Under the Hood of Uber ATG’s Machine Learning Infrastructure and Versioning Control Platform for Self-Driving Vehicles
March 4, 2020 / Global
As Uber experienced exponential growth over the last few years, now supporting 14 million trips each day, our engineers proved they could build for scale. That value extends to other areas, including Uber ATG (Advanced Technologies Group) and its quest to develop self-driving vehicles.
A significant portion of this work involves creating machine learning (ML) models to handle tasks such as processing sensor input, identifying objects, and predicting where those objects might go. The many models needed to solve this problem, and the large team of engineers working on them, creates a management and versioning issue in itself.
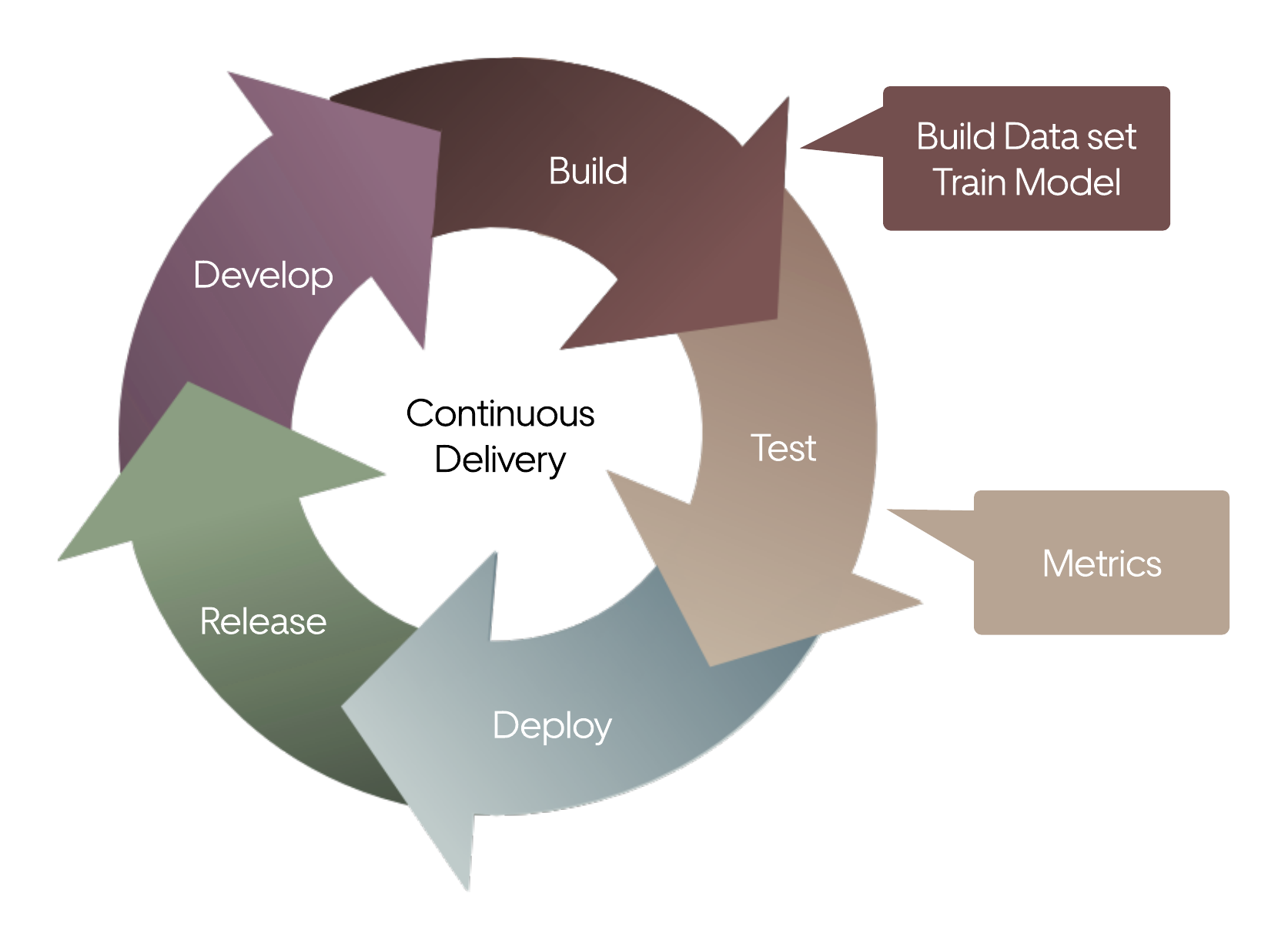
We initially address this problem by defining a five-step life cycle for the training and deployment of ML models in our self-driving vehicles. This life cycle begins with data ingestion and goes all the way to model serving, with steps along the way to ensure our models perform well. This process lets us effectively accelerate the iteration of our self-driving vehicle components, continually refining them to perform to the highest standards.
