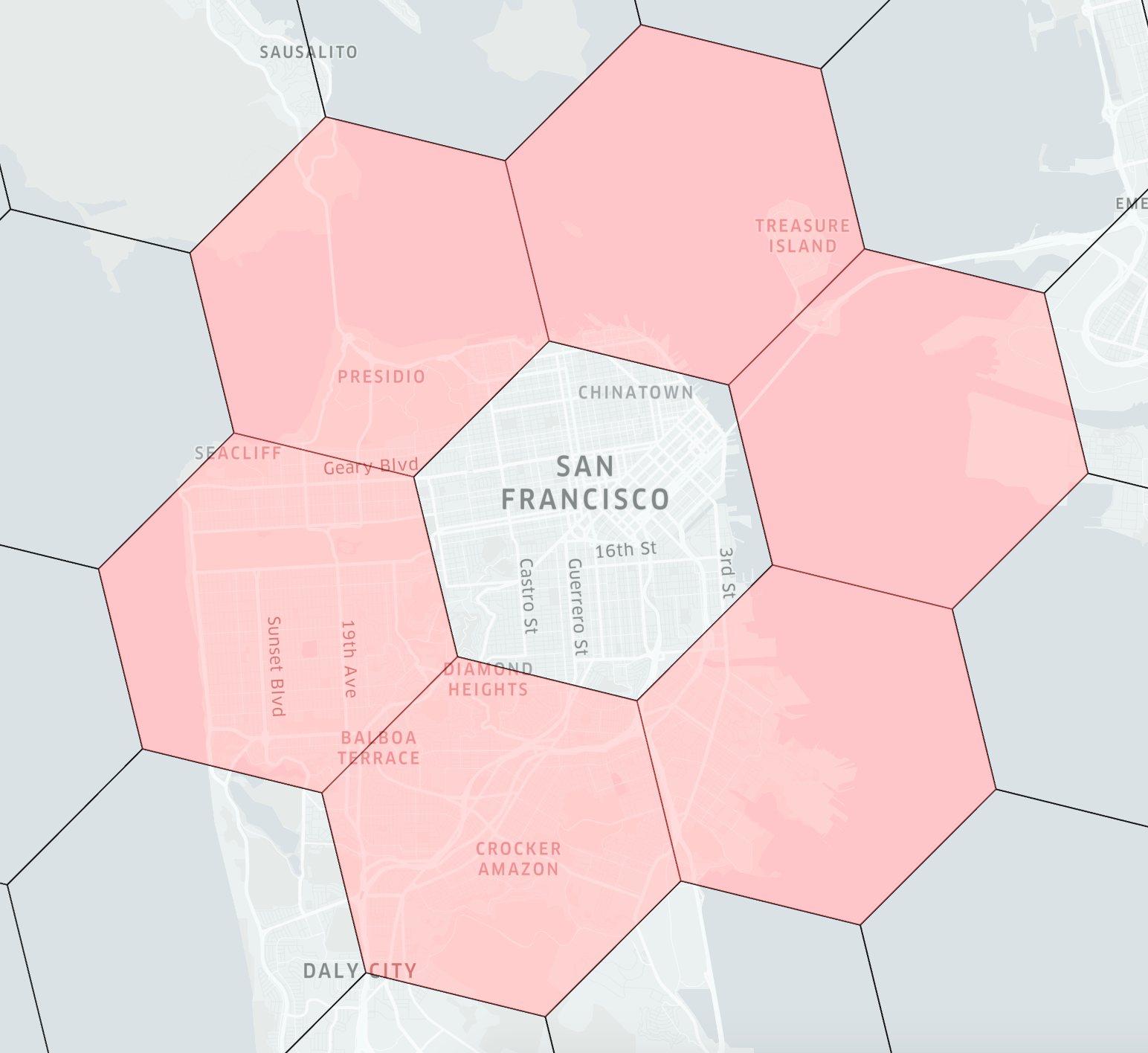
To quickly identify the distance between any given two geospatial locations, Apache Pinot can convert the two locations in the H3Index, and then check the H3 distance between them. H3 distance is measured as the number of hexagons. For example, in the diagram above, the red hexagons are within a distance of one from the central hexagon.
