Michelangelo PyML: Introducing Uber’s Platform for Rapid Python ML Model Development
October 23, 2018 / Global
As a company heavily invested in AI, Uber aims to leverage machine learning (ML) in product development and the day-to-day management of our business. In pursuit of this goal, our data scientists spend considerable amounts of time prototyping and validating powerful new types of ML models to solve Uber’s most challenging problems (e.g., NLP based smart reply systems, ticket assistance systems, fraud detection, and financial and marketplace forecasting). Once a model type is empirically validated to be best for the task, engineers work closely with data science teams to productionize and make it available for low latency serving at Uber-scale. This cycle of prototyping, validating, and productionizing is central to ML innovation at Uber, and the less friction at each stage of this process, the faster Uber can innovate.
We looked closely at this innovation cycle and made the following observations:
- Unsurprisingly, data scientists overwhelmingly prefer to work in Python, partly due to the rich ecosystem of scientific libraries available and partly because almost all important deep learning and ML research today is published in Python.
- Because big data tools like Hive and Apache Spark can take days to set up and hours to execute, most data scientists prefer to gather data upfront and iterate on their prototypes locally, using tools like pandas, scikit-learn, PyTorch, and TensorFlow.
- Empirically validating a model often requires an online experiment and a large-scale offline validation. The first step requires serving the model online and the second step requires porting the model to a format that can be leveraged by offline data processors (at Uber we typically use native Apache Spark or PySpark). Both steps involve non-trivial amounts of work, and it can be challenging to ensure that both the online and offline versions of the model are equivalent.
To fulfill these needs, we developed Michelangelo PyML, a platform that enables rapid Python ML model development. As the first step, we built an integration with Michelangelo, Uber’s existing ML platform, that makes serving arbitrary Python-based models at scale for online or offline use cases as easy as requesting a ride.
These models can contain arbitrary user code, and can depend on any Python packages as well as native Linux libraries. In the following sections, we’ll show you in detail how we built this platform and how it allows data scientists to run an identical copy of a model locally, in real-time production experiments as well as in large-scale parallelized offline prediction jobs. All of this functionality is accessible via a simple Python SDK and can be leveraged directly from within a data scientist’s favorite development environment (such as Jupyter notebooks) without having to switch between separate applications. Our solution leverages several open source components and should be transferable to other ML platforms and model serving systems.
PyML’s place in Michelangelo
In September, 2017, we introduced Michelangelo, Uber’s Machine Learning Platform. Michelangelo enables Uber’s product teams to seamlessly build, deploy, and operate machine learning solutions at Uber’s scale, and currently powers roughly 1 million predictions per second.
Michelangelo was built with performance and scale in mind; supported model types (such as XGBoost, GLM, and various regressions) can be trained via Apache Spark on extremely large data sets that are available in Uber’s HDFS data lake. Those trained models get materialized as Apache Spark pipelines and can be used both for large-scale offline predictions as well as high-QPS online prediction requests. Please read our original article on Michelangelo for more details about its architecture.
However, Michelangelo’s focus on performance and scale came at the cost of flexibility:
- Users can train only models whose algorithms are natively supported by Michelangelo. If users need to train unsupported algorithms, they have to extend the platform’s training, deployment, and serving components.
- Feature transformations are limited to the vocabulary and expressiveness of Michelangelo’s DSL. If users need different transformations, they have to preprocess the data in Hive or extend Michelangelo’s DSL, which is a fairly invasive operation.
- To enable highly efficient model serving, Michelangelo models as well as the models’ library dependencies are loaded into and served from memory. As a result, Michelangelo’s training and serving systems depend on all dependencies of all supported model types, increasing the overall complexity of the dependency graph with every additional model type that is added.
This explicitly chosen trade-off to favor performance and scalability over flexibility made it hard for our data science teams to rapidly iterate and experiment with new ML models. PyML was built as a natural extension of Michelangelo to close the flexibility gap and make the platform a one-stop-shop for both highly efficient, high-QPS models as well as maximally customizable and experimental models. Once models are fully validated with PyML and need to be used in high-scale online environments, the user can replicate them in Michelangelo to fully take advantage of the platform’s resource efficiency (i.e., very low serving latency, compute/memory-efficient execution), depicted in Figure 1, below:

Using PyML
The following shows how a data scientist would use PyML in a Jupyter Notebook to deploy a logistic regression model trained on a publicly available dataset from the University of Wisconsin [1]. The features consist of various cell nuclei measurements from microscope images of breast cancer tumors while the labels are expert medical diagnoses.
Train a model
Training a model is independent of PyML, but shown here for completeness: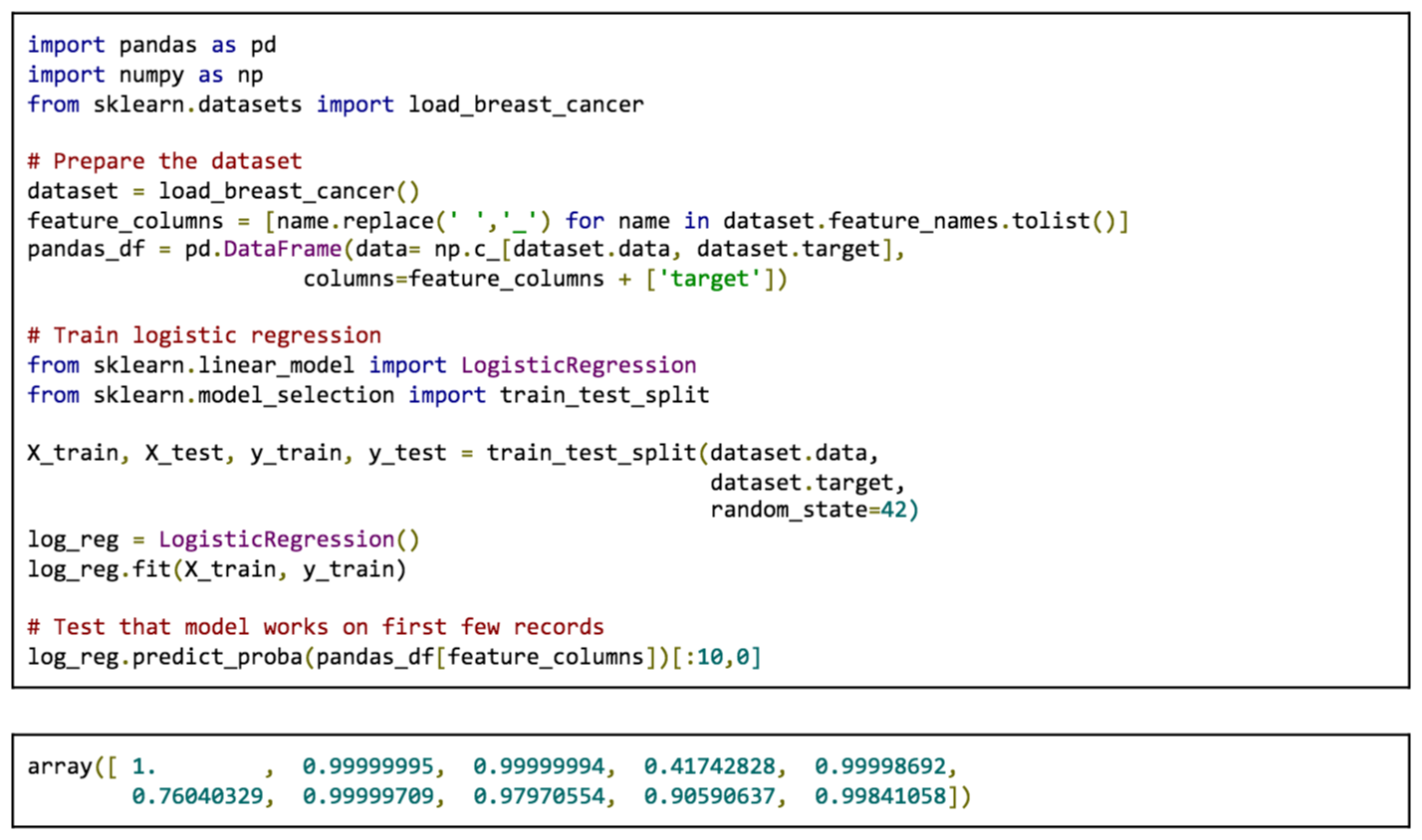
Prepare PyML model container
Trained models used with the PyML platform have to adhere to the PyML model contract. This contract is based on a very simple convention: The user dedicates a filesystem “home” folder to the PyML model where they save all of the model artifacts (like model weights). Besides the artifacts, the platform also expects to find the following user-provided files in that home folder, which is typically backed by git:

Let’s create our prediction model’s home folder and save the model artifacts:

Now that we have saved the model artifacts, we can implement the prediction contract and tell PyML about the package dependencies.
Let’s provide model.py and implement PyML’s prediction contract, DataFrameModel:

Let’s specify the Python packages model.py depends on:
Now, let’s instantiate a PyML model from the home folder and validate that it works:

Finally, let’s package the model up and create a Docker image behind the scenes (more details on this later):
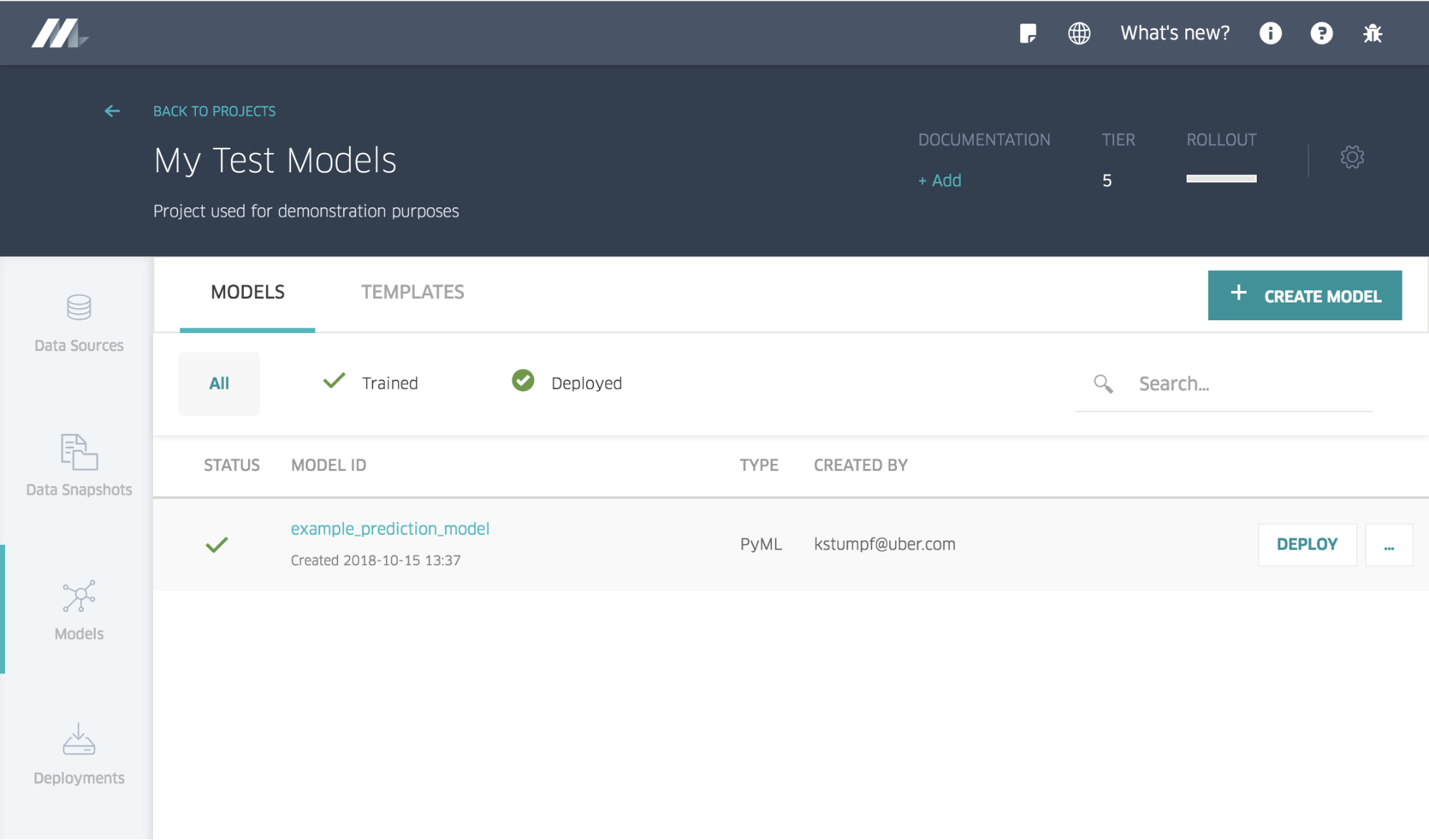
The packaged model is now versioned and managed in Michelangelo, ready for online deployment and offline predictions. Further, other users can now download the model and easily continue iterating on them. Finally, the model is now also available in Michelangelo’s UI, below, allowing the users to easily browse all of their managed PyML models, click-to-deploy, configure its access control list, and more:
Deploy the model to a production endpoint and make predictions
Deploy the model in just one line of code:![]()
After a few seconds, the model will be available on production hosts, automatically monitored by Michelangelo’s serving infrastructure and ready to serve traffic:
Run large-scale offline predictions
Before a user can generate offline predictions, the scoring dataset must be in Hive. Let’s instruct PyML how to find the dataset and where the prediction results should be written to:
Depending on the size of the user’s dataset, the results will be available in the destination table after a few minutes, hours, or days. Note that we were able to run offline batch predictions against the identical model which we deployed to our online serving system just seconds before—not a single line of code needed to be changed!
PyML Architecture
The architecture of PyML, depicted in Figure 3, below, provides just enough structure for scientists to be able to deploy their models quickly and reliably across environments without restricting the types of data they can use or the kinds of models they can deploy. Achieving this balance required us to think carefully about abstractions for representing data, models, and execution environments.
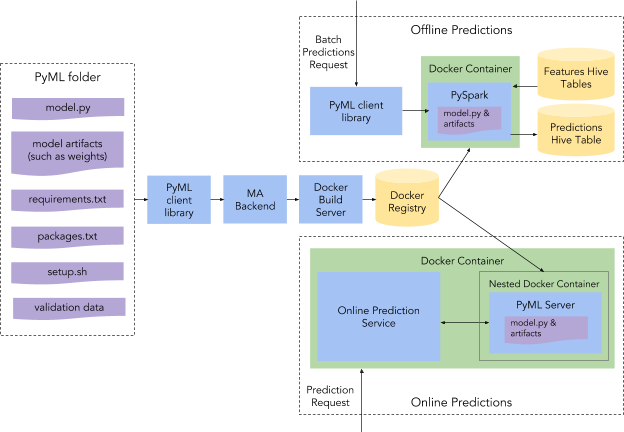
Data model
PyML offers users two data types out of the box: DataFrames, which store tabular structured data, and Tensors, which store named multidimensional arrays. While the list of PyML data types is extensible, our experience is that most models cleave into two camps: those that operate on DataFrames, such as scikit-learn models, and those that operate on bags of named Tensors, such as TensorFlow and PyTorch models.
Other model deployment frameworks offer less structured and un-opinionated data models, such as JSON in, JSON out. Still other, more restrictive approaches to deployment may even require users to specify detailed schema definitions upfront. PyML takes the middle road, and as we will discuss, there are numerous productivity and efficiency benefits to providing some structure in the data model without being overly prescriptive.