We can further benefit by automating this process to help manage the many models in development. Due to the deep dependencies and development complexity of ML models in the self-driving domain, we developed VerCD, a set of tools and microservices to support our ML workflow. VerCD lets us use automated continuous delivery (CD) to track and manage versioned dependencies of ML artifacts.
ML teams developing models at scale may find that the practices and tools, presented here as our five-step model life cycle and VerCD, developed at Uber ATG for self-driving vehicles can apply to a number of use cases, helping them iterate on their own infrastructure.
Self-driving vehicle components
Many of our self-driving vehicle components use ML models, enabling them to drive safely and accurately. A component consists of one or more ML models, and all the components together form our self-driving vehicle software:
- Perception: This component uses sensor information from the vehicle to detect actors in a given scene through ML models. It identifies probabilities for each object’s type (vehicle, pedestrian, bicycle, etc.) and its 3D coordinates. Detection allows the self-driving vehicle to see different objects in the environment, interpreting what and where they are.
- Prediction: This component uses the Perception component output (the type of actor and 3D coordinates of all actors in the scene), as well as high-definition maps, to predict actors’ future trajectories over n seconds in a given scene using ML models. The Prediction component allows the self-driving vehicle to anticipate where actors will most likely be located at various points in the future.
- Motion Planning: This component uses the self-driving vehicle’s destination, the predicted trajectories of all actors in the scene, the high definition map, and other mechanisms to plan the path of the vehicle.
- Control: This component steers the self-driving vehicle’s wheels and operates its brakes and accelerator to follow the path created by the Motion Planning component.
Each component builds on the output generated by the previous component to help safely steer our self-driving vehicles on the right course toward their destinations. The ML models that comprise these components go through our five-step iteration process, ensuring their optimal operation.
Our machine learning model life cycle
ML models make predictions, forecasts, and estimates based on training using historic data. For Uber ATG’s self-driving vehicle development, we use data collected from sensor-equipped vehicles—including LiDAR, cameras, and radar—in a wide variety of traffic situations as our training data. We offload this data from the vehicles to our servers, where our labeling team creates the labels that form the ground truth output that we want our ML models to learn.
Typically, the labeling team manually assigns labels to the actors in a given scene. These labels provide the location, shape, and other attributes such as object type for each actor in the scene. We use these labels to train our ML applications so they can later predict the information that the labels contain (types of objects and their coordinates) for new data captured from the sensors.
Once we’ve collected sufficient data, we process this information to develop ML models by using ground truth labels which include all the object types and coordinates along with high definition maps. Our ML stack, in which we develop and run the ML models, consists of multiple layers, from the ML applications themselves at the highest layer to the hardware they run on at the lowest layer. Middle layers include common ML libraries, such as TensorFlow and PyTorch, as well as GPU acceleration.
Our ML model life cycle, shown in Figure 1, below, consists of five stages.
We put our ML models through each stage of this life cycle in order to ensure that they exhibit high quality model, system, and hardware metrics before we deploy them to our self-driving vehicles.

Data ingestion
Once we’ve collected data to use in ML model training, it is ingested by our ML stack. The data ingestion process involves selecting the logs we plan to use and extracting the data from them.
We divide this log data into training data, testing data, and validation data; 75 percent of the logs go to training, 15 percent go to testing, and 10 percent go to validation. We use these proportions so that we train our ML models with the majority of the data, improving the model accuracy, then validate as we progress through training. Finally, we test model efficiency on a smaller portion of the data that hasn’t been seen during training. In a future article we will introduce GeoSplit, a data pipeline to select logs and split them between train, test and validation based on their geographical location.
Once we’ve divided the data, we extract it from our data generation logs using Petastorm, Uber ATG’s open source data access library for deep learning. The data we extract from the logs includes:
- Images from the vehicle’s cameras
- LiDAR 3D point information
- Radar information
- The state of the vehicle, including location, speed, acceleration and heading
- Map information, such as the vehicle’s route and lanes it used
- Ground truth labels
We save this information log-by-log on HDFS. We then use Apache Spark to extract data from multiple logs in parallel. Extracting data in this manner saves the data in an optimized format that our training pipeline can easily and quickly consume. When we run the training pipeline, we do not want to wait for long, heavy API calls to look up certain information. With this system, we have all the information (extracted data) we need stored in memory of the GPUs training the model after we load it from HDFS, ensuring that the pipeline can read the training data efficiently.
