Optimal Feature Discovery: Better, Leaner Machine Learning Models Through Information Theory
May 6, 2021 / Global
Introduction
Suppose you own a production ML model that already works reasonably well. You know that adding relevant and diverse sources of signal to your model is a sure way to boost performance, but finding new features that actually improve performance can be a slow and tedious process of trial and error.
At the start of your search, you might look to reuse features developed for other projects, or you might choose to prototype new features that you suspect would benefit your model. In either case, there could be hundreds to thousands of potential new features to explore, many of them slight variations on common themes. The fundamental problem is that it’s not clear which, if any, of these features will actually improve the performance of your model. The vast majority of new features will overlap partially (if not completely) with features already there.
You might try adding them one at a time or in small groups to assess individual impacts, but this takes time, and it’s hard to uncover synergies among diverse features this way.
It can also be tempting to include the whole kitchen sink of possible features all at once, to maximize lift. Assuming it’s even possible to train a model that large, models with too many features suffer the curse of dimensionality, decreased throughput, higher serving costs, lower interpretability and less resilience to feature drift. Confusingly, attempts to prune less important features from a “kitchen sink” model may yield counter-intuitive results, as SHAP values and other feature importance scores depend greatly on the specifics of one particular trained model, and do not account for feature redundance.
Finally, not all features will be palatable for every use case: in many applications, new features must pass review by business and legal stakeholders before inclusion in a production model.
Motivation
The practical challenges and friction that model owners face when reconsidering features lead to a few common anti-patterns:
- Feature Sprawl: Once features are added to a model, they are seldom revisited or removed, and so models tend to accumulate more and more features over time
- Feature Redundance: Because it’s simpler to throw the kitchen sink of new features into a model, many newly created features will be redundant with already existing features
While feature sprawl and redundance may not obviously impact an individual model’s accuracy at training time, they drive significant direct and indirect costs in a large organization where many teams each own multiple models:
- Soft Outages: Models with lots of features are more susceptible to degradations due to feature drift and upstream data pipeline outages, and these costly outages take longer to diagnose and resolve in the face of large numbers of features
- Increased Costs: The cost of maintaining, computing and serving features grows unnecessarily over time as a result of feature sprawl and redundance; in applications where serving latency is closely tied to business value, increased feature counts can cause tail latencies to rise, eating into profits
If there were a scalable, automated process that addressed the friction and practical challenges inherent in optimizing a model’s features, then we could bring feature sprawl, redundance and their associated costs under control. At Uber AI we’ve been developing an approach that we call Optimal Feature Discovery, which searches for the most compact set of features out of all available at Uber for a given model, both boosting accuracy and reducing feature count at the same time.
Background
Before discussing the details of Optimal Feature Discovery, we’d like to cover a bit of background on the mathematics and software technologies on which it is built. We’ll start with a brief overview of information theory and key ideas like relevance and redundance before connecting these concepts to a subfield of machine learning called information-theoretic feature selection.
Information Theory
In 1948, Claude Shannon introduced information theory, which mathematically formalizes the connection between information and uncertainty (or probability). A central quantity in this theory is called entropy:
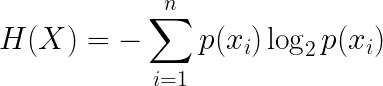
Entropy is a way to quantify the uncertainty about the outcome of a random variable in terms of the expected number of bits required to communicate each outcome. In the formula above, p(xi ) is the probability of a single outcome xi out of n possible outcomes in X. The quantity -log2p(xi ) is the information from a single possible outcome, while the entropy H(X) is the expected amount of information over all possible outcomes of X.
The amount of information obtained about one random variable X by observing another random variable Y is called the mutual information:
![]()
Mutual information is just a difference in entropies: H(X) is the amount of uncertainty about X prior to observing Y, and H(X|Y) is the amount of uncertainty about X given our observation of Y.
Relevance and Redundance
From the perspective of information theory, both the prediction target and the features in a model are random variables, and it’s possible to quantify in bits the amount of information provided about the target by one or more features.
One important concept is relevance, a measure of how much information we expect to gain about the target by observing the value of the feature. Another important concept is redundance, a measure of how much information is shared between one feature and another.
Going back to the coin flip example, there could be different ways to obtain information about the bias of the coin. We could have access to a feature that tells us the rate of heads based on the design of the coin, or we could build a profile feature that tracks the number of heads and tails, historically. Both features are equally relevant in that they provide equal amounts of information, but observing both features doesn’t give us more information than observing either one, hence they are mutually redundant.
In the context of information theory, relevance is represented by the mutual information between a feature X and the target Y, i.e. how much does uncertainty about the target decrease by having observed the feature?
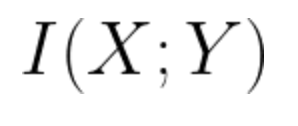
Intuitively, when selecting features for a model, we want to prioritize features with the most relevance, however, in a world where most features are partly or wholly redundant with other features, ranking features by relevance alone won’t lead to the most compact subset of features.
Redundance between two features Xj and Xk can also be quantified using mutual information:

