How to Get a Better GAN (Almost) for Free: Introducing the Metropolis-Hastings GAN
November 29, 2018 / Global
Generative Adversarial Networks (GANs) have achieved impressive feats in realistic image generation and image repair. Art produced by a GAN has even been sold at auction for over $400,000!
At Uber, GANs have myriad potential applications, including strengthening our machine learning (ML) models against adversarial attacks, learning simulators for traffic, ride requests, or demand patterns over time, and generating personalized order suggestions for Uber Eats.
GANs consist of two models trained as adversaries: the generator learns the distribution of real data and the discriminator learns to distinguish generated (in other words, “fake”) samples from real data. Most of the research on GANs focuses on improving them by altering their structure or training, for instance, through using larger networks or different loss functions.
In our paper, to be presented at the Bayesian Deep Learning workshop at NeurIPS 2018 next week, we offer an alternative idea: leveraging the discriminator to pick better samples from the generator after training is done. Our work provides a complementary sampling method to very similar recent work by researchers at Google and U.C. Berkeley on Discriminator Rejection Sampling (DRS).
The main idea of our method and of Discriminator Rejection Sampling is to use information from the trained discriminator in order to choose samples from the generator that are closer to samples from the real data distribution. Usually, the discriminator is thrown out after training because the training process should encode all required knowledge from the discriminator into the generator. However, generators are often imperfect, while discriminators hold useful information, so it’s worth exploring how we can sample more effectively to improve already trained GANs. We sample from this distribution using the Metropolis-Hastings algorithm and dub the resulting model the Metropolis-Hastings GAN (MH-GAN).
Resampled GANs
GAN training is often thought of as a game between two adversaries, where the generator tries to maximize the probability of the discriminator making a mistake while the discriminator optimizes its ability to separate generated and real samples. Figure 1, below, shows this process, where the generator moves towards the minimum of the value function (orange) while the discriminator moves towards the maximum (purple). After training, samples from the generator may be easily drawn by feeding the generator different noise vectors. If training produces a perfect generator, the resulting probability density function of the generator pG should be the same as the density of the real data. Unfortunately, many currently employed GANs do not converge to the true data distribution, and so taking samples directly from these imperfect generators will produce examples that don’t look like the original training data.
The imperfection of![]() leads us to consider a different distribution: the density implied by the discriminator with respect to the generator. We call this distribution
leads us to consider a different distribution: the density implied by the discriminator with respect to the generator. We call this distribution![]() , and it is often closer to the real data distribution than
, and it is often closer to the real data distribution than![]() . This is because training a discriminator is an easier task than training the generator, so the discriminator likely has information that can help correct the generator. If we have a perfect discriminator D for an imperfect generator G, making
. This is because training a discriminator is an easier task than training the generator, so the discriminator likely has information that can help correct the generator. If we have a perfect discriminator D for an imperfect generator G, making ![]() our data generating density function instead of
our data generating density function instead of![]() is equivalent to having a new generator
is equivalent to having a new generator ![]() that perfectly models the real data, as in Figure 1, below:
that perfectly models the real data, as in Figure 1, below:
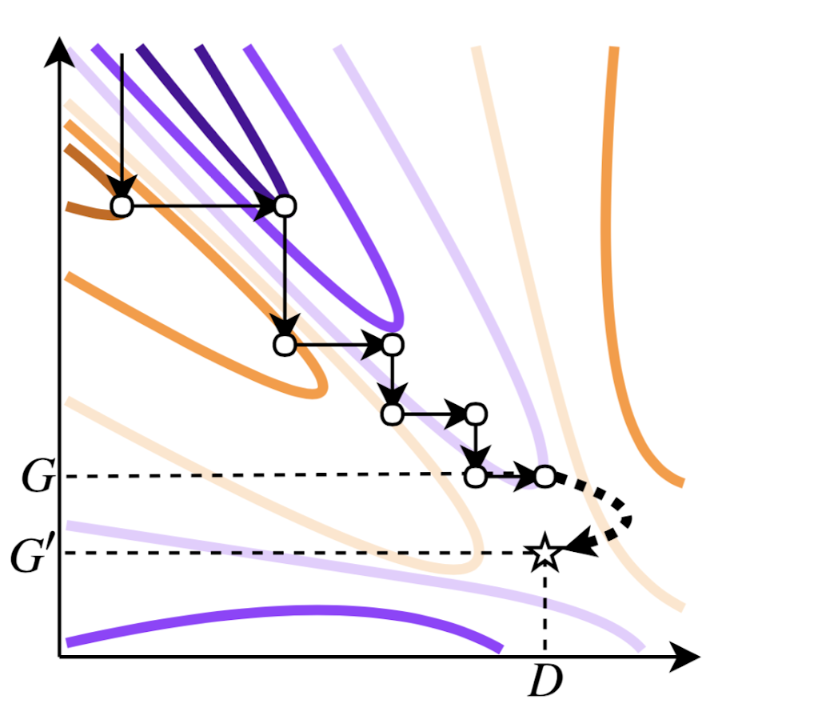
Even though the pD distribution may better match the data, drawing samples from it is not as straightforward as sampling from the generator. Luckily, we can draw samples from this distribution using sampling methods, two of which are rejection sampling and Markov Chain Monte Carlo (MCMC). Either can be used used as a post-processing step to improve the generator output; the aforementioned Discriminator Rejection Sampling method uses rejection sampling, while our MH-GAN uses the Metropolis-Hastings MCMC approach.