Figure 2, below, shows an example of the extraction processes running on the CPU cluster and saving the extracted data to HDFS:

Data validation
After the data pipeline selects and extracts the data that we will use for training, testing, and validation, we run queries to pull both the number of frames in a scene and the number of occurrences of the different label types in our data set. We compare the results of these queries to previous data sets to understand how conditions have changed and if they are expected or not. For example, if one of the label type occurrences increased drastically compared to other label types, then we trigger further analysis to understand this change and what effect it will have on the model.
Model training
Once we’ve properly selected, extracted, and validated our data, we have the resources we need to train our models. We leverage Horovod’s distributed training to quickly train them using the extracted data. We spread the data across different GPUs with data parallelism, shown in Figure 3, below, which means that we train the same model on different GPUs with different parts of the data. For example, if we use two GPUs, then the data is split into two, and the same model is trained on the first GPU with the first part of the data and on the second GPU with the second part of the data.
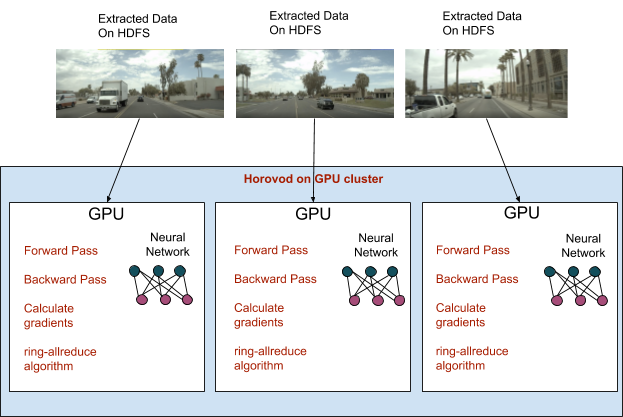
Each process performs forward and backward passes (a forward pass refers to calculating the output from the input for all the layers of the network as well as the loss from the loss function, while a backward pass refers to calculating the rate at which the loss changes with respect to every node in the network) independently of the other processes.
Next, we use Horovod’s ring-allreduce algorithm, enabling worker nodes to average gradients and disperse them to all the nodes without requiring a parameter server, distributing what each process has learned to all the other processes.
Leveraging TensorFlow and PyTorch as ML frameworks, engineers monitor training jobs through TensorBoard to verify that training is progressing as expected.
Uber ATG uses a hybrid approach to ML computing resources, with training jobs running in on-premise data centers powered by GPU and CPU clusters as well as running training jobs in the cloud.
To orchestrate training jobs using on-premise data centers with GPUs, we use Peloton, an open source unified resource scheduler developed by Uber. Peloton easily scales jobs to many GPUs or CPUs by being able to deploy our containers to the processes on the cluster. For cloud-based training, we use Kubernetes, which deploys and scales application containers across clusters of hosts.
Once we’ve trained our ML models with our selected, extracted, and validated data, we’re ready to assess how well they can accomplish their tasks, whether that’s identifying an object in a scene or predicting the path of an actor.
Model evaluation
After we’ve trained a given model, we evaluate the performance of the model itself as well as the performance of the entire system. We use both model-specific metrics and system metrics to test our ML models. We also evaluate hardware metrics to learn how fast our models perform on the hardware they will ultimately be deployed on.
Model-specific metrics
We compute a variety of model-specific metrics on a given test set. For example, for object detection models in our Perception component, we calculate model metrics such as precision (the percentage of detections that turned out to be correct) and recall (the proportion of the ground truth objects the model identified correctly).
Reviewing metrics gives us important insights regarding how our models are performing so that we can constantly enhance them. When we identify scenes where the model is not performing well, we adjust our data pipeline by including similar cases, giving the model more data to work with. In these instances, we sometimes give more weight to those scenes, meaning these data instances would contribute more to training the model versus other scenes in an effort to optimize the associated model.
As we train our model with more scenes, it ultimately performs better on them. However, we also want to ensure that our model performance is not regressing on existing scenes in which it was performing well.