If Xj and Xk are completely independent and don’t overlap at all, then the mutual information will equal 0. As the degree of redundance between Xj and Xk increases, the mutual information increases, up to the point where observing Xj lets you predict the value of Xk exactly.
Information-theoretic Feature Selection
Information-theoretic feature selection is a family of methods that use information theory to rank the set of all possible features in order to choose a small, top-k subset for a predictive model. These methods are useful because searching over the set of all possible feature combinations is costly. Information-theoretic feature selection methods produce step-wise, greedy rankings that approximate quantities like relevance and redundance with respect to labels and features already selected in previous steps. We recommend [2] for a detailed survey of different methods from the literature, but the most well-known method is MRMR (Maximum Relevance, Minimum Redundance). The ranking function for MRMR is shown below:
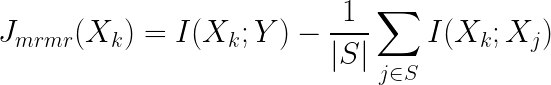
At each stage in the feature selection, MRMR ranks the remaining features based on their relevance, penalized by an approximate measure of redundance with already-selected features. The approximation replaces the joint redundance with a sum of pairwise redundance terms between the feature under consideration Xk and the set S of already selected features.
MRMR and related techniques make it possible to use greedy, stepwise feature selection to discover a compact, diverse subset of relevant features. To understand how this works, suppose the most relevant feature has two copies. After one copy is selected, the remaining copy will be ranked below other features in the next stage because it overlaps completely with the already-selected copy. Without this penalty, greedy selection would choose both copies of the most relevant feature before considering other features.
Michelangelo Palette: Uber’s Feature Store
Uber’s Palette Feature Store, is a centralized database of features, crowdsourced from various teams across the company; a one-stop shop for searching and managing features in Uber.
