
High quality map data powers many aspects of the Uber trip experience. Services such as Search, Routing, and Estimated Time of Arrival (ETA) prediction rely on accurate map data to provide a safe, convenient, and efficient experience for riders, drivers, eaters, and delivery-partners. However, map data can become stale over time, reducing its quality.
As a customer-obsessed company, Uber reviews and addresses feedback in customer support tickets, which are submitted by riders, driver-partners, eaters, and delivery-partners on the Uber platform. Some of these tickets point out location problems, giving us one means of identifying and fixing errors in our map data.
We serve over 15 million trips per day, so if even a small percentage of those trips trigger a customer support ticket, we end up with a large quantity of tickets. Manually poring over the tickets to find those that point out inaccurate map data would not be scalable. Therefore, we use machine learning (ML) and big data processing to automate this workflow.
To address the problem of large-scale ticket analysis, we built a natural language processing (NLP) platform that looks for map data-related issues in the text of tickets. This platform can then specify which specific type of map data triggered the ticket, so that the appropriate team within our maps organization can assess the issue and determine a solution.
Leveraging our customer support platform
Uber’s in-house customer support platform consists of in-app support, self-service flows, and other technologies to better serve our users by helping agents quickly resolve any issues they encounter. Some issues that arise through our customer support platform are triggered by map data. If our maps contain incorrect data, a rider might be driven to a location miles away from the intended destination or along a sub-optimal route, which causes additional walking and inaccurate trip fare estimation. The rider subsequently files a customer support ticket.
The customer support platform allows our customers to choose categories for their tickets. However, the categories are high level and designed around customer needs, such as “I was involved in an accident,” “Review my fare or fee,” or “I lost an item.” Including categories for each map data type in the customer support flow would be too fine-grained for both customers and customer support representatives.
Lacking upfront categorization, we need to deal with free-form text and detect signals associated with maps from it. In written language, people naturally phrase issues in a variety of ways when submitting a ticket. For example, one person could write that a location is “wrong” while another might describe it as “incorrect” or “off.” Understanding the multiple ways in which people can refer to the same thing is a challenge suited specifically for NLP.
NLP and ML algorithms
The requirement for detecting errors in a map data type can be modeled as a classification problem in machine learning, in which a classification model will predict the probability that a ticket is related to errors in the map data type based on its learning from training data. We start with Logistic Regression (or Softmax, if multiclass classification fits better for our use case) for our first version algorithm.
Logistic Regression takes numerical vectors as its input. Therefore, we need to encode a ticket, including free-form text and contact type (category), into a numerical vector. For free-form text, a naive approach would be to use a pre-defined vocabulary to encode by word frequency. That approach would make the vector sparse and require much more training data to train the classification model effectively, which is infeasible in most cases. Therefore, we want to embed the text of a ticket into a dense vector such that similar tickets will be close to each other in the embedding vector space.
For the first version algorithm, we used Word2Vec for word embedding, in which the embedding model is trained for predicting a context (nearby) word from a target word, and semantically similar words will be close to each other in the embedding space. After mapping the words to vectors, the vector for the text of a ticket is the average of the word vectors in the ticket. For contact type, each contact type has a UUID, and we use one hot encoding to encode the contact type uuid of a ticket. The final vector for a ticket is the concatenation of its embedding word vector and its contact type one hot vector.