Model definition
As showcased above, users create a single entry point for their model, model.py, containing a class that inherits from DataFrameModel or TensorModel abstract classes, respectively. In both cases, users only need to implement two methods: a constructor to load their model parameters and a predict() method that accepts and returns either DataFrames or Tensors. The model interfaces abstract away where and how the model will be deployed so that the user can focus on what they understand best: the data going in and out of the model.
Python environments and setup
PyML models can load any data files and import any Python packages found in the model folder. Any other PIP, conda, or debian packages can be listed in requirements.txt and packages.txt, respectively. Custom setup commands, such as downloading large files needed by the model or building software packages, can be provided in setup.sh.
Validation data
An important part of defining the model is to supply example data that will be stored with the model. This validation data serves multiple purposes: it provides a sanity check that the model behaves the same across different environments and serves as an implicit schema definition for the model.
In practice, it is much easier for users to supply example data than it is for them to write a schema definition, especially when models have large numbers of variables. This is one way in which PyML preserves the flexibility and productivity of Python while providing the accountability and consistency needed for production model deployment.
Execution environments
PyML ensures that the user’s model produces the same output for the same input across multiple environments: the user’s local machine, an Apache Spark cluster, and a production server environment. It achieves this by automating the creation of a custom Docker image for the model, in the process using the provided validation data to verify the correctness of the model at image build time.
The PyML Docker image contains the entire model home folder and has all of the user-provided debian and conda dependencies installed. It further contains PyML’s entry points and system dependencies that are required for serving (e.g., PySpark and gRPC). Once the model image builds successfully and passes validation, the same image can be used both for offline and online prediction.
Offline predictions
Some models are designed to be deployed as daily or hourly batch jobs, while other models are deployed as online services. In either case, it’s generally useful to be able to evaluate models on vast amounts of data prior to deployment.
Developing a custom PySpark job for each model is tedious and can introduce skew between offline and online model implementations, especially when a model has lots of Python or system dependencies. PyML not only saves users time by completely automating this process, it also prevents subtle differences from creeping up between offline and online versions of models.
