Introducing Makisu: Uber’s Fast, Reliable Docker Image Builder for Apache Mesos and Kubernetes
December 6, 2018 / Global
To ensure the stable, scalable growth of our diverse tech stack, we leverage a microservices-oriented architecture, letting engineers deploy thousands of services on a dynamic, high-velocity release cycle. These services enable new features to greatly improve the experiences of riders, drivers, and eaters on our platform.
Although this paradigm supported hypergrowth in both scale and application complexity, it resulted in serious growing pains given the size and scope of our business. For the ease of maintaining and upgrading microservices, we adopted Docker in 2015 to enforce resource constraints and encapsulate executable with its dependencies.
As part of the Docker migration, the core infrastructure team developed a pipeline that quickly and reliably generates Dockerfiles and builds application code into Docker images for Apache Mesos and Kubernetes-based container ecosystems. Giving back to the growing stack of microservice technologies, we open sourced its core component, Makisu, to enable other organizations to leverage the same benefits for their own architectures.
Docker migration at Uber
In early 2015, we were deploying 400 services to bare metal hosts across our infrastructure. These services shared dependencies and config files that were put directly on the hosts, and had few resource constraints. As the engineering organization grew, so too did the need for setting up proper dependency management and resource isolation. To address this, the core infrastructure team started migrating services to Docker containers. As part of this effort, we built an automated service to standardize and streamline our Docker image build process.
The new containerized runtime brought significant improvements in speed and reliability to our service lifecycle management operations. However, secrets (a term for security features such as passwords, keys, and certificates) used to access service dependencies were being built into images, leading to possible security concerns. In short, once a file is created or copied into a Docker image, it is persisted into a layer. While it is possible to mask files using special whiteout files so that secrets will not appear in the resulted image, Docker does not provide a mechanism to actually remove the files from intermediate layers.
The first solution we tried for mitigating this security risk was docker-squash, an open source tool that combines Docker layers by deleting files only used in intermediate build steps. Once part of our workflow, docker-squash removed secrets, but doubled image build time. Building Docker images is already a lengthy process, and the addition of docker-squash negated the benefits of increased developer velocity from having a microservice-based architecture.
Unsatisfied with our post-hoc squashing solution, we decided to fork Docker to add the support we needed: If we could mount volumes at build time that weren’t included in the resulting image, we could use this mount to access secrets while building and leave no trace of the secret in the final container image. The approach worked well; There was no additional latency and the necessary code changes were relatively minimal, leading to quick implementation. Both the infrastructure team and service owners were satisfied at the time, and enabled Docker migration to progress smoothly.
Building container images at scale
By 2017, this setup was no longer sufficient for our scale. As Uber grew, the size and scope of our infrastructure similarly burgeoned. Building upwards of 3,000 services each a few times per day resulted in a much more time-consuming image build process. Some of these builds took up to two hours and produced images whose sizes exceeded 10GB, consuming significant storage space and bandwidth, and hurting developer productivity.
At this point, we realized that we had to take a step back and rethink how we should be building container images at scale. In doing so, we arrived at three major requirements for our next-generation build solution: portable building, distributed cache support, and image size optimization.
Portable building
In 2017, the core infrastructure team began an effort to move Uber’s compute workload to a unified platform that would provide greater automaticity, additional scalability, and more elastic resource management. To accommodate this, the Dockerfile build process also needed to be able to run in a generic container in shared clusters.
Unfortunately, Docker’s build logic relies on a copy-on-write file system to determine the differences between layers at build time. This logic requires elevated privileges to mount and unmount directories inside build containers, a behavior that we wanted to prevent on our new platform to ensure optimal security. This meant that, for our needs, fully-portable building was not an option with Docker.
Distributed cache support
Layer caching allows users to create builds consisting of the same build steps as previous builds and reuse formerly generated layers, thereby reducing execution redundancy. Docker offers some distributed cache support for individual builds, but this support does not generally extend between branches or services. We relied primarily on Docker’s local layer cache, but the sheer volume of builds spread across even a small cluster of our machines forced us to perform cleanup frequently, and resulted in a low cache hit rate which largely contributed to the inflated build times.
In the past, there had been efforts at Uber to improve this hit rate by performing subsequent builds of the same service on the same machine. However, this method was insufficient as the builds consisted of a diverse set of services as opposed to just a few. This process also increased the complexity of build scheduling, a nontrivial feat given the thousands of services we leverage on a daily basis.
It became apparent to us that greater cache support was a necessity for our new solution. After conducting some research, we determined that implementing a distributed layer cache across services addresses both issues by improving builds across different services and machines without imposing any constraints on the location of the build.
Image size optimization
Smaller images save storage space and take less time to transfer, decompress, and start.