During preprocessing, we denoise tickets by removing HTML, punctuation, and stop words before feeding tickets into the neural network. The algorithm is summarized in Figure 1, below:
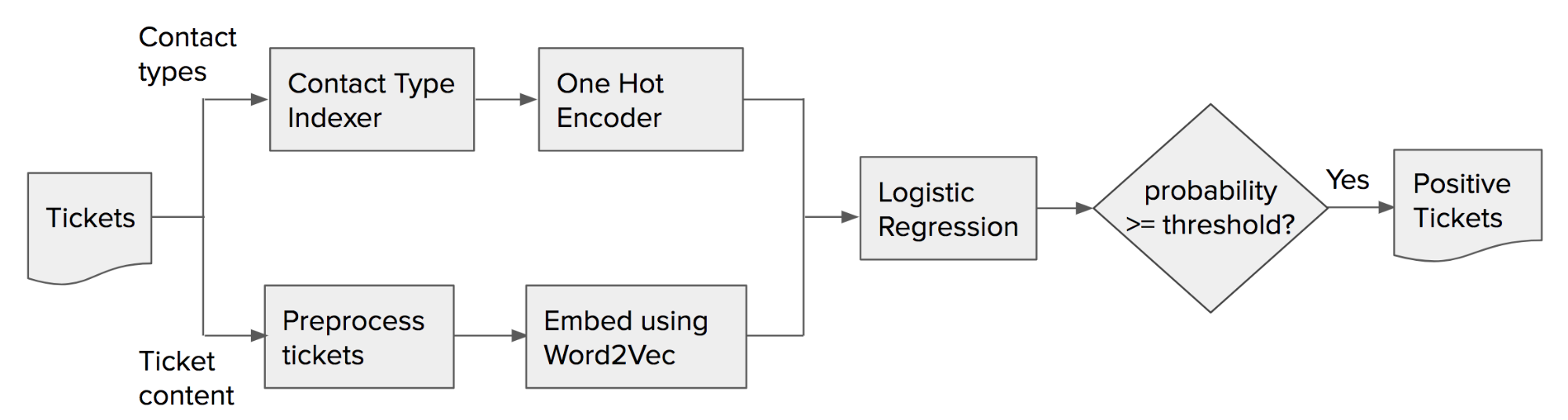
Note that we can interpret the output of logistic regression as the probability that the ticket is related to errors in the map data type and set the threshold for desired precision-recall trade-off. We defined positive tickets as the tickets whose probability is larger than or equal to the threshold.
The main challenge of the machine learning algorithm is the technical cost of building training data. Given that there is no contact type for each map data type, we have to manually label sample tickets. Typically, an individual has the bandwidth to label about 10,000 to 20,000 tickets over a three to six-month period.
Fortunately, training the word embedding is unsupervised, and we train the Word2Vec embedding on one million randomly sampled tickets. We have tried GloVe embeddings pre-trained on Wikipedia, but found that training word embeddings with customer tickets themselves yields better performance, probably because the language characteristic in the specific domain is learned by the model.
