Improving Driver Communication through One-Click Chat, Uber’s Smart Reply System
September 28, 2018 / Global
Imagine standing curbside, waiting for your Uber ride to arrive. On your app, you see that the car is barely moving. You send them a message to find out what’s going on.
Unbeknownst to you, your driver-partner is stuck in traffic en route to your pick-up location. They receive your message and want to reply back. This scenario is something Uber driver-partners tell us is a pain point. So we began thinking, what if it were possible for people who drive to communicate with riders with one simple click.
The result of our efforts is a new smart reply feature called one-click chat (OCC). With OCC pre-trip coordination between riders and driver-partners is faster and more seamless. Leveraging machine learning and natural language processing (NLP) techniques to anticipate responses to common rider messages, Uber developed OCC to make it easier for driver-partners to reply to in-app messages.
OCC, one of the latest key enhanced features of UberChat, aims to provide Uber’s driver-partners with a one-click chatting experience by offering the most relevant replies.
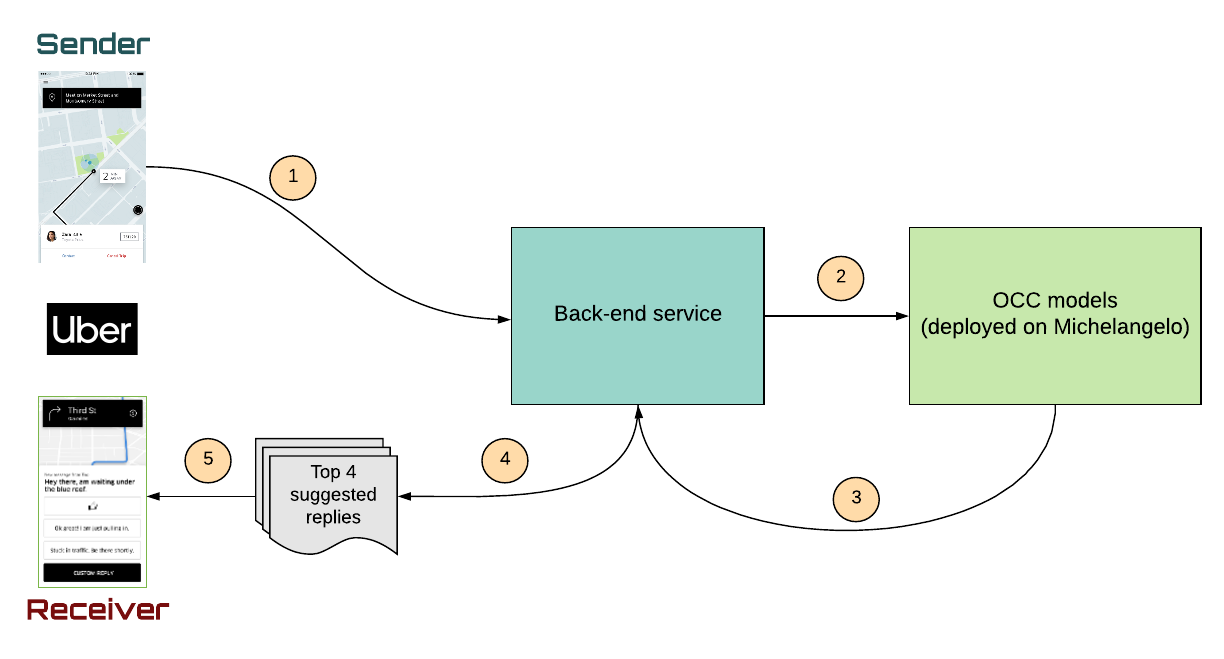
One-click chat architecture
One-click chat (OCC) leverages Uber’s machine learning platform, Michelangelo, to perform NLP on rider chat messages, and generate appropriate responses. As depicted in Figure 2, below, the architecture follows a five-step flow:
- Sender side (rider app) sends a message.
- Once our back-end service receives the message, it sends it to the machine learning service in Michelangelo.