Palette hosts hundreds of tables, each with up to a thousand different features. It grants engineers and data scientists access to an abundant pool of features, making it easier to create and share features across teams and ingest the features into real time pipelines at production scale.
X-Ray: Mutual Information for the Data Warehouse
X-Ray is an information-theoretic data mining tool developed at Uber AI. Designed for horizontal scalability, X-Ray rapidly discovers and quantifies signals in a dataset that might provide information about outcomes of interest, such as machine learning labels or business KPIs. It is built on top of Apache Spark to take advantage of Spark’s distributed computing framework and seamless integration with data warehouse technologies like Hive.
X-Ray was originally intended for data exploration applications, such as to uncover root causes of software outages in server logs, but this year the X-Ray team expanded its capabilities by adding an information-theoretic feature selection API. This new API is intended to provide Uber with flexible and scalable feature selection capabilities that can keep pace with the growth of the Palette feature store and consolidate internal feature selection tools into a common platform solution.
ML modelers can use X-Ray to automatically identify existing features in the Palette Feature Store that are relevant to their models, and consequently avoid the need to build new features. Conversely, X-Ray helps consolidate any features used in a model that overlap (are redundant) with existing features in Palette.
Optimal Feature Discovery
Methodology
Optimal feature discovery is an automated process to help customer teams find a compact, performant feature set for their supervised learning problems. We have applied this process on multiple projects and observed great results: we’re able to reduce total feature counts by 50% while preserving and even improving the accuracy of the model.
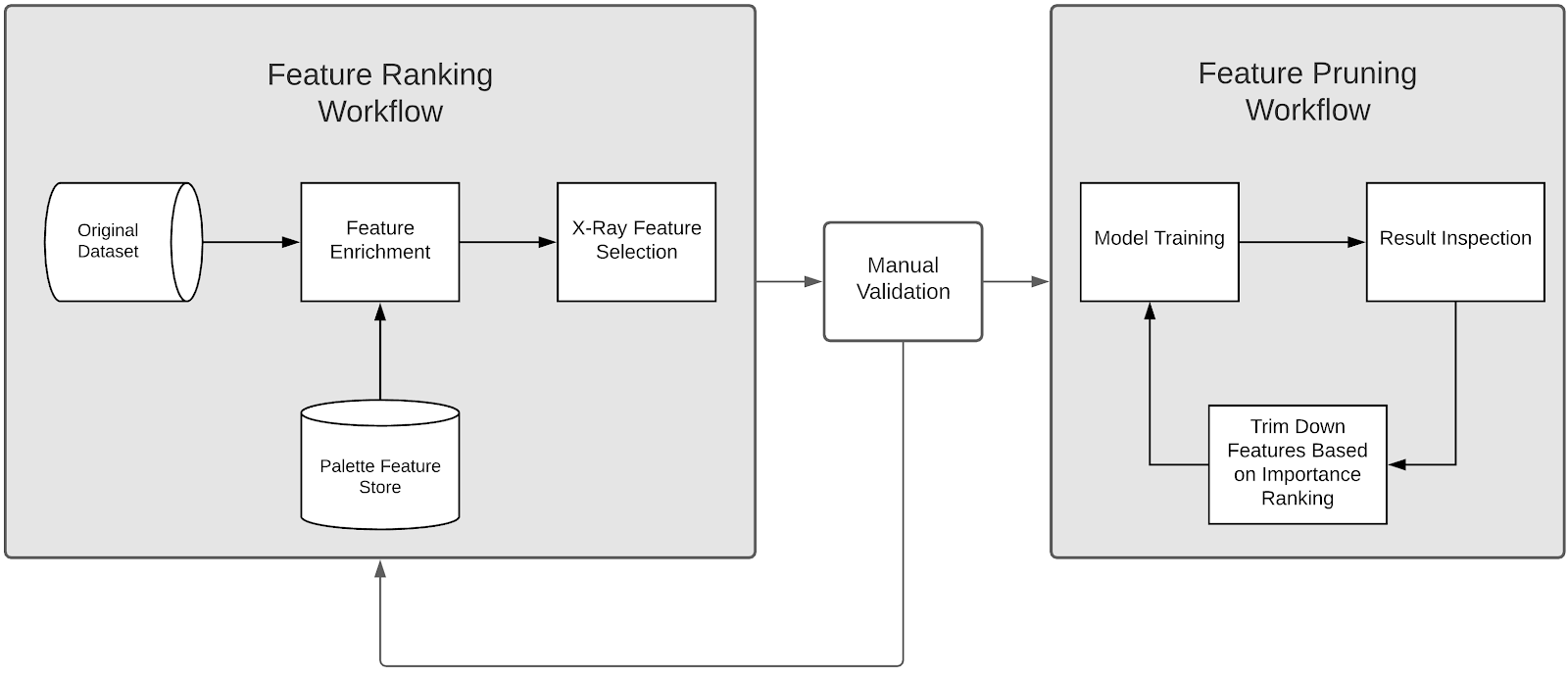