With the geospatial index, Pinot can rewrite the range predicate of ST_Distance(location_st_point_1, ST_Point($lat, $lon)) < $distance in the orders-near-you query to a geospatial index lookup. At the high level, rewriting uses the index to retrieve all the records from the hexagons that are fully contained within the search radius (i.e., the red circle in the figure below). Records from hexagons that overlap with the search radius are filtered with the ST_Distance function to accurately identify the matched results. This greatly reduces the number of records needed for ST_Distance function evaluation from every single order globally to only the ones overlapping with the red circle in the figure.

Thanks to the geospatial indexing, P99 of the orders-near-you queries can finish within 50ms. This is critical for the application to endure thousands of queries per second and keep a small fleet of Apache Pinot servers for serving.
It’s worth noting that Apache Pinot is the only real-time OLAP system of its kind that supports H3-based geospatial indexing and the SQL functions conforming to the MM3 standard. For more details about the geospatial support in Pinot, please read this user guide on Pinot docs.
Horizontal Scaling in Apache Pinot for High QPS
Apache Pinot operates on a scatter-gather approach for distributed query processing where, by default, it fires a query to all servers in the tenant and then combines results from all of them. Since the Order near you feature is eater-facing, it has very high QPS along with low latency requirements. In this case, we had to consider optimizing the scatter-and-gather.
By default, Pinot uniformly distributes all the segments to all servers of a table with a configured number of replicas. When a scatter-and-gathering query request arrives, the Pinot broker also uniformly distributes the workload among servers for each segment. As a result, each query will span out to all servers with balanced workload. It works pretty well when QPS is low and you have a small number of servers in the cluster. However, as we have higher QPS, the default numbers of replicas and servers are not enough to keep up with the traffic. Additionally, the probability of hitting slow servers (e.g., GC) increases steeply and Pinot will suffer from a long tail latency.
In order to address this issue, Pinot has the concept of a Replica Group, which allows us to control the number of servers to fan out for each query. A replica group is a set of servers that contains a ‘complete’ set of segments for a table. Once we assign the segment based on the replica group, each query can be answered by fanning out to a single replica group, instead of all servers. Following is a sample part of the table config indicating a replica-group-based assignment.

As seen above, you can use numReplicaGroups to control the number of replica groups (replications), and use numInstancesPerReplicaGroup to control the number of servers to span. More information about the replica group can be found here.
Insights Gained on the Storage Choice
Throughout the architecture iterations of the orders-near-you application, there are several good insights that the teams gained, in particular on the storage choice.
In the first version of its implementation, the application reused the Apache Cassandra® store as the data backend, because Cassandra is used as a permanent store for placed Eats orders. In the initial version, the implementation first retrieved nearby restaurants from the given user location (longitude, latitude), fetched the active orders from the order-gateway service, and finally ranked all the results by recency and merge.
This design ran into some scalability challenges. As the diagram below shows, each user request made up to 20 calls to the order-gateway service for different restaurants, which in turn made 120 calls to Cassandra for reading. At peak, this application was generating hundreds of thousands Cassandra lookups per second. This would cause a capacity shortage in Cassandra, which the team estimated a 6x increase in capacity would be required to address.