- The machine learning model preprocesses and encodes the message, generates prediction scores for each possible intent, and sends them back to the back-end service.
- Once the backend service receives the predictions, it follows reply retrieval policy to find the best replies (in this case, the top four).
- Receiver side (driver-partner app) receives the suggestion and renders them on the app for the driver-partner to tap.
To find the best replies to each incoming message, we formulate the task into a machine learning solution with two major components: 1) intent detection and 2) reply retrieval.
Consider this example, shown in Figure 3, below, to better understand how machine learning enables the OCC experience:
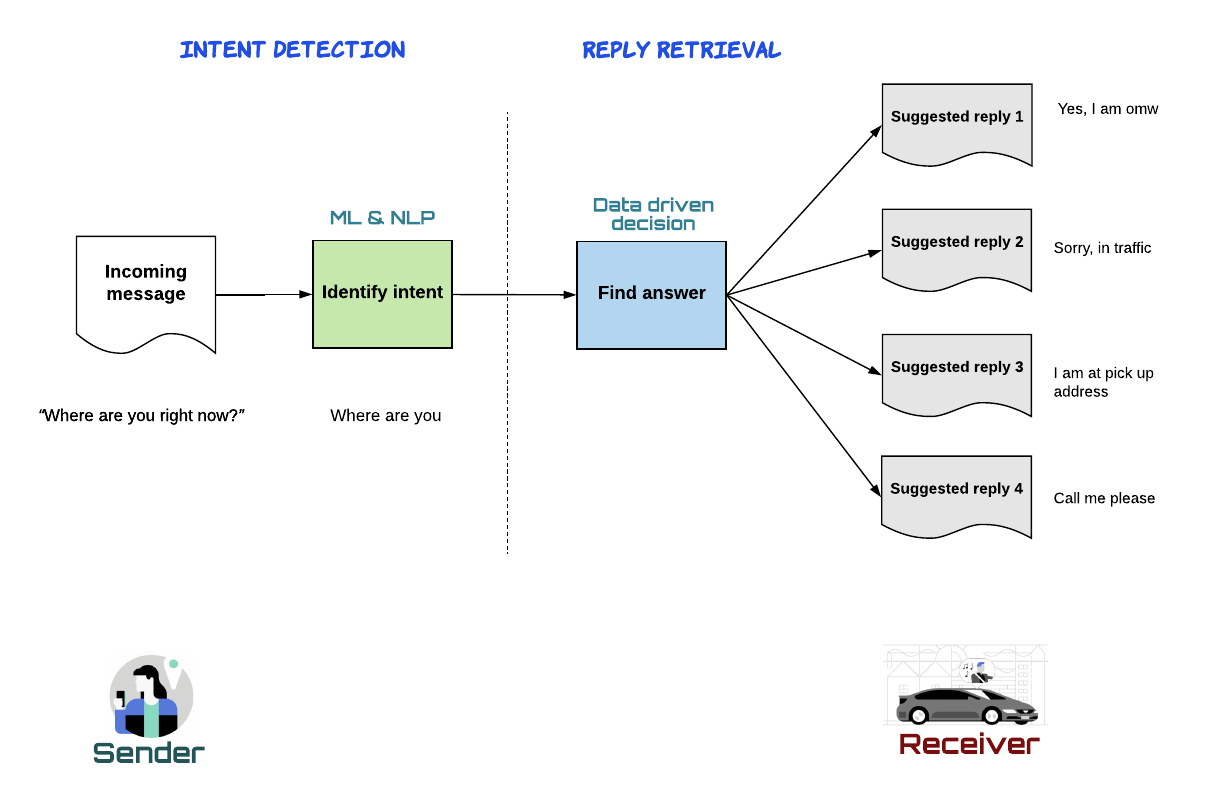
The driver-partner receives an incoming rider message asking “Where are you right now?”, which is very common during pickup time. The OCC system first detects the intent of the message as “Where are you?” This step is called intent detection. The system then surfaces the top four most relevant replies to the driver-partner, which are “Yes, I am on my way”, “Sorry, still in traffic”, “I am at your pick-up address”, and “Call me please”. This is the reply retrieval step. Now, the driver-partner can select one of these four replies and send it back to the rider with a single tap.