The version 1 algorithm has its limitations. First, we restricted ourselves to use the average when combining word vectors of a ticket. All words are treated equally and there is no attention to important words. Second, the word embedding is fixed once we have trained it in an unsupervised way, and it cannot be tuned to optimize the classification task. Because of these limitations, we experimented with deep learning models such as WordCNN and LSTM.
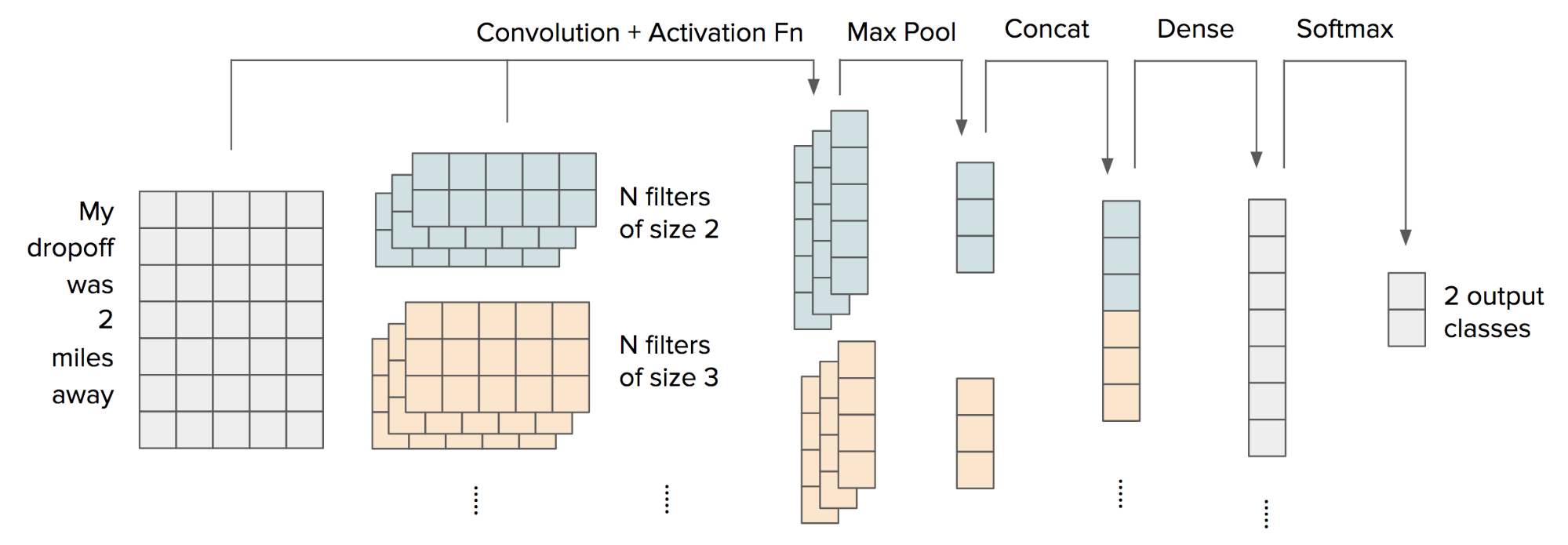
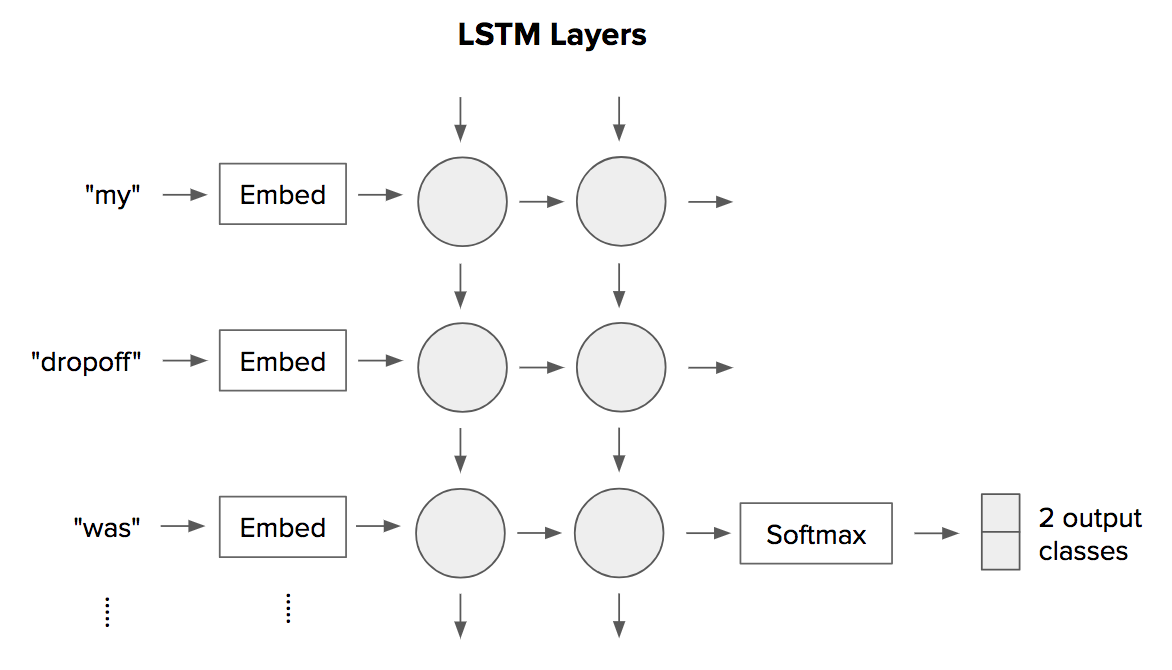
A summary of model performance on binary classification of a map data type is shown in the table below. Each result is the average of ten simulations to minimize the influence of any one training/evaluation/test split. For each model type, either Word2Vec trained on customer tickets, GloVe trained on Wikipedia, or randomly generated embeddings were evaluated. For each neural network type, these embeddings were either kept fixed or allowed to be fine-tuned (trainable = “yes”). The main performance measures used are “AUC_ROC” = area under ROC curve, “AUC_PR” = area under precision-recall curve, and the recall value @ precision = 0.5 (for a more intuitive understanding of the model’s sensitivity at a given precision level).