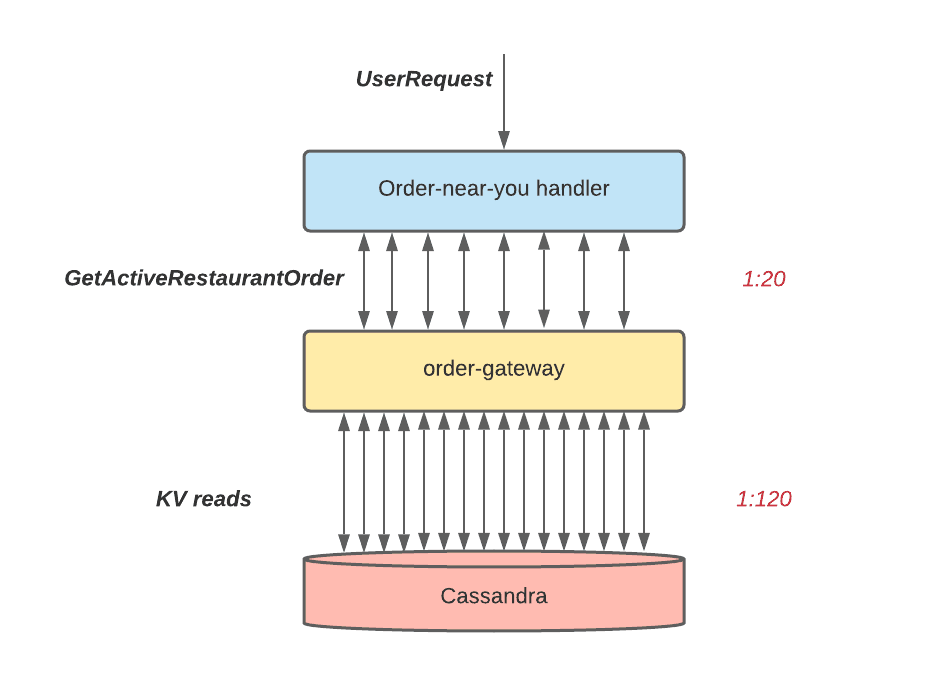
As a comparison, the new architecture is shown in the figure below, where the service makes one SQL query call to Apache Pinot to retrieve all relevant orders for each user request.
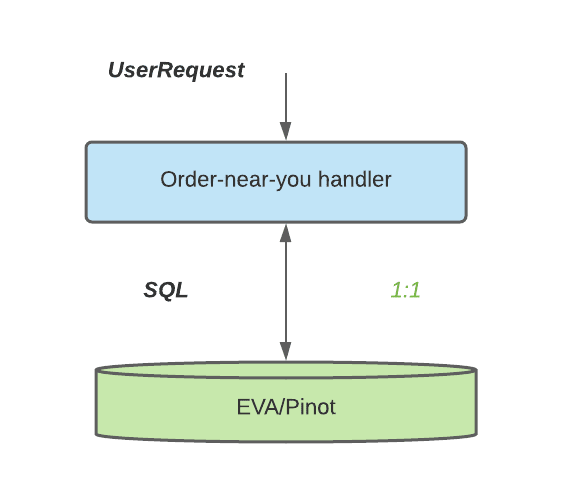
There are several insights we gained from this architecture change, and the most important one is the separation of the operational database (OLTP) from the online analytical database (OLAP). This separation is generally a good practice and widely adopted in the industry for isolation and better reliability. In fact, usually OLTP and OLAP databases are optimized for different query patterns and workflows. In addition to the performance difference, more importantly a clean separation of OLTP and OLAP makes a clean boundary between the online operational processing and the analytical processing, so that analytical loads (order-nearby-use, in this case) do not add risks to the online processing (e.g. Eats orders processing). To abstract this architecture out, the recommended paradigm is shown in the following figure:
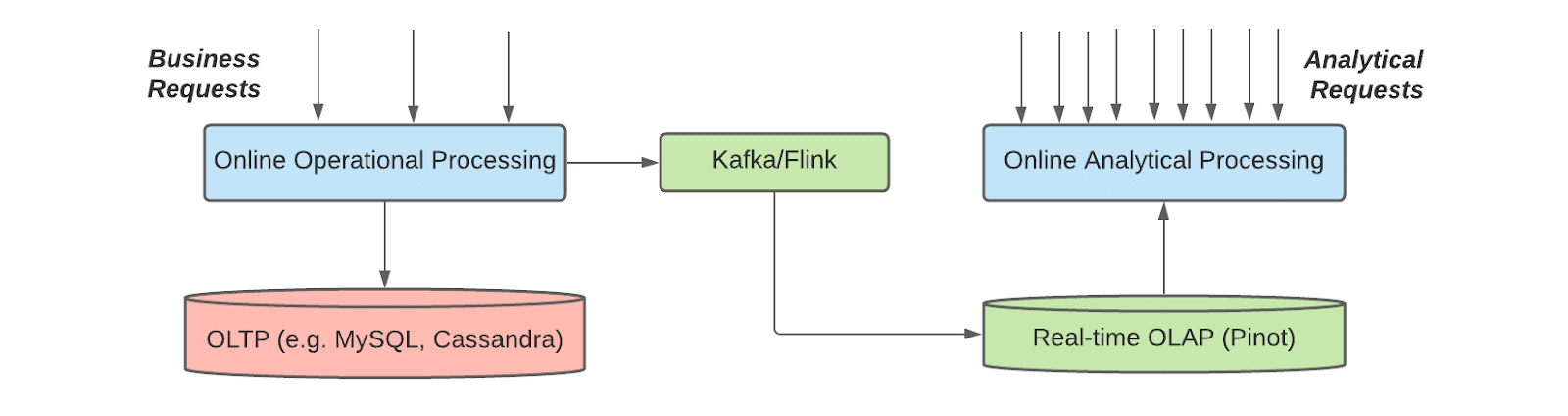
The online operational processing stores data in the OLTP databases (e.g., MySQL and Cassandra), and meanwhile publishes it to Kafka as the modification logs. The Kafka events can be optionally transformed via Apache Flink® and then ingested into a real-time OLAP system like Pinot to serve online analytical processing services. Importantly, this architecture does not compromise on the data freshness, and the data is typically available for query in real-time OLAP, seconds after it has been produced.
This architecture shift brings a number of other benefits:
- Better engineering productivity: Developers can describe their data retrieval logic in an SQL query, and save the efforts on developing/testing/optimizing the well-defined operations like aggregation/sort/filtering. In this case, The Eats team was able to go from design to full launch within a couple weeks for the new design.