System metrics
System metrics include safety and comfort measurements on the overall vehicle motion, performed over a large test set. We evaluate system metrics in the later stages of model development, once a given model’s model-specific metrics are exhibiting good results. Given that different ML models in the self-driving stack depend on each other (for example, our Prediction component uses the output of our Perception component), system metrics give us an important, comprehensive overview of how all the parts of the system perform between component versions. Measuring system metrics helps our team gain a more holistic view of how new models might affect other components in our system. Evaluating system metrics regularly allows us to spot and fix problems that happen in other components as a result of ML model updates.
Hardware metrics
Uber ATG has an internal benchmarking system that allows developers to profile a certain part of our software, such as the inference of a specific model, and evaluate how quickly it will run on our self-driving vehicles hardware. We use logged real-world data from our autonomous vehicles for this evaluation, ensuring that we know how our models will perform before deploying them.
Model serving
Once we’ve trained a model, verified that it works well in isolation, and confirmed it operates well with the rest of the system, we deploy it on an inference engine in the self-driving vehicle. This system runs input through the trained model so that it can generate its ouput. For example, running the Perception component would give the scene object types and their coordinates, while the Prediction component would give the objects’ trajectories in the future.
After we’ve served them, we continuously iterate on all our models to make them better using our five-step process, focusing on areas where the model needs improvement, which we typically discover during the model evaluation step.
Accelerating ML research with continuous integration and delivery
Although we boiled down our process into five steps, running from data set ingestion to model serving, each step in itself touches a variety of different systems, and the entire end-to-end workflow can easily span weeks. When driven by hand, there are many opportunities for human error, so we have invested in better tools and platforms to automate the workflow as much as possible.
One such platform, VerCD, tracks the dependencies between code, datasets, and models throughout the workflow, and also orchestrates the creation of these ML artifacts, making it a critical part of our process. Specifically, the workflows that are covered by VerCD start with the dataset extraction stage, cover model training, and conclude with computing metrics.
Due to the deep dependencies and development complexity of ML models in the self-driving domain, we needed a continuous delivery (CD) system that leverages agile principles to specifically track and manage versioned dependencies for ML artifacts. Although open source tools such as Kubeflow and TensorFlow Extended provide high-level orchestration to build data sets and train models, they require a significant amount of integration. Furthermore, they stop short at delivering a single workflow, and do not fully enable continuous delivery (CD) and continuous integration (CI).
On the other hand, there are traditional software tools, such as Git and Jenkins, that support versioning and CI/CD. Although these tools do not operate over the ML artifacts in our self-driving software, we took them as inspiration in building VerCD.
Opportunities for agile principles in ML workflows
Most software developers use version control, dependency tracking, continuous integration, and continuous delivery to produce frequent releases of software in an agile development process. Since the concepts are well-known for standard software development, here we will focus just on their applications in the space of ML workflows.
Version control principles applied to the ML domain allow the analysis of the impact of a change on some part of the ML workflow on downstream dependencies. For example, an ML engineer that updates a particular data set or model, or the supporting software for generating those artifacts, can better understand the impact of those changes if both code and ML artifact versions were tracked. Here, versioning allows us to track the impact of one developer’s changes independently from another developer’s changes, even though they are working in parallel.
An example of dependency tracking in the ML domain may be that adjustments to labels and raw data changes the nature of the data set, which in turn affects training results. Moreover, changes in the data extraction or model training code and configurations impact the artifacts they are responsible for building. Consequently, it doesn’t make sense to first train a model on an old data set and then extract a new data set because the data would be inconsistent with the trained model. In such cases, the data set should be extracted first, prior to model building, an ordering captured by dependency constraints.