To optimize image size, we looked into using multi-stage builds in our solution. This is a common practice among Docker image build solutions: performing build steps in an intermediate image, then copying runtime files to a slimmer final image. Although this feature does require more complicated Dockerfiles, we found that it can drastically reduce final image sizes, thereby making it a requirement for building and deploying images at scale.
Another optimization tactic we explored for decreasing image size is to reasonably reduce the number of layers in an image. Fat images are sometimes the result of files being created and deleted or updated by intermediate layers. As mentioned earlier, even when a temporary file is removed in a later step, it remains in the creation layer, taking up precious space. Having fewer layers in an image decreases the chance of deleted or updated files remaining in previous layers, hence reducing the image size.
Introducing Makisu
To address the above considerations, we built our own image building tool, Makisu, a solution that allows for more flexible, faster container image building at scale. Specifically, Makisu:
- requires no elevated privileges, making the build process portable.
- uses a distributed layer cache to improve performance across a build cluster.
- provides flexible layer generation, preventing unnecessary files in images.
- is Docker-compatible, supporting multi-stage builds and common build commands.
Below, we go into greater detail about these features.
Building without elevated privileges
One of the reasons that a Docker image is lightweight when compared to other deployment units, such as virtual machines (VMs), is that its intermediate layers only consist of the file system differences before and after running the current build step. Docker computes differences between steps and generates layers using copy-on-write file system (CoW), which requires privileges.
To generate layers without elevated privileges, Makisu performs file system scans and keeps an in-memory representation of the file system. After running a build step, it scans the file system again, updates the in-memory view, and adds each changed file (i.e., an added, modified, or removed file) to a new layer.
Makisu also facilitates high compression speed, an important consideration for working at scale. Docker uses Go’s default gzip library to compress layers, which does not meet our performance requirements for large image layers with a lot of plain text files. Despite the time cost of scanning, Makisu is faster than Docker in a lot of scenarios, even without cache. The P90 build time decreased by almost 50 percent after we migrated the build process from Docker to Makisu.
Distributed cache
Makisu uses a key-value store to map lines of a given Dockerfile to the digests of the layers stored in a Docker registry. The key-value store can be backed by either Redis or a file system. Makisu also enforces a cache TTL, making sure cache entries do not become too stale.
The cache key is generated using the current build command and the keys of previous build commands within a stage. The cache value is the content hash of the generated layer, which is also used to identify the actual layer stored in the Docker registry.
During the initial build of a Dockerfile, layers are generated and asynchronously pushed to the Docker registry and the key-value store. Subsequent builds that share the same build steps can then fetch and unpack the cached layers, preventing redundant executions.
Flexible layer generation
To provide control over image layers that are generated during the build process, Makisu uses a new optional commit annotation, #!COMMIT, that specifies which lines in a Dockerfile can generate a new layer. This simple mechanism allows for reduced container image sizes (as some layers might delete or modify files added by previous layers) and solves the secret-inclusion problem without post-hoc layer squashing. Each of the committed layers is also uploaded to a distributed cache, meaning that it can be used by builds on other machines in the cluster.
Below, we share an example Dockerfile that leverages Makisu’s layer generation annotation:
FROM debian:8 AS build_phase
RUN apt-get install wget #!COMMIT
RUN apt-get install go1.10 #!COMMIT
COPY git-repo git-repo
RUN cd git-repo && make
FROM debian:8 AS run_phase
RUN apt-get install wget #!COMMIT
LABEL service-name=test
COPY –from=build_phase git-repo/binary /binary
ENTRYPOINT /binary
In this instance, the multi-stage build installs some build-time requirements (wget and go1.10), commits each in their own layer, and proceeds to build the service code. As soon as these committed layers are built, they are uploaded to the distributed cache and available to other builds, providing significant speedups due to redundancy in application dependencies.