Rejection sampling
Rejection sampling wraps a proposal distribution with an accept or reject step, warping the proposal distribution into a new distribution that’s colored by the accept probability changing over the input space. Each sample drawn from the proposal is independently accepted with probability equal to the ratio of the sample distribution divided by the proposal distribution times a constant multiplier. In the scenario of sampling from the ![]() defined by a GAN, this ratio is
defined by a GAN, this ratio is ![]() , where the M multiplier is the upper bound for the ratio
, where the M multiplier is the upper bound for the ratio ![]() over all possible samples. M presents a challenge for two reasons: first, we cannot know the true value of M, so it must be estimated empirically as in DRS, and if our estimate is off we will not be sampling from the correct distribution. Second, even given a good estimate of M we may find that it is very large, which effectively means that rejection sampling suffers from a large number of sample rejections before first accept because of the high-dimensionality of the sampling space. To get around the sample waste problem, DRS has an additional ? heuristic to shift the discriminator scores, making the model sample from a distribution different from the real data even when D is perfect.
over all possible samples. M presents a challenge for two reasons: first, we cannot know the true value of M, so it must be estimated empirically as in DRS, and if our estimate is off we will not be sampling from the correct distribution. Second, even given a good estimate of M we may find that it is very large, which effectively means that rejection sampling suffers from a large number of sample rejections before first accept because of the high-dimensionality of the sampling space. To get around the sample waste problem, DRS has an additional ? heuristic to shift the discriminator scores, making the model sample from a distribution different from the real data even when D is perfect.