| Embeddings | Model | AUC ROC | AUC PR | recall @ precision = 0.5 | |
| Type | Trainable | ||||
| random | Yes | LSTM | 0.794 | 0.519 | 0.528 |
| No | 0.628 | 0.297 | 0.062 | ||
| Word2Vec | Yes | 0.791 | 0.502 | 0.533 | |
| No | 0.796 | 0.527 | 0.538 | ||
| GloVe | Yes | 0.785 | 0.521 | 0.568 | |
| No | 0.773 | 0.494 | 0.519 | ||
| random | Yes | WordCNN | 0.840 | 0.612 | 0.669 |
| No | 0.822 | 0.596 | 0.608 | ||
| Word2Vec | Yes | 0.849 | 0.620 | 0.688 | |
| No | 0.842 | 0.615 | 0.646 | ||
| GloVe | Yes | 0.836 | 0.601 | 0.642 | |
| No | 0.831 | 0.588 | 0.627 | ||
| random | No | LR | 0.636 | 0.335 | 0.124 |
| Word2Vec | No | 0.810 | 0.526 | 0.536 | |
| GloVe | No | 0.788 | 0.486 | 0.435 | |
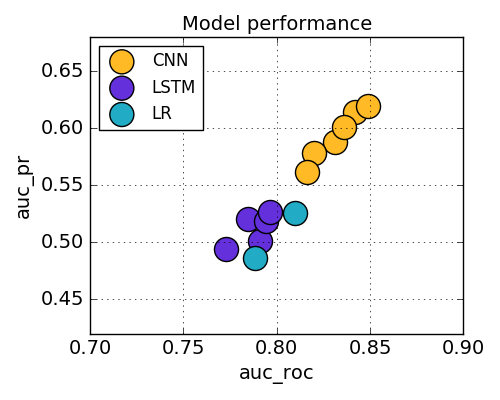
It turns out that using WordCNN with trainable embeddings initialized by Word2Vec trained on customer tickets yields the best performance. This result makes sense, because the application is more like keyword spotting and activation than language model or sequence generation, and WordCNN models the former better and LSTM models the latter better. In other words, we care more about the presence of certain phrases and the order of words. Therefore, we decided to use WordCNN as our version 2 algorithm.
Word embedding visualization
Each word is mapped to a vector with 300 dimensions. We use dimensional reduction technology such as t-SNE and PCA to reduce the dimension of word vectors to three so that we can visualize them in 3D. We can then verify that semantically similar words are close to each other in the 3D plot. In addition, we can find each word’s synonyms, that is, the closest words in the embedding, measured by cosine distance or Euclidean distance. TensorBoard is a great tool to visualize the word embedding and compute the distance.
The other technique to understand the learned word vectors is synonyms, that is, given a word, find the closet N words, based on Euclidean distance or Cosine distance in the embedding space. We can use the analysis to verify the word semantics with our common sense, making sure the word embedding is trained properly.