To generate offline predictions for DataFrame models, PyML users simply provide a SQL query with column names and types matching the inputs expected by their model, and the name of a destination Hive table in which to store output predictions. Behind the scenes, PyML starts a containerized PySpark job using the same image and Python environment as for serving the model online, ensuring that there are no differences between the offline and online predictions.
Online predictions
Existing serving infrastructure
Historically, users could deploy only models that were produced via Michelangelo’s Apache Spark training pipelines. A deployment request notifies an appropriate cluster of Docker containers, which host Michelangelo’s online prediction service, to download the model from the blob store and load it into memory. When a model is loaded and validated, it is ready to accept prediction requests via the online prediction service’s Thrift/RPC interface, as depicted in Figure 4, below:
For PyML models, we wanted to leverage as much of Michelangelo’s existing deployment, online serving, and monitoring infrastructure as possible. This required us to come up with a way for the Java-based online prediction service to communicate with a Python-based model without significant latency overhead.
PyML serving extension
The solution we came up with allows us to co-host PyML models as nested Docker containers inside of the Docker container that hosts the online prediction service, depicted in Figure 5 below:
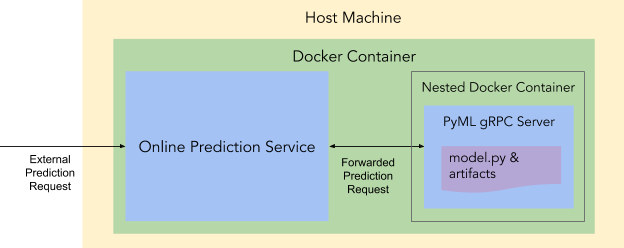
Besides the user-provided model dependencies and artifacts, PyML Docker images also contain a light-weight RPC server to allow the online prediction service to route prediction requests to the PyML model. Upon receiving a deployment request, the online prediction service launches the PyML model-specific Docker image as a nested Docker container via Mesos’ API. When the container is launched, it starts the PyML RPC server and begins listening for prediction requests on a Unix domain socket from the online prediction service.
By adding support for Docker-based models in addition to Apache Spark-based in-memory models, we were able to reuse Michelangelo’s battle-tested deployment and serving infrastructure.
Moving forward
PyML is popular among our data scientists who want to back-test and productionize deep learning models. Examples of use cases for PyML include driver promotion models, automated document processing tools that leverage computer vision models, and various NLP applications. In the future, we will continue to invest heavily in the PyML platform to further speed up the Python machine learning iteration cycle. On the immediate horizon is an expansion of PyML’s capabilities for greater reproducibility and a tight integration with Uber’s Experimentation Platform and Michelangelo’s feature store.
Reproducibility
As part of the PyML model production deployment process, we version and manage the model artifacts. However, PyML currently does not version the artifacts and pipelines that lead to the model artifacts in the first place. This includes the data that was used to train the model, the applied transformations, and, of course, the training script.