A better approach: Metropolis-Hastings
We use Metropolis-Hastings (MH) instead, which is part of the family of MCMC methods. This family of methods was invented precisely as a replacement for rejection sampling in higher dimensions and works by sampling from a possibly complicated probability distribution by taking multiple samples from a proposal distribution. MH involves taking K samples from the proposed distribution (i.e., the generator) and choosing one sample from the K by sequentially deciding whether to accept the current sample or keep the previously chosen sample based on an acceptance rule, as in Figure 2, below:
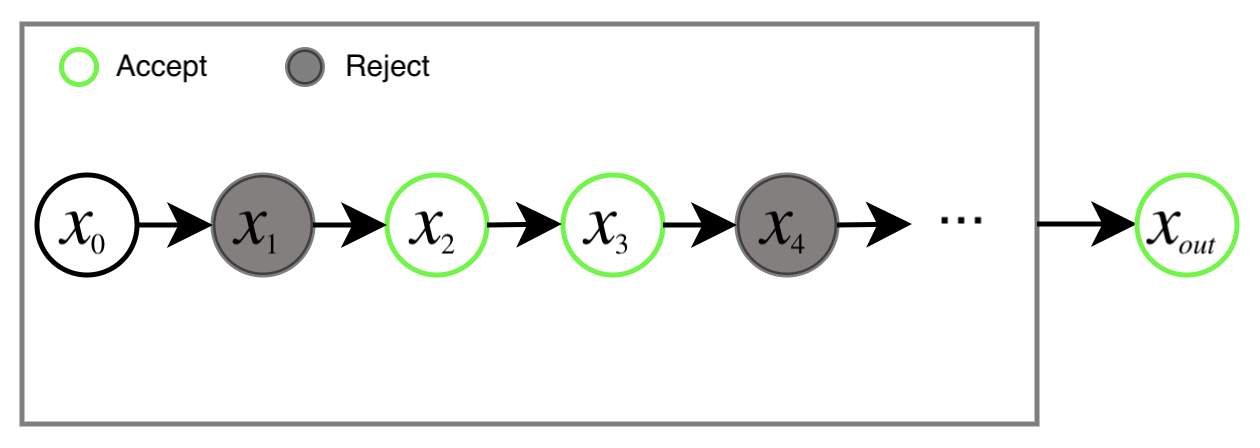 | 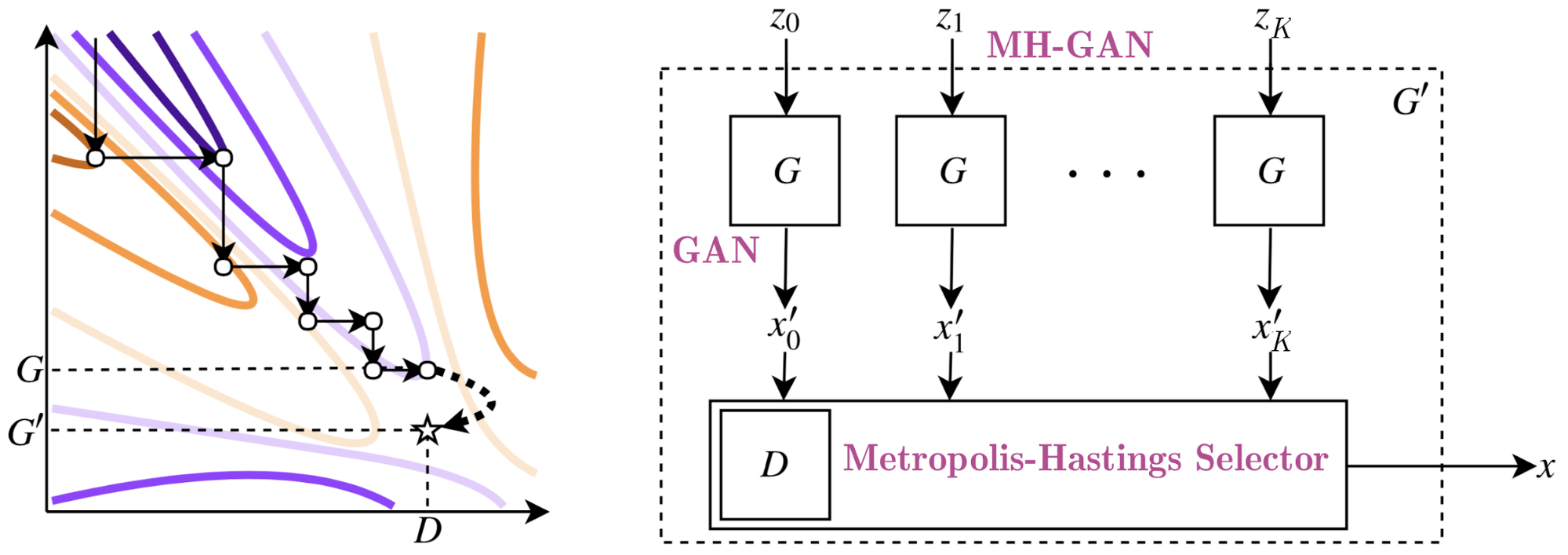 |
| Figure 2: MH takes K samples in a chain and accepts or rejects each one based on an acceptance rule. The output of this chain is the last accepted sample. For MH-GAN, the K samples are generated from G, and the outputs of independent chains are samples from MH-GAN’s generator G’. |
The key feature of MH-GAN is that the acceptance probability can be computed just with the ratio of probability densities![]() which is readily available from the output of the GAN’s discriminator! Starting with
which is readily available from the output of the GAN’s discriminator! Starting with![]() as the current sample, a new sample
as the current sample, a new sample![]() is accepted over the current sample
is accepted over the current sample ![]() with probability ?:
with probability ?:

where D is the discriminator score ![]() .