Sample synonyms from our word embedding model:
| Synonyms of pickup | Cosine Distance | Synonyms of airport | Cosine Distance | |
| dropoff | 0.605 | international | 0.340 | |
| ministry | 0.609 | terminal | 0.360 | |
| 3720 | 0.616 | delta | 0.415 | |
| destined | 0.616 | mco | 0.424 | |
| pinned | 0.616 | jetblue | 0.432 | |
| Synonyms of st | Cosine Distance | Synonyms of building | Cosine Distance | |
| ave | 0.183 | alley | 0.283 | |
| pl | 0.244 | apartment | 0.525 | |
| avenue | 0.277 | condo | 0.530 | |
| broadway | 0.299 | complex | 0.537 | |
| Synonyms of highway | Cosine Distance | Synonyms of 4th | Cosine Distance | |
| freeway | 0.175 | 5th | 0.226 | |
| interstate | 0.248 | 6th | 0.232 | |
| ramp | 0.303 | 9th | 0.240 | |
| Synonyms of north | Cosine Distance | Synonyms of maps | Cosine Distance | |
| south | 0.223 | waze | 0.274 | |
| west | 0.383 | 0.292 | ||
| east | 0.385 | navigation | 0.444 | |
| mockingbird | 0.408 | navigator | 0.475 | |
| Synonyms of sf | Cosine Distance | |||
| oakland | 0.285 | |||
| francisco | 0.333 | |||
| berkeley | 0.350 | |||
| san | 0.395 | |||
| sfo | 0.436 | |||
System design and architecture
To support prediction at large scale, we implement the algorithm described above in Spark, which partitions big data and leverages distributed/parallel computing. The architecture of the systems for the version 1 and version 2 algorithms are shown in Figure 4, below.
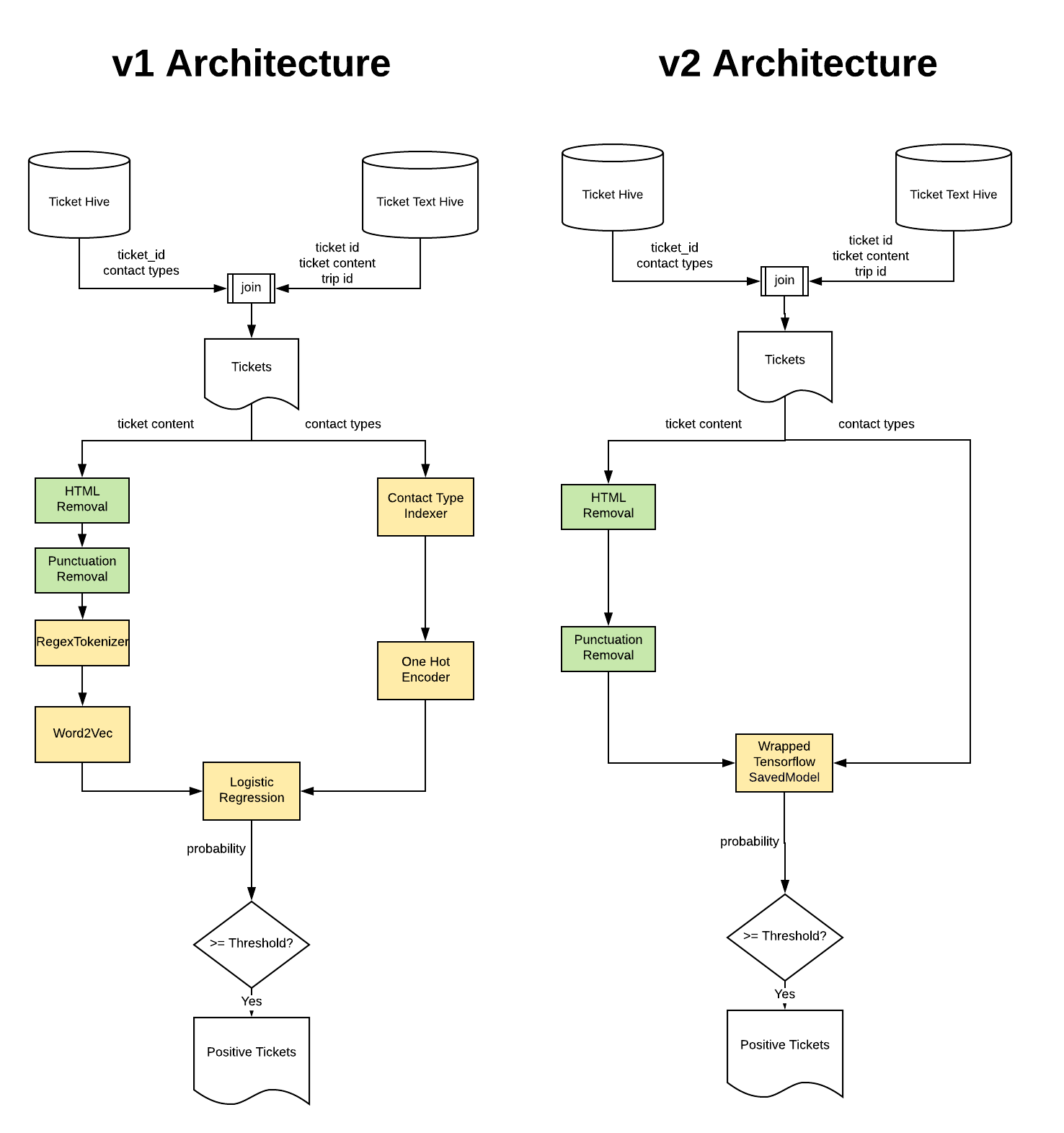