Optimal feature discovery uses two separate, automated workflows: feature ranking and feature pruning. Breaking feature discovery into two workflows gives data scientists a chance to make sanity checks for leakage or potential compliance issues after ranking and before pruning.
Feature Ranking
- Feature Ranking starts with a baseline dataset containing all of a model’s existing features and labels.
- The baseline dataset is joined with all other applicable features in the Palette store, often increases the total number of features into the tens of thousands. This step can also be configured to exclude certain features or tables from Palette as needed.
- Finally we run the X-Ray feature selection engine to produce a large ranked set of candidate features.
Feature Pruning
After features are ranked and verified by data scientists, competing models are trained with different numbers of top k candidate features , and the best performing model is selected in terms of validation accuracy.
Case Study
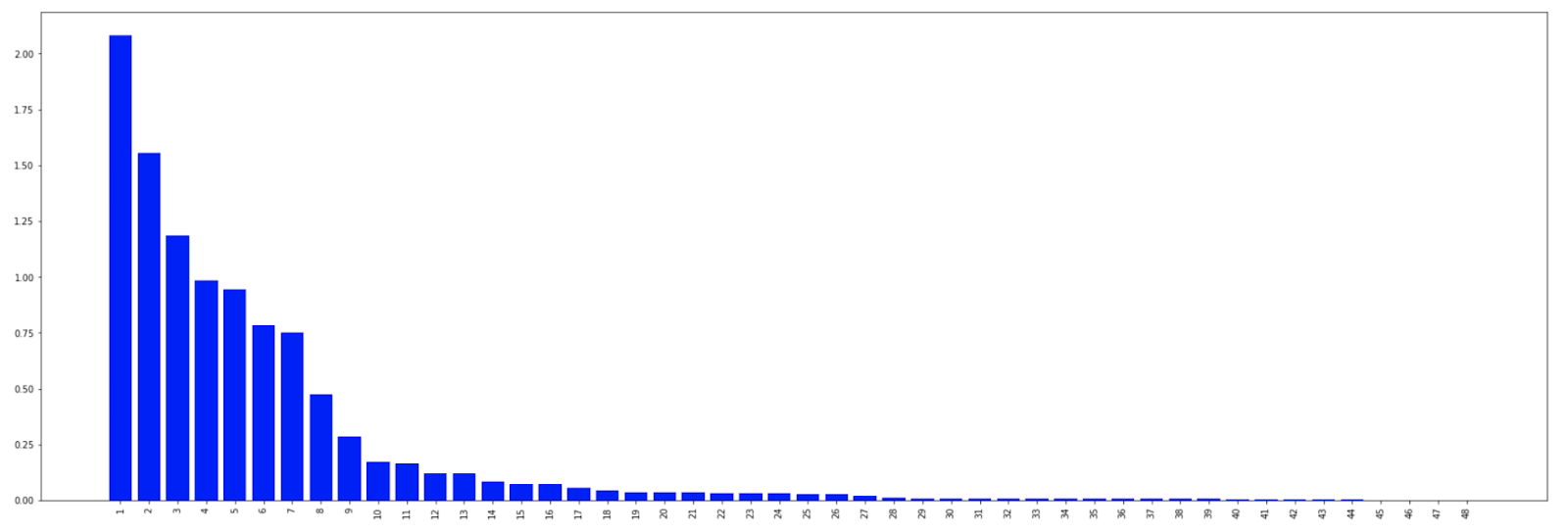
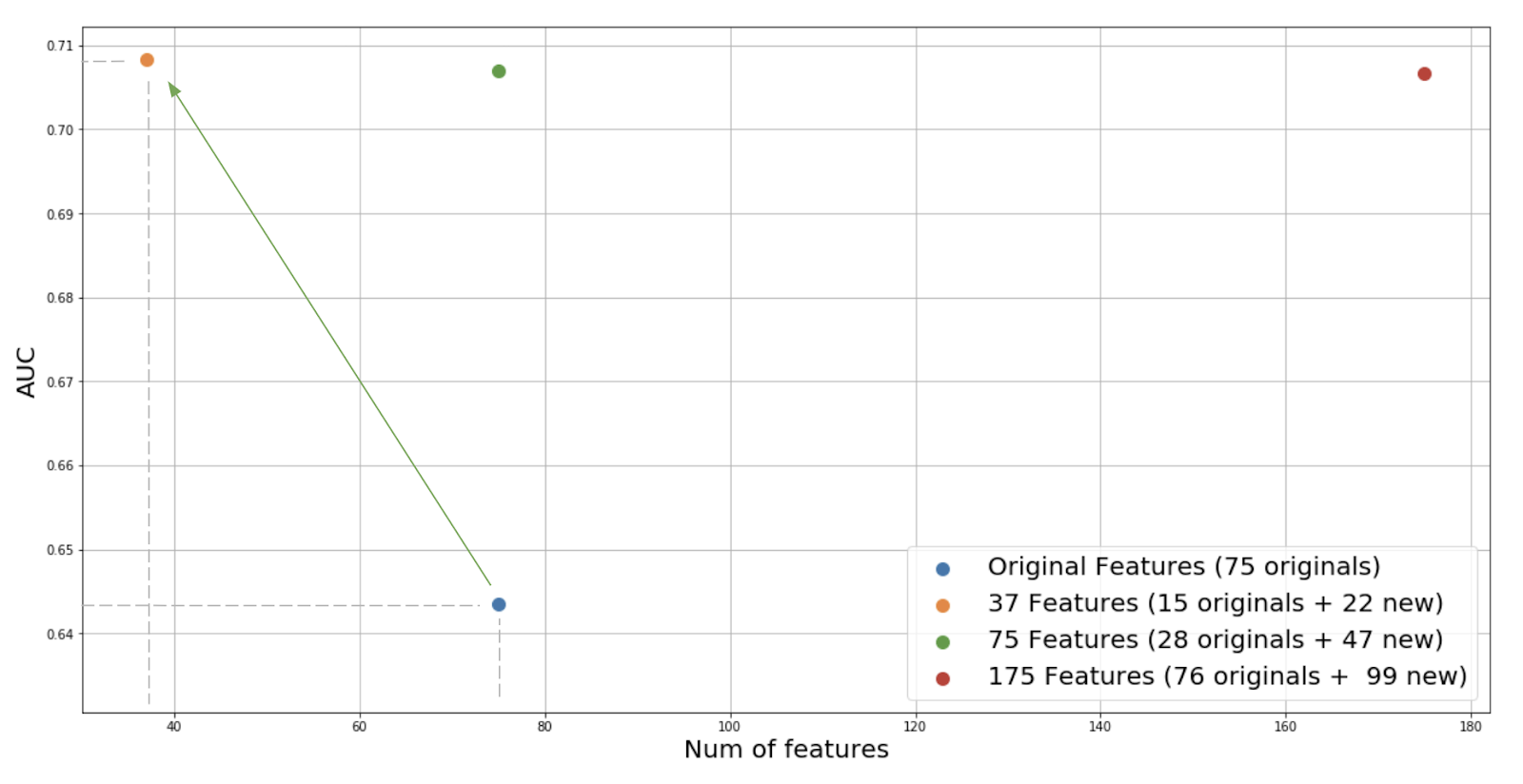
Below is an experiment we ran recently on one of our business-critical models. The problem is a binary classification problem, and the baseline model is a Random Forest with 75 features. Applying the optimal feature discovery process, we first joined the original dataset with an additional 2k+ features found in the feature store, then applied the Minimum Redundance Maximum Relevance (MRMR) algorithm to rank the top 100 features given the prediction target. After acquiring the model-agnostic feature ranking, we went to train the model and iteratively trim down the number of selected features.
Interestingly, as shown in the plot, we were able to reach significantly higher performance, but also reduce the number of features by half. The new 37 features consist of 15 from the original set and 22 newly introduced by X-Ray from Palette feature store. A smaller feature set has advantages like lower engineering complexity, fewer dependencies, lower storage cost and serving latency, etc.
We think there are multiple reasons behind the gain. One is that X-Ray is able to identify features with more prediction power from a large pool of candidates. Second, because the MRMR is able to penalize the redundance among features, the whole process removes spurious features which saves the model from overfitting.