While many mature tools exist to implement continuous delivery for traditional software codebases, we found that the same kind of tools for machine learning do not exist today at this level of maturity and standardization. Compared to the CD workflow, the ML workflow involves code, data, and models, and only the first of which is handled by traditional software engineering tools. Figure 4, below, illustrates some of those differences in the CD workflow, and Figure 5 illustrates the scope and complexity of the systems required to build a final ML artifact:
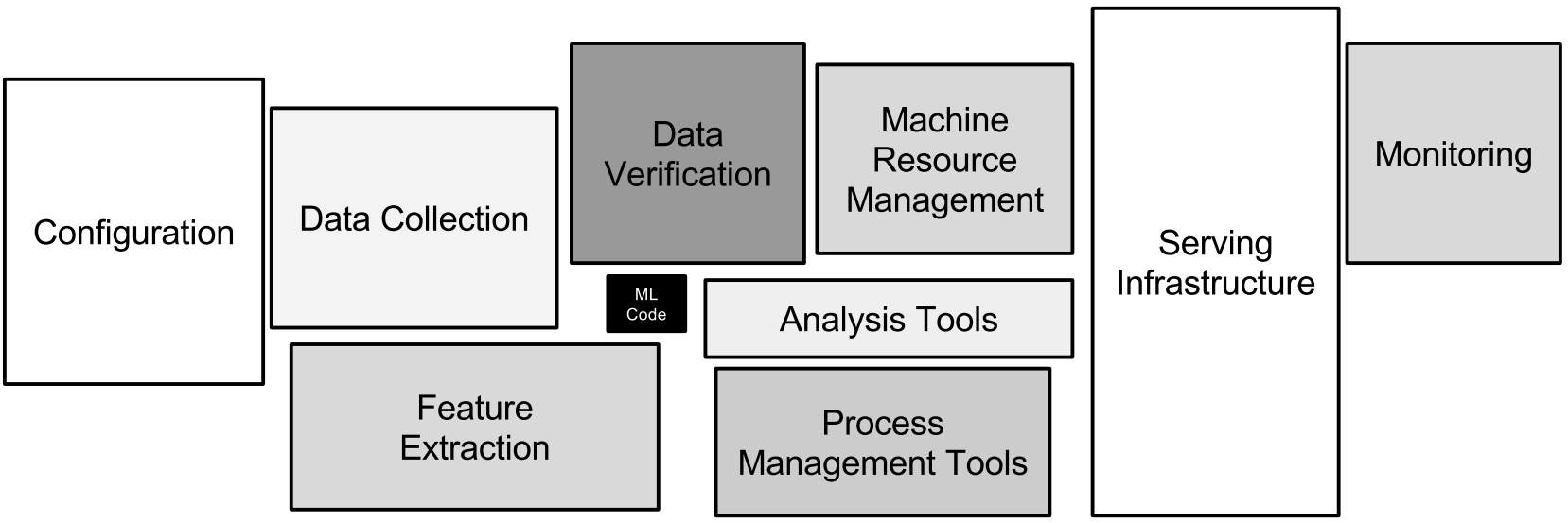
By implementing agile processes, CD enables engineers to adapt quickly to changing requirements, catch bugs early and often, and facilitate parallel development of all ML pieces, thereby improving developer productivity. However, frequent changes and parallel model development common in ML-heavy organizations require solving the problem of version control, a problem even more difficult in the self-driving domain due to the deep dependency graphs in the self-driving software stack, as described above. Such dependency graphs not only cover code, data, and models for a single ML model, but also dependencies between various ML models themselves.
Deep dependency graphs in the self-driving domain
In self-driving vehicle development, dependency graphs are particularly deep. This depth is a result of the layered architecture of the self-driving software stack, where each layer provides a different ML function. To demonstrate this, we present a high-level architecture of three ML models wired up sequentially in Figure 6, below:
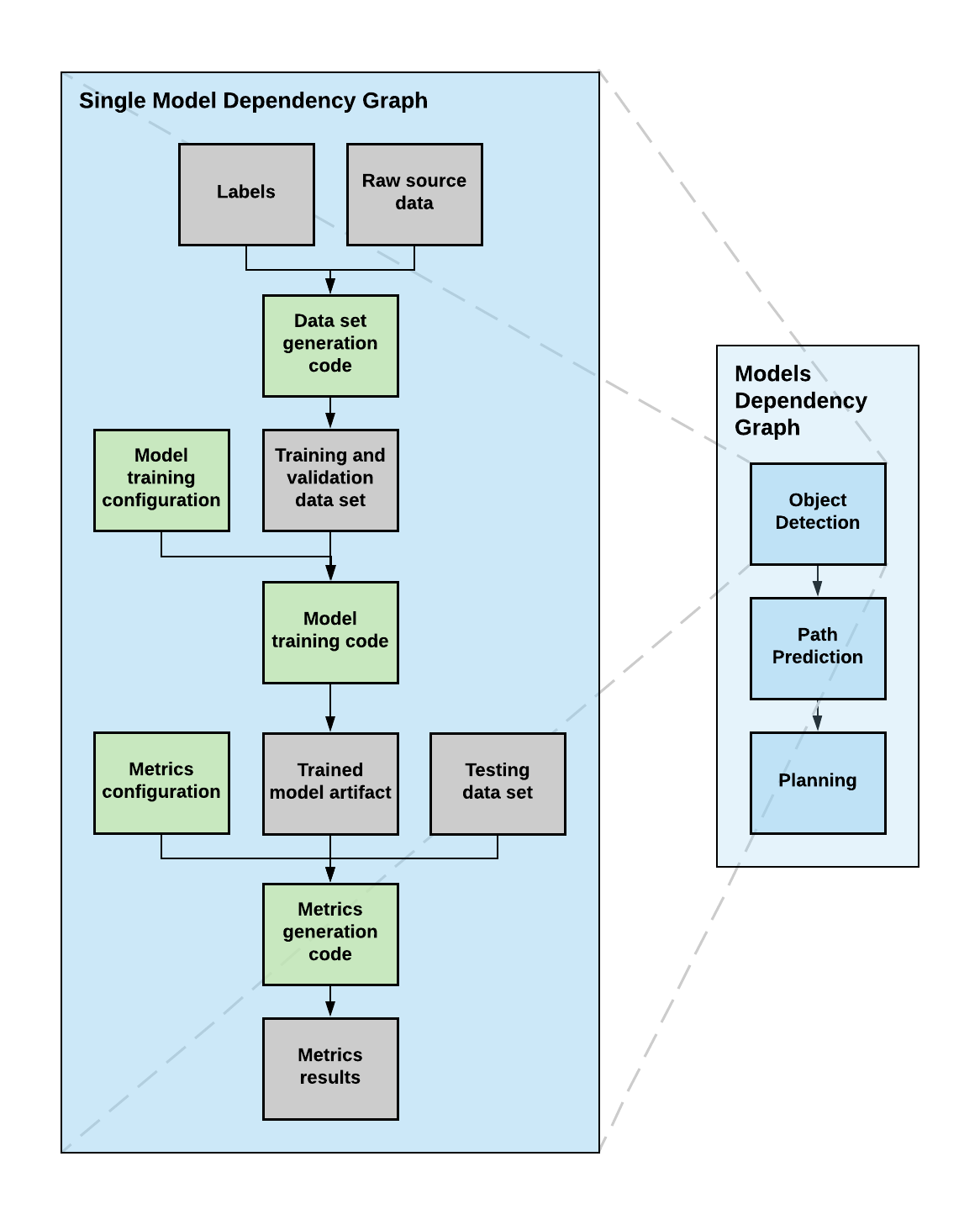
In Figure 6, above, our ML layers include:
- an object detection model whose input is raw sensor data,
- a path prediction model whose input is the set of objects detected by the object detection model,
- and a planning model whose inputs are the outputs of the path prediction model.
For each of these models, there is a complex dependency graph involving both code and artifacts, as shown in the diagram on the left side of Figure 6. The layer shown is itself several layers deep and involves generating three artifacts:
- A data set, composed of raw source data, bounding boxes around different objects in the source image data (i.e. labels), and the data set generation code.