.
K is a hyperparameter and can be chosen based on speed/fidelity trade-offs. It can be shown that for a perfect discriminator and as K→∞, this recovers the real data distribution.
Details of MH-GAN
We want to highlight three important details about MH-GAN:
- Independent samples: Noise samples are drawn independently K times and run through the generator to generate the chain to which the MH selector is applied. Independent chains are used to obtain multiple samples from MH-GAN’s generator G’.
- Initialization: It’s common for MH to suffer from long burn-in periods, where a large number of samples must be rejected before one is accepted due to a bad starting point. To avoid this, we are particular about how we initialize the chain of samples. We can take advantage of the examples of real data at our disposal and initialize each chain with a randomly chosen sample of real data. If no sample further down the chain is accepted, we can still make sure no sample from the real data is ever output by restarting the sampling from a generated sample. Note that we do not need an actual sample for initialization, just its discriminator score.
- Calibration: Realistically, we cannot achieve a perfect D, but we may relax that assumption due to our calibration step. Additionally, the assumption of a perfect discriminator is not as strong as it may seem. Because the discriminator just evaluates samples from the generator and the initial real sample, it only needs to be accurate for samples coming from the generator and the real data distribution. It’s not strictly necessary for the values of D to be accurate as the decision boundary is correct in normal GAN training, but MH requires that the values be well-calibrated in terms of probability density ratios in order to get the correct acceptance ratio. To do the calibration, we use a held out set (10 percent of training data) with isotonic regression to adjust the discriminator score D.
1-D and 2-D Gaussian results
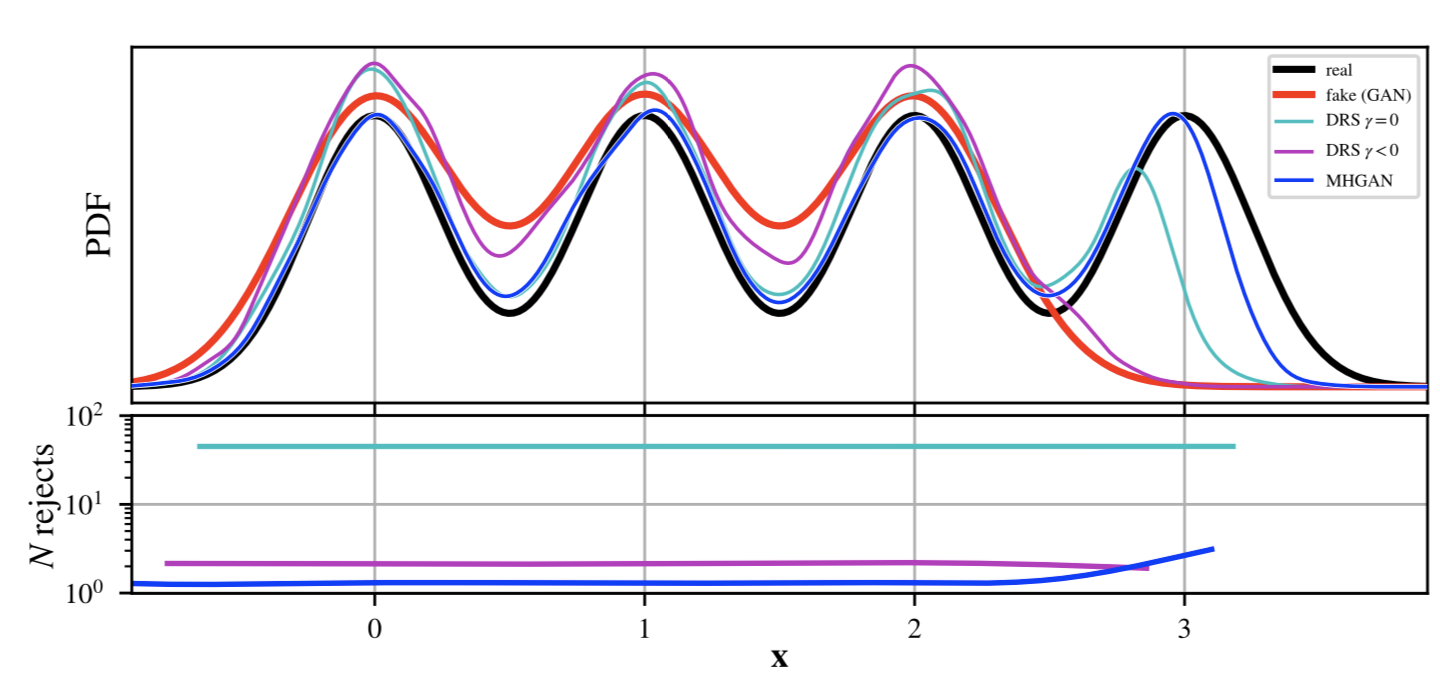
We compare MH-GAN and DRS with a toy example where the real data is a univariate mixture of four Gaussians, and the density of the generator![]() shows the common GAN pathology of missing one of the modes (Figure 3, below). Whereas DRS without ? shift and MH-GAN are able to recover the missing mode, DRS with ? shift (the default setting used in that paper) cannot. However, DRS without ? shift increases the number of samples needed before a single accept by an order of magnitude.
