
Uber’s software architectures consists of thousands of microservices that empower teams to iterate quickly and support our company’s global growth. These microservices support a variety of solutions, such as mobile applications, internal and infrastructure services, and products along with complex configurations that affect these products at city and sub-city levels.
To maintain our growth and architecture, Uber’s Observability team built a robust, scalable metrics and alerting pipeline responsible for detecting, mitigating, and notifying engineers of issues with their services as soon as they occur. Specifically, we built two in-data center alerting systems, called uMonitor and Neris, that flow into the same notification and alerting pipeline. uMonitor is our metrics-based alerting system that runs checks against our metrics database M3, while Neris primarily looks for alerts in host-level infrastructure.
Both Neris and uMonitor leverage a common pipeline for sending notifications and deduplication. We will dive into these systems, along with a discussion on our push towards more mitigation actions, our new alert deduplication platform called Origami, and the challenges in creating alerts with high signal-to-noise ratio.
In addition, we also developed a black box alerting system which detects high level outages from outside the data center in cases where our internal systems fail or we have full data center outages. A future blog article will talk about this setup.
Alerting at Uber
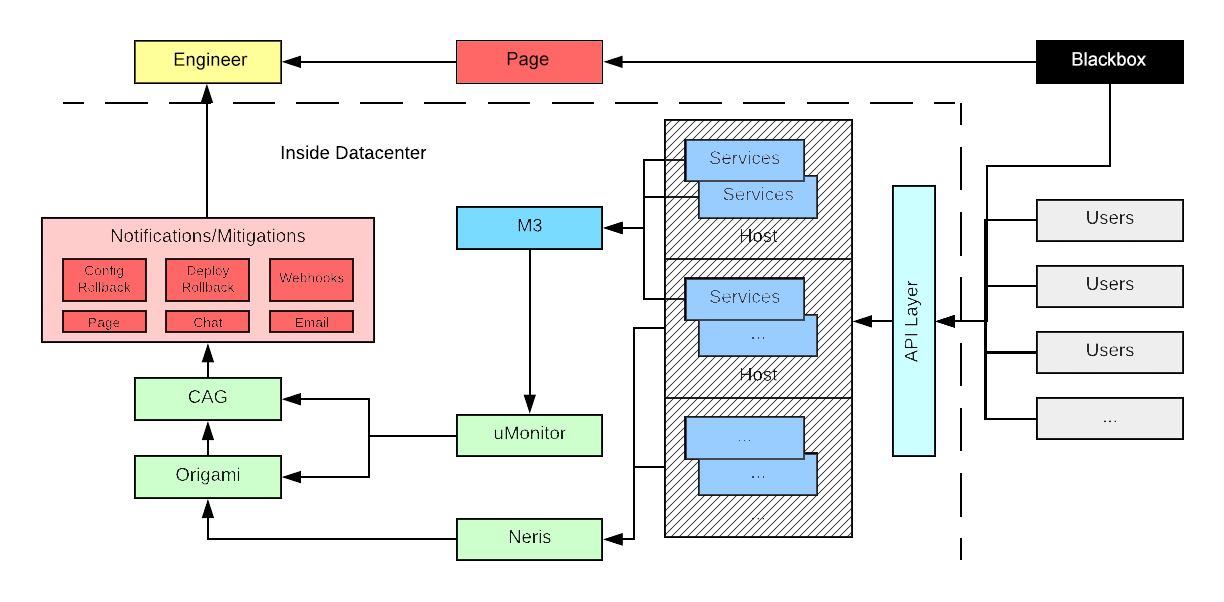
At Uber’s scale, monitoring and alerting requires thinking outside of traditional off-the-shelf solutions. Alerting at Uber started with Nagios, issuing Graphite threshold checks against carbon metrics using source controlled scripts. Due to scalability issues with our Carbon metrics cluster, we decided to build our own large-scale metrics platform, M3. To improve the usability of our alerting system, we developed uMonitor, our homegrown, time series metrics-based alerting system for metrics stored in M3. For metrics not stored in M3, we built Neris to perform host-level alerting checks.
uMonitor was built with flexibility and use case diversity in mind. Some alerts are generated automatically on standard metrics like endpoint errors and CPU/memory consumption. Other alerts are created by individual teams related to metrics specific to their needs. We built uMonitor as a platform to handle these varying use cases, specifically:
- Easy management of alerts: iteration to determine the appropriate functions and thresholds for an alert
- Flexible actions: notifications like paging, emails, and chat. Support for automated mitigations like rolling back back deployments and configuration changes
- Handle high cardinality: be able to alert in response to the smallest scope critical issues, but not inundate teams with notifications on larger outages
Metrics-based alerting with uMonitor
uMonitor has three separate components: a storage service that has alert management APIs and wraps our Cassandra alerts and state store; a scheduler that keeps track of all the alerts and dispatches alert check tasks to workers every minute for each alert; and workers that execute alert checks against the underlying metrics defined by the alert.