Uber has a Big Data ecosystem that leverages Spark and Hive to enable product teams to store and query data from Hive tables and run Spark pipelines on Uber’s clusters. We implemented our machine learning algorithm as an end-to-end Spark pipeline. The pipeline first uses Spark SQL to query Ticket Hive table, which contains ticket_id and contact types, and Ticket Text Hive table, which contains ticket_id, ticket_content, and trip_id. Then we joined the two data frames and pass the result to the preprocessing stage.
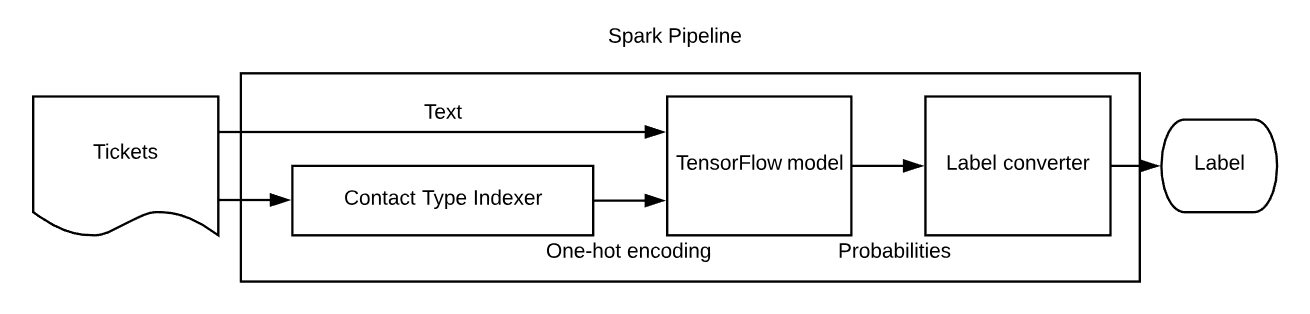
After preprocessing, we use the NLP model, consisting of contact type indexer, contact type one hot encoder, Word2Vec model, and Logistic Regression model, trained and saved as a Spark pipeline model. Using Spark’s ML pipeline paradigm helped us write clean and maintainable code. For the version 2 algorithm, we used TensorFlow, a deep learning framework, to train the WordCNN model offline and save it as a checkpoint. We then exported the trained model as a saved model with TensorFlow’s SavedModelBuilder to be served. In production, we worked with Uber’s Michelangelo team to wrap the SavedModel files as a Spark pipeline model and serve it seamlessly in the end-to-end Spark pipeline, as shown in Figure 5, below:
When a rider submits a ticket, it is automatically associated to a trip, which is the route from pick-up point to drop-off point requested or traveled by the rider. Some map entities are also associable with trips. To further build confidence, we can join positive tickets with map entities by trip, aggregate positive tickets and compute scores for each map entity, and then rank map entities by a ranking model. A simple example of a ranking model can be the summation of probability of associated tickets normalized by trip count.