Future Work
Future extensions to this work include consolidating redundant features in the Palette feature store into a common set of features, automated feature engineering and transformation, support for embeddings and structured data, and improved information-theoretic feature selection algorithms that go beyond the pairwise approximations used in MRMR.
If you find the idea of working on large-scale ML systems exciting, Uber AI is hiring!
Apache®, Apache Spark and Spark are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
“satellite dishes” by fennfoot is licensed with CC BY-SA 2.0. To view a copy of this license, visit https://creativecommons.org/licenses/by-sa/2.0/
References
[1] C. E. Shannon, “A mathematical theory of communication,” in The Bell System Technical Journal, vol. 27, no. 3, pp. 379-423, July 1948, doi: 10.1002/j.1538-7305.1948.tb01338.x.
[2] Brown, G., Pocock, A., Zhao, M.-J., & Luján, M. (2012). Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. Journal of Machine Learning Research: JMLR, 13(2), 27–66.

Adam Wang
Adam Wang is a software engineer at Uber AI on the Machine Learning Platform (Michelangelo).

Olcay Cirit
Olcay Cirit is a Staff Research Scientist at Uber AI focused on ML systems and large-scale deep learning problems. Prior to Uber AI, he worked on ad targeting at Google.

Amit Nene
Amit Nene leads the Feature Engineering efforts within the Uber AI Machine Learning Platform (Michelangelo). Previously, he led real-time data engineering efforts within Uber’s Risk team.

Niel Teng Hu
Niel Teng Hu is a former software engineer at Uber AI working on applied machine learning and ML systems.
Posted by Adam Wang, Olcay Cirit, Amit Nene, Niel Teng Hu
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global



Most popular

Stopping Uber Fraudsters Through Risk Challenges

Scaling AI/ML Infrastructure at Uber

Information for driving during the week of Super Bowl LVIII

Uber Reveals 2023 “Airport of the Year” Award Winners
Products
Company