The workers maintain alert check state in a Cassandra store and ensure notifications are sent at least once via an aggressive retry mechanism. Workers are also responsible for re-alerting every so often (generally every hour) on alerts continuing to fire. Currently, uMonitor has 125,000 alert configurations that check 700 million data points over 1.4 million time series every second.
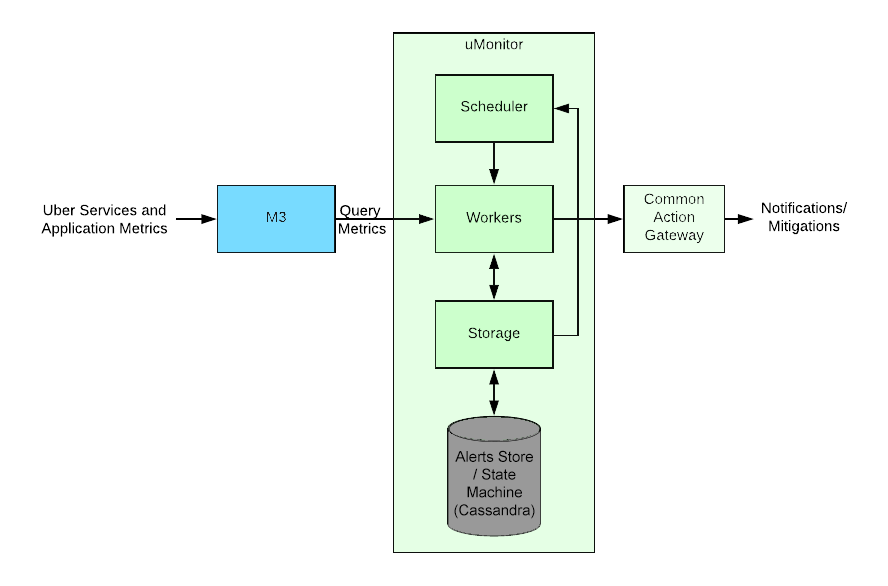
An alert definition has an M3 query (either Graphite or M3QL) and thresholds that determine whether the alert is violating thresholds or not. A query returns one or more time series from M3, and thresholds are applied to each of the underlying series. Alert actions are sent if the query violates the thresholds. The worker with assistance of state stored in Cassandra maintains a state machine that ensures notifications are sent at least once an alert is triggered, resent periodically while the alert remains triggered, and resolved when the issue is mitigated.
There are two types of thresholds: static thresholds and anomaly thresholds. For metrics that have a particular steady state or we can construct queries that return consistent values by computing values such as success/failure percentages, we generally use static thresholds. For cyclical metrics like trip count per city and other business metrics, uMonitor makes use of Argos, our anomaly detection platform, to generate dynamic thresholds for what would represent anomalous values of metrics based on historical data.
Host alerting with Neris
Neris is our internal host-based alerting system built for high resolution high-cardinality per host metrics not available in our M3 metrics system. The reason for host metrics not being in M3 is twofold. First, checking each of the 1.5 million host metrics generated per minute across 40,000 hosts per data center is more efficient to do on the host as opposed to querying against a central metrics store; as such, the overhead of ingesting and storing the metrics is unnecessary. Second, until recently, M3’s retention policy caused metrics of ten seconds to be stored for 48 hours, and metrics of one minute for 30 days, and there was no need to store host metrics with that retention and resolution. As Nagios required code to be written and deployed for each check, which did not scale as our infrastructure grew, we decided to build a system in-house.