Implementing OCC in UberChat
Our UberChat system allows in-app communications for drivers-partners, riders, eaters, and delivery-partners on the Uber platform. The current flow follows standard messaging systems: we expect the sender to type their messages, which then get passed along to the receiver. Figure 4, below, shows the overview of UberChat system with a typical message flow:
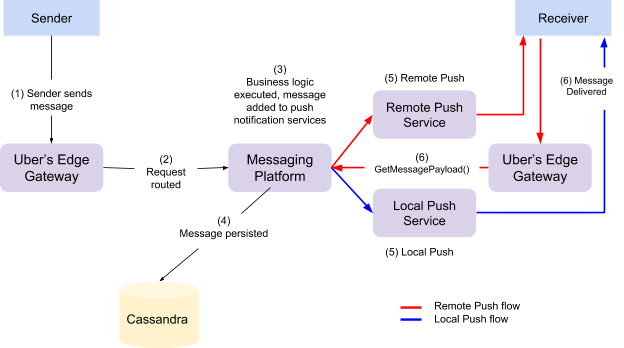
For every message that a user sends, Uber’s messaging platform (UMP) does the following (as shown in above Figure 4):
- Push Sender’s message to Uber’s Edge Gateway
- Route message to Uber’s Messaging Platform
- Add message to the push notification services
- Persist message to Uber’s storage Cassandra cluster
- Perform Remote and Local push to surface message to Receiver
- Fetch message body from Messaging Platform once the message is received
To support smart replies, we need the ability to score the replies in real time using machine learning models in a timely fashion with low enough latency. To meet this need, we leverage the machine-learning training and serving pipelines in Uber’s in-house machine-learning platform Michelangelo.
Delivering smart replies with machine learning in UberChat