In the second stage, the build once again installs wget, but this time Makisu reuses the layer committed during the build phase. Finally, the service binary is copied from the build stage and the final image is generated. This common paradigm results in a slim, final image that is cheaper to construct (due to the benefits of distributed caching) and takes up less space, depicted in Figure 1, below:
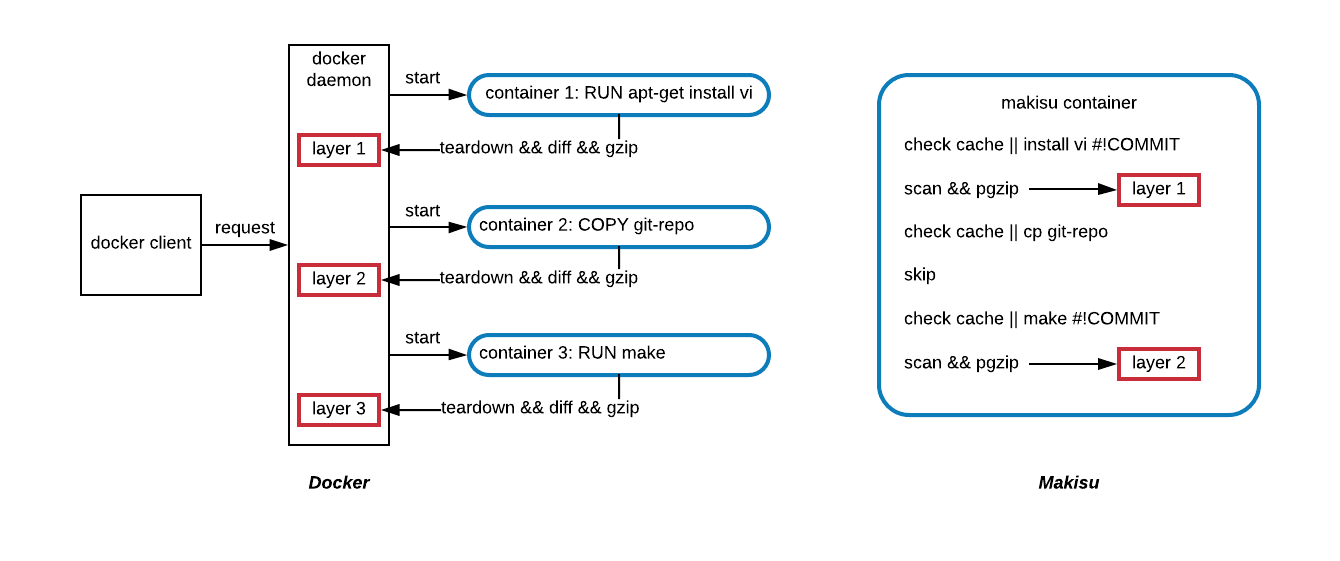
Docker compatibility
Given that a Docker image is just composed of a few plain tar files that are unpacked in sequential order and two configuration files, the images generated by Makisu are fully compatible with both the Docker daemon and registry.
Makisu also has full support for multi-stage builds. With smart uses of #!COMMIT, stages can be optimized so those that are unlikely to be reused can avoid layer generations, saving storage space.
Additionally, because the commit annotations are formatted as comments, Dockerfiles used by Makisu can be built by Docker without issue.
Using Makisu
To get started with Makisu, users can download the binary directly onto their laptops and build simple Dockerfiles without the RUN directive. Users can also download Makisu and run it inside a container locally for full Docker compatibility or implement it as part of a Kubernetes or Apache Mesos continuous integration (CI) workflow:
Others solutions in the open source community
There are various other open source projects that facilitate Docker image builds, including:
- Bazel was one of the first tools that could build Docker compatible images without using Docker or any other form of containerizer. It works very well with a subset of Docker build scenarios given a Bazel build file. We were inspired by its approach of building images, but we found that it does not support the RUN directive, which means users cannot install some dependencies (for example, apt-get install wget), making it hard to replace most Docker build workflows.
- Kaniko is an image build tool that provides robust compatibility with Docker and executes build commands in user space without the need for a Docker daemon. Kaniko offers smooth integration with Kubernetes and multiple registry implementations, making it a competent tool for Kubernetes users. However, Makisu provides a solution that better handles large images, especially those with node_modules, allows cache to expire, and offers more control over cache generation, three features critical for handling more complex workflows.
- BuildKit, a Dockerfile-agnostic builder toolkit, depends on runC and containerd, and supports parallel stage executions. BuildKit needs access to /proc to launch nested containers, which is not doable in our production environments.
The abundance and diversity of these solutions shows the need for alternative image builders in the Docker ecosystem.
Moving forward
Compared to our previous build process, Makisu reduced Docker image build time by up to 90 percent and on average 40 percent, saving precious developer time and CPU resources. These improvements depend on how a given Dockerfile is structured and how useful distributed cache is to its specific set-up. Makisu also produces images up to 50 percent smaller in size by getting rid of temporary and cache files, as well as build-time only dependencies, which saves space in our compute cluster and speeds up container deployments.
We are actively working on additional performance improvements and adding more features for better integration with container ecosystems. We also plan to add support for Open Container Initiative (OCI) image formats and integrate Makisu with existing CI/CD solutions.
We encourage you to try out Makisu for your container CI/CD workflow and provide us with your feedback! Please contact us via our Slack and GitHub channels.
If you’re interested in challenges with managing containers at scale, consider applying for a role on our team!
Subscribe to our newsletter to keep up with the latest innovations from Uber Engineering.

Evelyn Liu
Evelyn Liu is s software engineer on Uber's Compute Platform team.

Ed Oakes
Ed Oakes was a software engineer with Uber in summer 2018.

Yiran Wang
Yiran Wang is a senior software engineer on Uber's Compute Platform team.
Posted by Evelyn Liu, Ed Oakes, Caspar, Yiran Wang
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