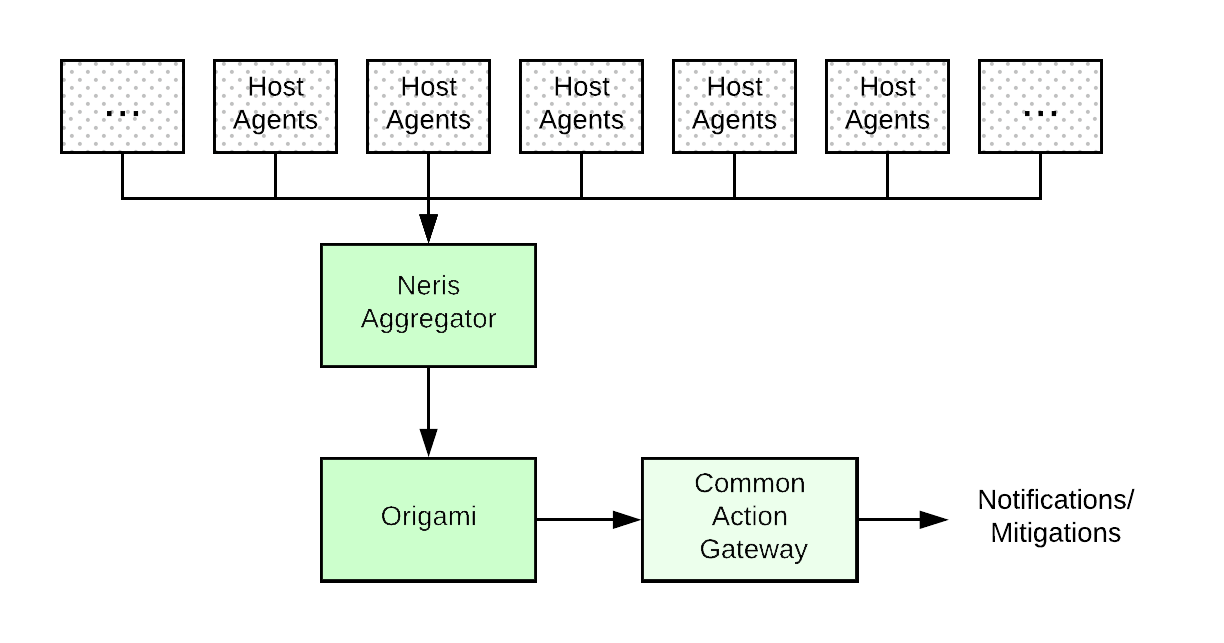
Neris has an agent that runs on every host in our data centers and periodically (every minute) executes alert checks on the host itself. The agent then sends the results of the checks to an aggregation tier which in turn sends the aggregated results to Origami. Origami is responsible for deciding what alerts to send out based on rules that look at the number of failing alerts and criticality of the underlying alerts. Leveraging Origami, Neris runs about 1.5 million checks a minute across our fleet of hosts in each data center.
On agent startup at each host, Neris pulls in alert definition information for the host from a central configuration store called Object Config that is widely used by low-level infrastructure services at Uber. Determining which alerts will run on a given host depends on its role. For instance, the host that runs Cassandra will have checks related to Cassandra’s status, disk usage, and other metrics. Most such host level checks are created and maintained by infrastructure platform teams.
Handling cardinality
High cardinality has always been the biggest challenge for our alerting platform. Traditionally, this was handled by means of having an alert query return multiple series and allowing simple rules around an alert to only fire if more than a certain percentage of series are violating the threshold. uMonitor also allows users to set an alert as being dependent on other alerts – an alert tracking a more scoped issue is dependent on a larger scoped alert, and if the larger scoped alert is firing, the dependent alert is suppressed.
The above techniques worked well as long as queries return a bounded number of series, and the dependencies can be easily defined. However, with Uber growing to operate many different product lines across hundreds of cities, the cardinality challenges have required a more generic solution. We use Origami to assist in handling high cardinality. Origami is used by Neris as its primary deduplication and notification engine and it enables consolidated notifications for uMonitor alerts.
For business metrics, Origami is useful when we need to alert on a per city, per product, per app version basis. Origami allows users to create the underlying alerts/checks for combinations of city, product, and app version, and alert on aggregate policies to receive notifications on a per city/product/app version basis. In the case of larger outages (for instance, when many cities are having issues at the same time), Origami will send rolled up notifications indicating the list of underlying alerts firing.