By design, OCC aims to provide an easy chat experience for driver-partners during the rider pick-up period, an Uber-specific scenario and topic domain. However, it does share a technical challenge with all other attempts to understand common text messages: not only are they short, but they also contain abbreviations, typos, and colloquialisms. We designed our machine learning system with that challenge in mind.
From the outside looking in, OCC takes in the latest incoming message and returns possible replies, but there is much more going on behind the scenes. There are two main workflow streams powering the OCC ML system, offline training and online serving, outlined in Figure 5, below:
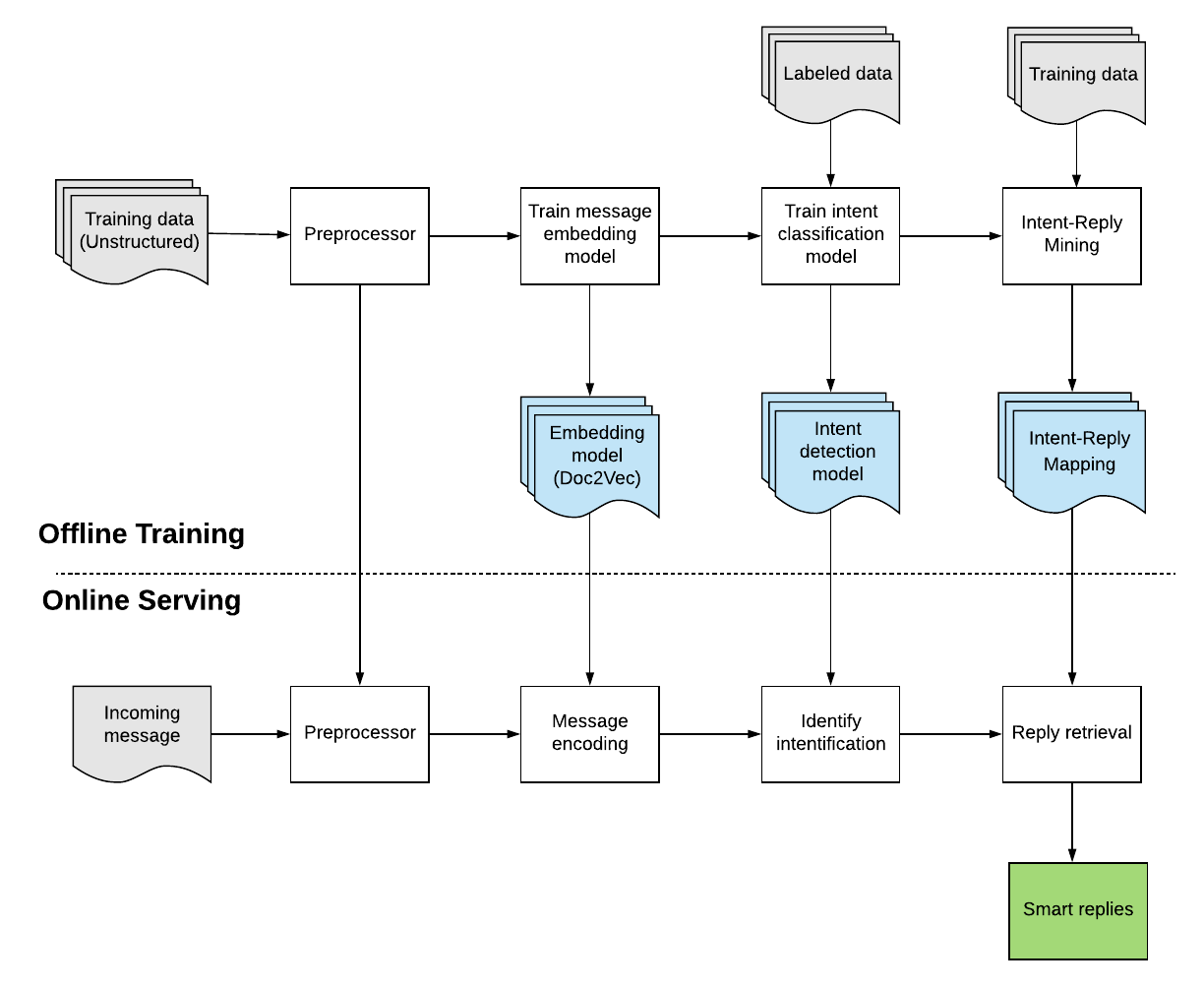
Offline training
During offline training, we used the following embedding-based ML and NLP pipeline to handle these text messages:
Preprocessor
To prepare training data for the text embedding model, we leveraged anonymized UberChat messages. We first partition the chat messages by language (language detection) and conduct length truncation (length <= 2). Finally, we tokenize each of these messages.
Text and message embedding
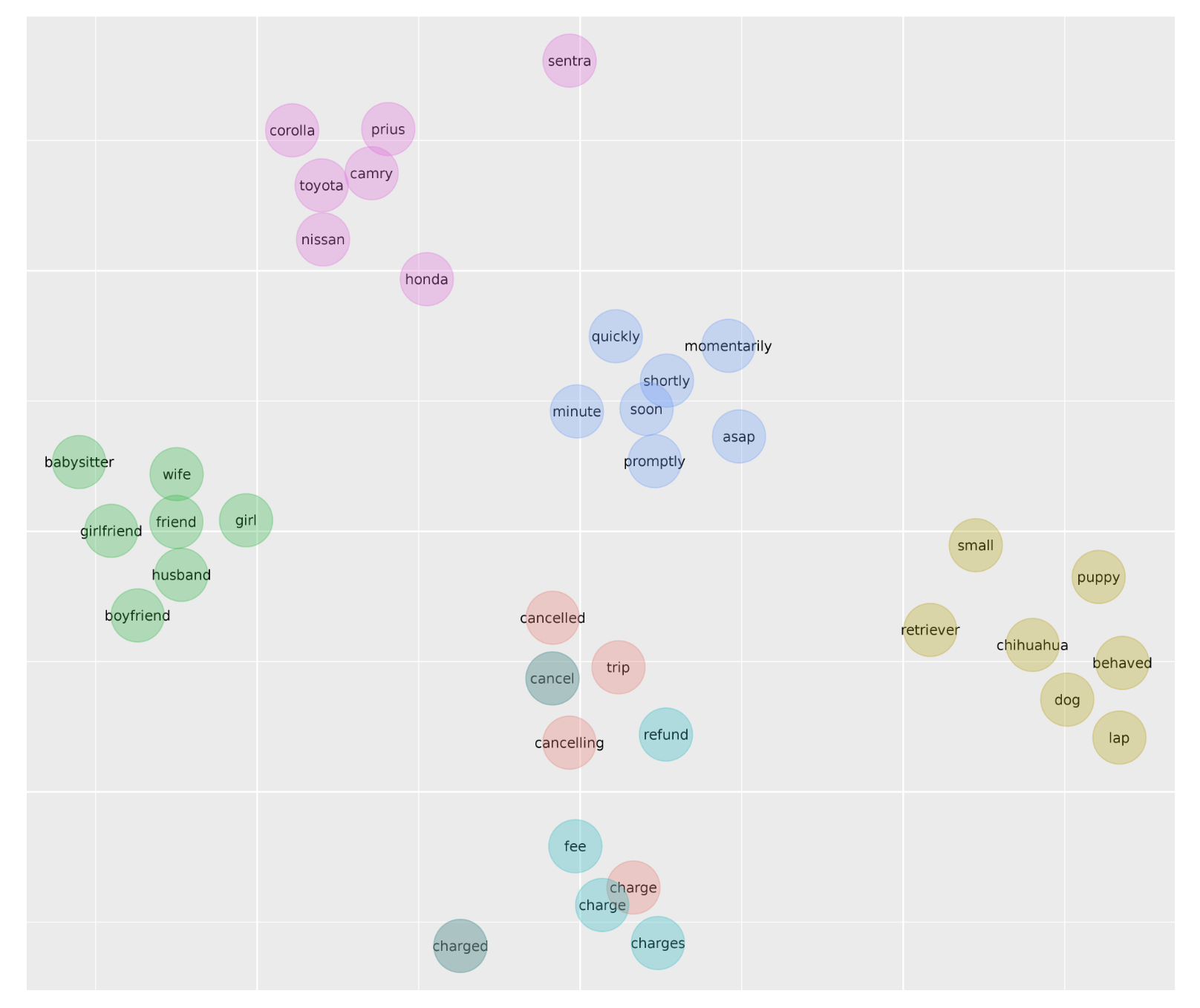
After preprocessing, we performed message embedding using the Doc2vec model, an unsupervised algorithm proposed by Le and Mikolov (2014), that learns fixed-length feature representations from variable-length pieces of text, such as sentences, paragraphs, and documents. We trained the Doc2vec model on millions of anonymized, aggregated UberChat messages and used that training to map each message to a dense vector embedding space. The two major advantages of Doc2vec that suited our needs are that it captures both the ordering and the semantics of words. Figure 6, below, visualizes the word vectors in a two-dimensional projection using a t-SNE plot. Since it captures the semantic meaning of words, the model can cluster similar words together. For example, “Toyota” is close to “Prius” and “Camry”, but far away from “chihuahua.”
Intent detection
To understand user intent, we trained our intent detection model after the embedding procedure. Similar to Gmail’s Smart Reply feature, we formulate the intent detection task as a classification problem.
Why do we need intent detection? Human language is rich. There are many ways to ask the same question, such as “Where are you going?”, “Where are you heading?”, and “What’s your destination?” Chat messages add a level of complexity, with typos and abbreviation adding even more permutations.