shows the common GAN pathology of missing one of the modes (Figure 3, below). Whereas DRS without ? shift and MH-GAN are able to recover the missing mode, DRS with ? shift (the default setting used in that paper) cannot. However, DRS without ? shift increases the number of samples needed before a single accept by an order of magnitude.
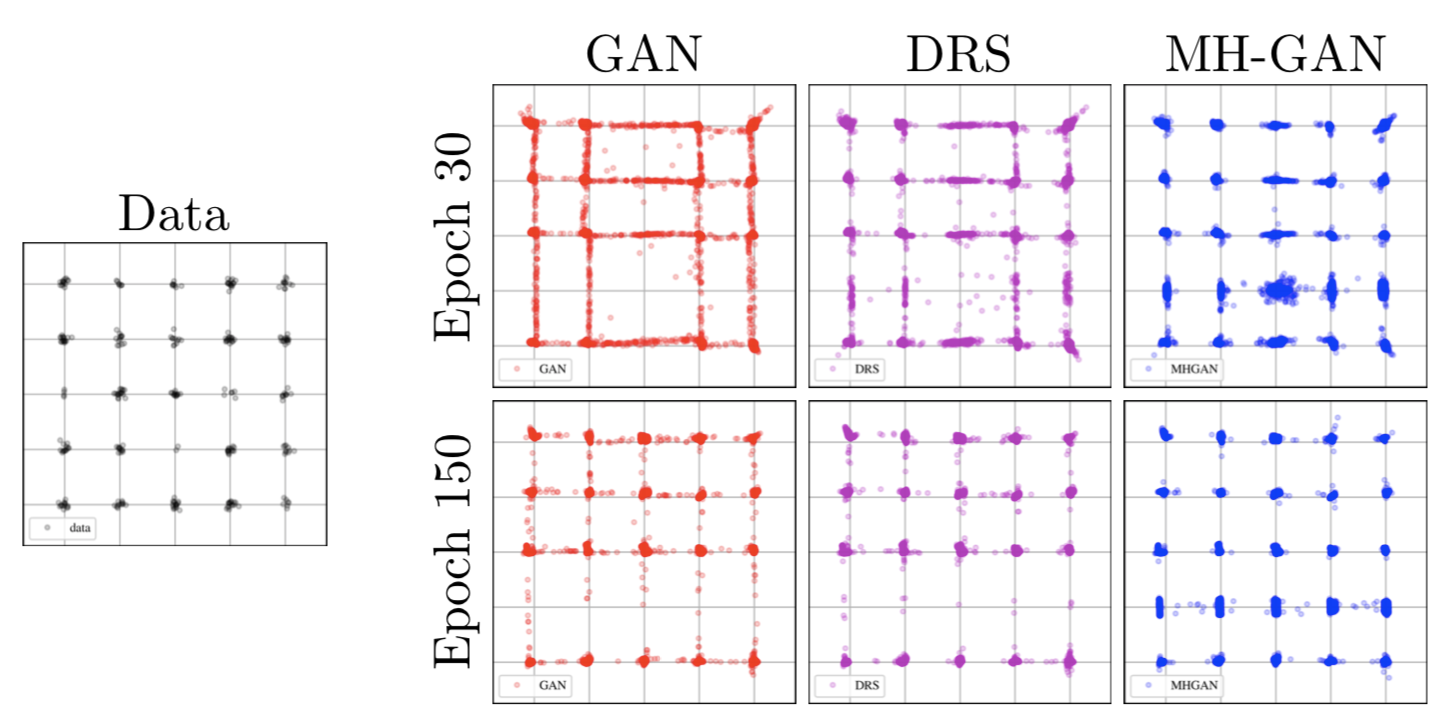
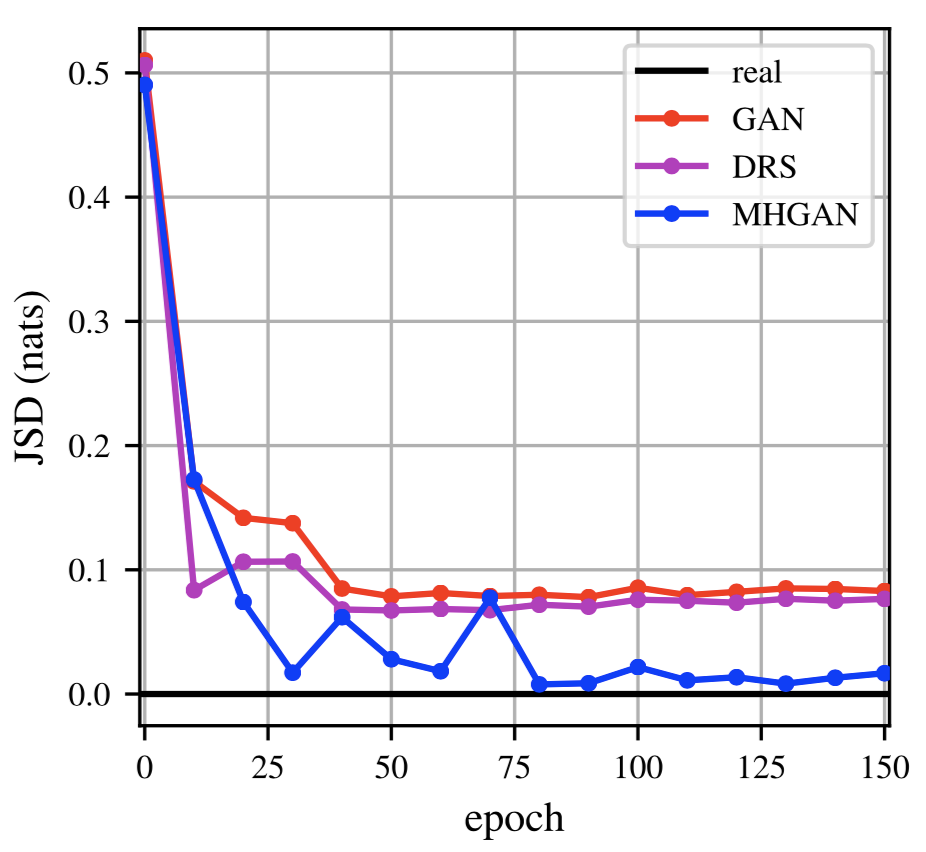
A 5×5 grid of 2D Gaussian distributions is a popular toy example in the existing literature. In Figure 4, below, we compare samples from the real data to samples from a base GAN, DRS, and MH-GAN at different stages of training; all methods use a neural network with four fully connected layers with Rectified Linear Units (ReLU) activations, a hidden layer size of 100, and noise vector of size 2. It’s visually clear that DRS is an improvement on the base GAN, but it is much closer to the base GAN than to the real data. MH-GAN finds all 25 modes and is more visually similar to the real samples. Quantitatively, we also show that MH-GAN has lower Jensen-Shannon divergence than both base GAN and DRS.
CIFAR-10 and CelebA results
To test on real data, we used CIFAR-10 and CelebA with DCGAN and WGAN with gradient penalty. The table in Figure 5, below, shows the Inception scores of the calibrated MH-GAN.
Inception scores ignore the real data completely and are calculated by passing generated images through a pre-trained (on the ImageNet dataset) Inception classifier; it measures both the confidence of the network that the input belongs to a specific class and the diversity of classes predicted. The Inception score is a flawed metric, but its wide use makes it helpful for comparison with other work.