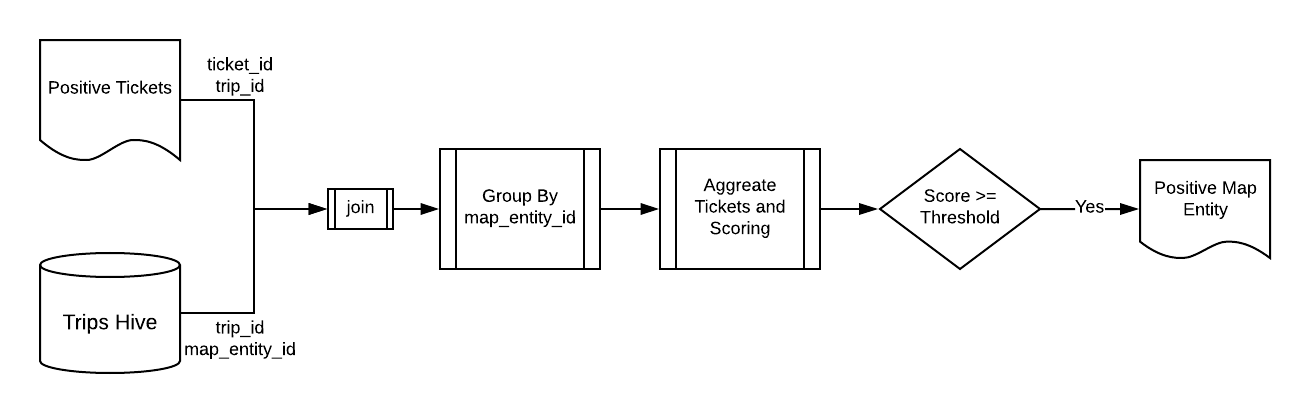
Instead of manually triggering the Spark pipeline, we schedule it to run weekly using Uber’s workflow management system, and the service for editing the map data type automatically consumes the result of the pipeline and generates tasks for manual editing.
Future work
There are two directions of the future of the project, vertical scaling and horizontal scaling. For vertical scaling, we will explore advanced models to improve the precision and recall of the model. For horizontal scaling, we will expand to more languages and map data types.
- We will explore the use of character-level (CharCNN) rather than word-level embeddings. Character-level embeddings are more resilient to typos (which happen a lot when riders submit tickets over the phone) compared to word-level embeddings because Word2Vec treats each misspelling of a word as a new word.
- Generalizing this work beyond English language tickets will help Uber scale its customer support in more regions. Word and character embeddings are language-agnostic and limited only by the amount of training data available, so this approach should generalize well to Uber’s global dataset.
If you would like to improve the quality of maps and location data at Uber, consider applying for a role on the Maps team!
Subscribe to our newsletter to keep up with the latest innovations from Uber Engineering.

Chun-Chen Kuo
Chun-Chen Kuo has been a software engineer at Uber since early 2017, and was an intern in the summer of 2016. His engineering and research interests center around machine learning.

Livia Yanez
Livia Yanez has been a data scientist at Uber since early 2017. She is passionate about applying machine learning to a wide variety of problem spaces, and to use a data-driven approach to identify how we can improve maps at Uber.

Jeffrey Yun
Jeffrey Yun was a software engineering intern on the Maps team in the summer of 2018. He is currently pursuing his B.S. in Computer Science and Mathematics at UCLA. His engineering interests center around algorithm design, artificial intelligence, and machine learning.
Posted by Chun-Chen Kuo, Livia Yanez, Jeffrey Yun
Related articles




Most popular

Stopping Uber Fraudsters Through Risk Challenges

Scaling AI/ML Infrastructure at Uber

Information for driving during the week of Super Bowl LVIII

Uber Reveals 2023 “Airport of the Year” Award Winners
Products
Company