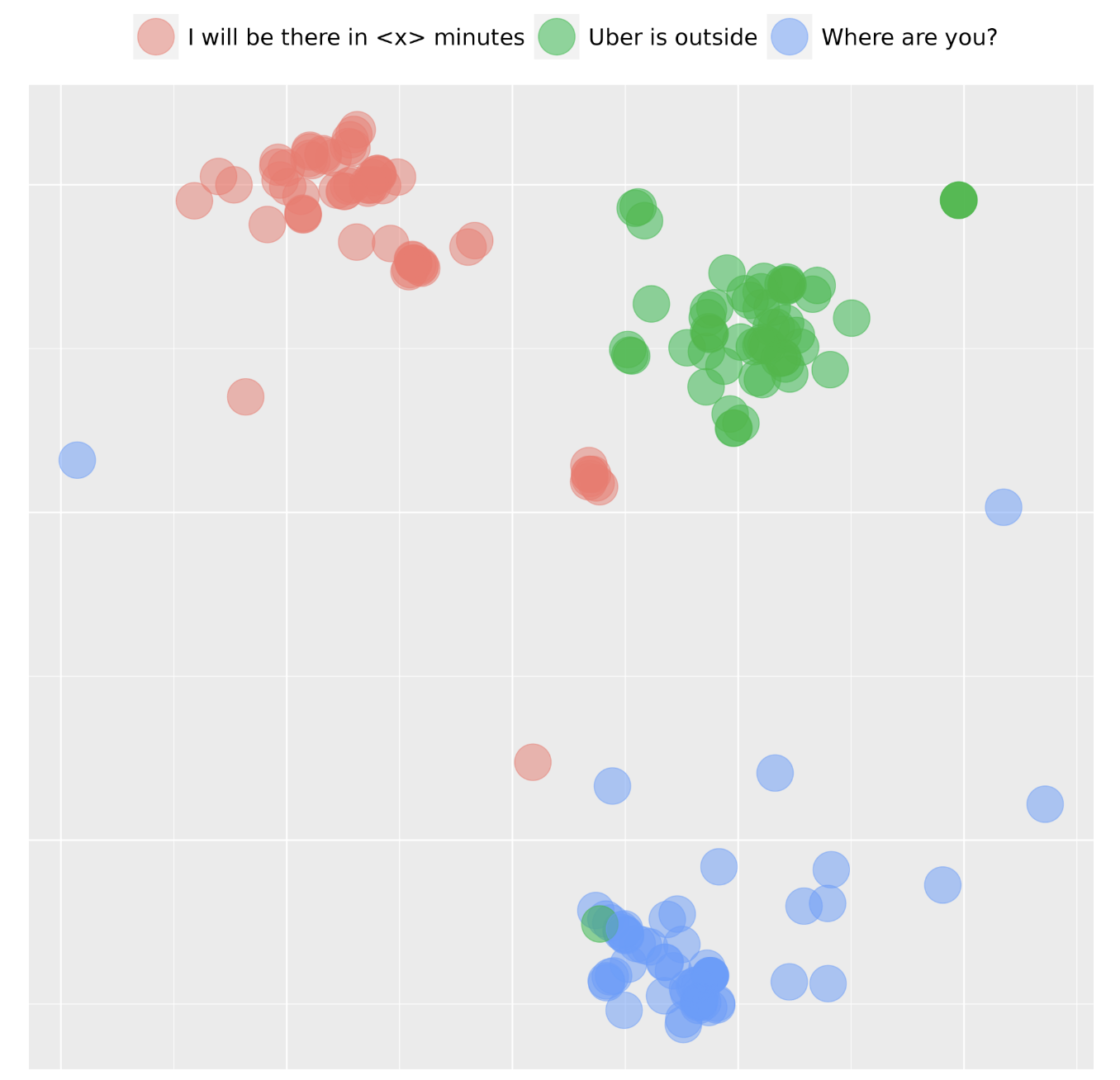
Creating a system with replies for millions of individual questions would not scale, so we need a system that can identify the intent or topic behind each question, letting us provide replies to a finite set of intents. Figure 7, below, illustrates how different messages cluster together based on the detected intents:
Intent-reply mapping
We leverage anonymized and aggregated historical conversations to find the most frequent replies for each intent. After that, our communication content strategist and legal team performs one more round of augmentation to make the replies as easily understood and accurate as possible. Then, we create the intent-reply mapping for reply retrieval.