- Better query latency: New architecture on Pinot shows much better query latency (<50ms) than the previous one (several seconds.) This is because (1) Pinot colocates data storage and serving so the query processing happens within the local server, whereas the previous architecture requires hundreds of RPC calls across services and storage engines to serve one request, and (2) Pinot employs columnar store and geospatial indexing to efficiently serve the query.
- Better cost efficiency: The decoupling of online OLTP from real-time OLAP opens the opportunity for scaling the storage use efficiently for different purposes. In the previous design, the Cassandra cluster would have to expand six times to handle the new heavy analytical read traffic, even though the operational writes do not change. In contrast, the real-time OLAP engine in the new architecture can easily expand or shrink, depending on analytical traffic needs. In fact, the footprint of the Pinot servers for this use case is quite small, with less than a dozen hosts.
Conclusion
In this blog, we showed how we created an engaging and unique social experience for eaters with real-time order information. And we showed the technology behind the scene that powers this high-QPS and low-latency use case, and Uber’s contribution to Apache Pinot on real-time analytics over geospatial data. Lastly, we shared the insights gained on the architectural paradigm of decoupling real-time OLAP and OLTP, to provide strong isolation of the transactional stores from the analytical traffic and improve the query performance significantly without compromising the data freshness.

Yupeng Fu
Yupeng Fu is a Principal Software Engineer on Uber’s Data team. He leads several streaming teams building scalable, reliable, and performant streaming solutions. Yupeng is an Apache Pinot committer.

Cassandra Tomazic
Cassandra Tomazic is a Backend Software Engineer at Uber on the Eats Growth Engineering team. She works on creating features on the Uber Eats home and search feed.

Dharak Kharod
Dharak Kharod is a Senior Software Engineer at Uber, and has contributed to areas such as Driver Growth, Rider Access, and Data Infrastructure. He is currently on the Real-Time Analytics Platform team working on the core Apache Pinot storage and query layers.
Posted by Yupeng Fu, Cassandra Tomazic, Dharak Kharod
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
Products
Company