In the future, we will give our users the option to version a PyML model’s training code as well as its source data together with the model artifacts, allowing users at the company to reproduce a PyML model from scratch.
Integration with Uber’s Experimentation Platform
At any given moment, Uber is running over 1,000 experiments via our experimentation platform. With PyML, data scientists are now empowered to rapidly iterate and deploy their models. To further tighten the feedback loop, we are planning to tightly integrate with our XP. This will allow our users to deploy PyML models straight into automatically created experiments.
Integration with Michelangelo’s feature store
Getting the right data to the right location in the right amount of time is still the hardest problem in machine learning. As previously described, Michelangelo’s feature store helps solve that problem by enabling data scientists to efficiently kickstart new ML projects or improve existing ones with data from a highly curated set of tens of thousands of features.
So far, our users have only been able to take advantage of those features if they train their models via Michelangelo’s training pipeline. With PyML, the value of the feature store will be unlocked for all users: data scientists using PyML will be able to speed up their model development by tapping into features that are successfully used by teams across the company. This will allow them to focus on the most important task: training and evaluating new models without having to worry about data pipelines and getting the right data to their models at prediction time.
If you are interested in working with PyML, Michelangelo, and the full Uber machine learning stack, check out these career opportunities!
Citations
[1] Wolberg, Street and Mangasarian (1995). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Subscribe to our newsletter to keep up with the latest innovations from Uber Engineering.
Kevin Stumpf is a tech lead manager and Stepan Bedratiuk is a senior software engineer on Uber’s Machine Learning Platform Team. Olcay Cirit is a senior software engineer at Uber AI Labs. We thank Logan Jeya, Joseph Wang, Jake Larkin and Jeremy Hermann who helped make this project possible. We also greatly appreciate Stephanie Blotner, Molly Vorwerck, and Wayne Cunningham’s help in reviewing this post.

Stepan Bedratiuk
Stepan Bedratiuk is a senior software engineer on Uber's Machine Learning Platform team.

Olcay Cirit
Olcay Cirit is a Staff Research Scientist at Uber AI focused on ML systems and large-scale deep learning problems. Prior to Uber AI, he worked on ad targeting at Google.
Posted by Kevin Stumpf, Stepan Bedratiuk, Olcay Cirit
Related articles





Most popular

A beginner’s guide to Uber vouchers for transit agency riders

Uber Earner x Miami HEAT Ticket Sweepstakes OFFICIAL RULES

Case study: Tri-Rail’s role in paving the way for effortless commuting

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