Online serving
Online serving is relatively straightforward once we have completed the models’ offline training. We take the latest incoming message and send them through the same preprocessor as the offline counterpart. The preprocessed message will be encoded as a fixed-length vector representation via the pre-trained Doc2vec model, after which we use the vector and the intent detection classifier to predict the message’s possible intent.
Finally, by leveraging our intent-reply mapping, we retrieve the most relevant replies based on the detected intent and surface them to the driver-partner receiving the message. In addition, some corner cases will be covered by rules rather than algorithms, including very short messages (truncated message in the preprocessing stage), emojis, and low confidence predictions (multi-intent use cases).
Next steps
We plan to continue expanding the one-click chat feature to other languages, across our global markets. We are also looking into more Uber-specific contextual features like map and traffic information and plan to incorporate them into our existing model. These updates will increase our likelihood of more accurately identifying user intent and surfacing customized replies to better assist driver-partners: in short, making the Uber experience more magical.
Additionally, while the current system uses static intent-reply mapping to retrieve replies, we plan to build a reply retrieval model to further improve the precision of the OCC system.
At a high level, OCC is a natural application of a multi-turn dialogue system, as driver-partners and riders can converse over multiple turns of a conversation before they find each other. Leveraging OCC and other features, build a dialogue system to optimize for the long-term reward of a successful pick-up and chat experience, ultimately leading to a better user experience on our platform.
OCC is only one out of a multitude of different NLP / Conversational AI initiatives at Uber. For example, NL is also utilized for improving customer care at Uber [1, 2] and lies also at the core of hands-free pick-ups, where we will soon start testing voice-activated commands.
Acknowledgements
OCC is a cross-functional collaboration between Uber’s Conversational AI, Applied Machine Learning, Communications Platform, and Michelangelo teams, with contributions from Chandrashekar Vijayarenu, Bhavya Agarwal, Lingyi Zhu, Kailiang Chen, Han Lee, Jerry Yu, Monica Wang, Manisha Mundhe, Shui Hu, Jeremy Lermitte, Zhao Zhang, Hugh Williams, Lucy Dana, Summer Xia, Tito Goldstein, Ann Hussey, Yizzy Wu, Arjun Vora, Srinivas Vadrevu, Huadong Wang, and Karan Singh. We would also like to express our appreciation to team leadership, especially Gokhan Tur, Arun Israel, Jai Ranganathan, Arthur Henry, Kate Zhang, and our Eng Blog team, Molly Vorwerck and Wayne Cunningham.
Interested in developing cutting edge natural language processing or other machine learning systems? Consider applying for a role on our team!
Subscribe to our newsletter to keep up with the latest innovations from Uber Engineering.

Yue Weng
Yue Weng is a senior data scientist on Uber's Conversational AI team working on projects in the domains of deep learning, natural language processing, conversational AI systems, streaming analytics, and real-time monitoring systems.

Huaixiu Zheng
Huaixiu Zheng is a senior data scientist at Uber, working on projects in the domains of deep learning, reinforcement learning, natural language processing and conversational AI systems.

Anwaya Aras
Anwaya is a software engineer on Uber's Communications Platform team. Prior to her current role, she was a fraud engineer on Uber's Risk & Safety team.

Franziska Bell
Fran Bell is a Data Science Director at Uber, leading platform data science teams including Applied Machine Learning, Forecasting, and Natural Language Understanding.
Posted by Yue Weng, Huaixiu Zheng, Anwaya Aras, Franziska Bell
Related articles





Most popular

Case study: Tri-Rail’s role in paving the way for effortless commuting

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore

How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache

Ensuring Precision and Integrity: A Deep Dive into Uber’s Accounting Data Testing Strategies
Products
Company