In the host alerting scenario, Origami gives us the capability to send varying severities of notifications based on the aggregate state of an alert. Let’s consider an example for disk space usage on a Cassandra cluster. In this instance, an Origami notification policy for this could look like:
- Send an email notification if less than three hosts have 70 percent disk usage
- Send a page if greater than three hosts have 70 percent disk usage
- Send a page if one or more hosts have 90 percent disk usage
Alert notifications
Useful alert notifications are the primary challenge in scaling our alerting system. Alert actions started primarily with notifications like paging an on-call engineer for high priority issues, and using chat or email for informational issues. Our focus now has turned to building out mitigation actions. Most incidents and outages happen due to configuration changes or deployments. uMonitor provides first class support for mitigation actions that roll back recent configuration changes and deployments. For teams that have more complex mitigation runbooks, we have support for webhooks which make a POST call against an endpoint with full context about the alert, which in turn can run mitigation runbooks. Additionally, by leveraging our deduplication pipeline in Origami, we can suppress finer granularity notifications on larger outages.
In addition to the above, we have been working to make the notifications more relevant and have them target the right individuals. A recent effort has involved identifying config/deployment change owners and directly contacting them when an alert fires for a service they have modified. We have made additional efforts around providing more context in alert notifications for related service failures by combining trace information from Jaeger along with alerts information.
Alert management
As mentioned earlier, we have strived to build uMonitor as a platform that other teams can build on for specific use cases. Host alerts setup and management is generally specialized and primarily for teams that maintain their own dedicated hardware, and for teams that are building out infrastructure platforms for the company, including storage, metrics, and compute solutions, among others. The alerts are configured in teams’ individual git repositories, which are synced to Object Config.
At a high level, uMonitor has three classes of alerts:
- alerts automatically generated on standard metrics around CPU, disk usage and RPC stats for all services
- one-off alerts created through the UI to detect specific issues
- alerts created and managed through scripts and external configuration systems layered on top of uMonitor
We have seen the greatest growth in the last class of alerts, as teams work to detect alertable issues at the finest granularity possible. The need for this granularity comes down to Uber’s global growth. Code changes to the services supporting Uber’s mobile applications generally roll out to specific groups of cities over a period of a few hours. It is very important that we monitor the health of our platform at the city level to figure out issues before they become more widespread. Moreover, the configuration parameters, controlled by engineering and local ops teams, for each city are different. For example, rider pickups in a city may be blocked on a street due to an ongoing event like a parade, or other events can cause changes in traffic.
Many teams have built out alert generation solutions on uMonitor that tackle such use cases. Some of the challenges these tools solve are:
- Iterating and generating alerts across various dimensions
- Determining alert schedules based on specific business information, such as holidays in specific countries/cities, and configuring that information within uMonitor to prevent spurious alerts
- In cases where static or current anomaly thresholds do not work, determining thresholds based on past data or complex queries on underlying metrics that apply to particular business lines (more on alert queries below)
Additionally many of these solutions generate dashboards that are in sync with the generated alerts.
uMonitor also provides a powerful edit and root cause UI. The edit and experimentation aspect of the UI is critical, as most metrics cannot be used for alerts as-is due to variations and spikes. The Observability team provides guidelines on how to create queries that are more ideal for alerting.
Alert queries
The Graphite query language and M3QL provide a plethora of functions that allow for more customized solutions. Below, we outline some examples of how to make a query return more consistent values in order to make the metrics more alertable:
- Alert on say movingAverage of metrics over a few minutes to smooth out any spikes in metrics
- Combine the above with sustain periods to only send notifications if a threshold violation has persisted for a set amount of time
- For metrics that have up and down patterns, use of derivative functions to ensure the spikes in either direction are not too sudden
- Alerting on percentages/ratios so that the metric is not susceptible to changes in the magnitude of the metrics
Future plans
We have only just gotten started on the road to scale our systems with the ability to detect minute issues and surface only the appropriate information to the user, suppressing unnecessary alerts. Work to enable this is ongoing across all parts of the pipeline, including more efficient collection of metrics, scaling and streamlining the alert execution infrastructure, and building UIs and interfaces that allow correlating information across various sources.
If any of the above makes you want to tackle observability challenges at scale, do consider applying for a role on our team.
Shreyas Srivatsan is a senior software engineer on the Observability team in the Uber New York City engineering office, working on improving Uber’s alerting and monitoring infrastructure.

Shreyas Srivatsan
Shreyas Srivatsan is a senior software engineer on Uber's Observability Engineering team.
Posted by Shreyas Srivatsan
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