Calibrated MH-GAN generally does better than the others, but this is not consistent for all epochs. One possible explanation is that for some epochs, the discriminator score is very different than the ideal discriminator score, making the acceptance probability less accurate.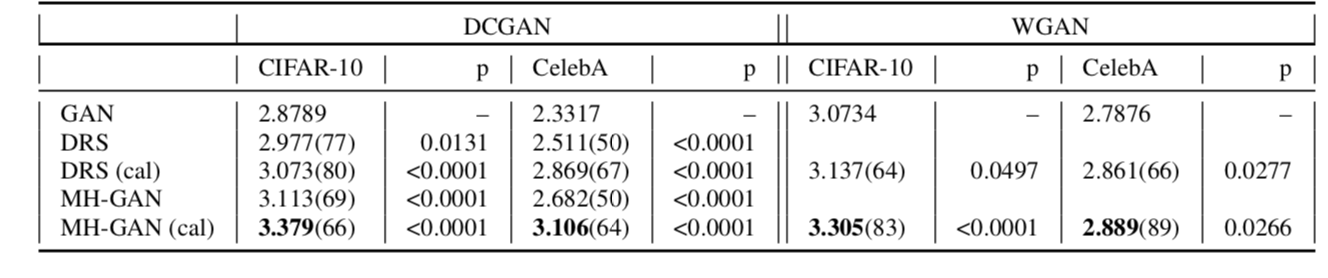
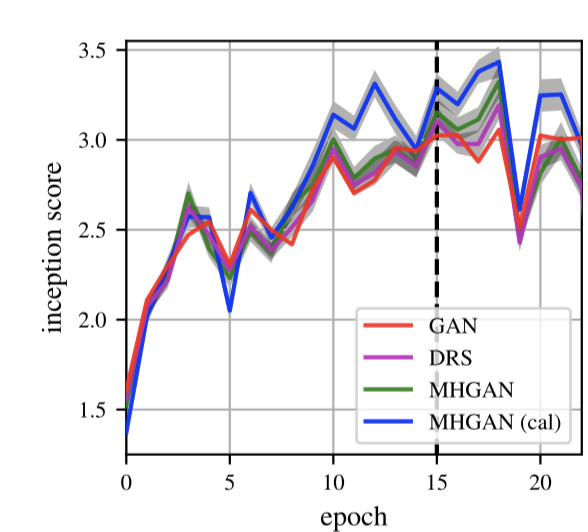
Figure 5: Inception score results for CIFAR-10 and CelebA comparing a base GAN, DRS, and MH-GAN with and without calibration (higher is better). The table results are taken at epoch 60.
Future work
Metropolis-Hastings General Adversarial Networks (MH-GANs) are a simple way to improve the generator of GANs by using the Metropolis-Hastings algorithm as a post-processing step to normal GAN training. Results on toy and real datasets show that our MH-GAN gives superior results to base GANs and the recent Discriminator Rejection Sampling method. Our work is a proof of concept on smaller datasets and networks, so obvious next steps would be to apply MH-GAN to the larger datasets and networks used for state of the art results. Scaling our approach to larger datasets and GANs should be straightforward— it requires only discriminator scores and samples from G!
In addition, the idea of using MCMC algorithms to improve GANs can be extended beyond MH to more efficient algorithms like Hamiltonian Monte Carlo. For more details and plots, be sure to read our paper, and to reproduce or extend the work, check out our open source PyTorch implementation.
If this sort of research excites you, apply for a role with Uber AI Labs.

R. Turner
Ryan Turner was a former Senior Research Scientist at Uber.

Jane Hung
Jane Hung is a Research Engineer at Uber AI where she works with product teams to develop new and better products by applying machine learning recommendation models. She has worked with teams like Airports, Driver Forecasting, and Driver Engagements.

Yunus Saatci
Yunus Saatci is a senior research scientist with Uber AI Labs.

Jason Yosinski
Jason Yosinski is a former founding member of Uber AI Labs and formerly lead the Deep Collective research group.
Posted by R. Turner, Jane Hung, Yunus Saatci, Jason Yosinski
Related articles





Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