- A trained model, which requires as input the data set artifact, the model training code, and configuration files governing model training.
- A metrics report, which requires as input the trained model artifact, the data set, and the metrics generation code.
Both the path prediction and planning models also have dependency graphs just as complex as the object detection model dependency graph; in some cases, the fully expanded graph is at least 15 levels deep when we look at the entire system. The depth of the graph poses a particular challenge for CD because parallel development of these ML components greatly increases the amount of versions that a CD system must manage.
Building VerCD for Uber ATG
We developed VerCD, a set of tools and microservices, to provide versioning and continuous delivery of all ML code and artifacts for Uber ATG’s self-driving vehicle software. Many of the components that make up VerCD are widely available, so the bulk of our engineering effort has been spent adding company-specific integrations to empower existing orchestrators to interact with the heterogeneous set of systems throughout the full end-to-end ML workflow.
Unlike traditional version control and continuous delivery systems, VerCD tracks all dependencies of each ML component, which often includes data and model artifacts in addition to code. This metadata service provided by VerCD tracks dependency graphs and is used by a continuous integration orchestrator to run entire ML workflow pipelines on a regular basis to produce data sets, trained models, and metrics. For engineers who often need to compare new experiments against a historical baseline, or examine historical builds to track down bugs, VerCD ensures that ML artifacts are always reproducible and traceable.
VerCD’s system architecture
When designing VerCD, we incorporated both experimental and production workflows. Not only did we need the system to support continuous integration and continuous delivery (CI/CD) workflows driven by an orchestrator, we also wanted VerCD to possess the functionality to build data sets, train models, and run metrics on behalf of engineers during experimentation. These multifaceted requirements meant that VerCD interfaces needed to be accessible to both humans and machines. To attain a reusable interface, we chose a REST API with Python library bindings, as shown in Figures 7 and 8, below.
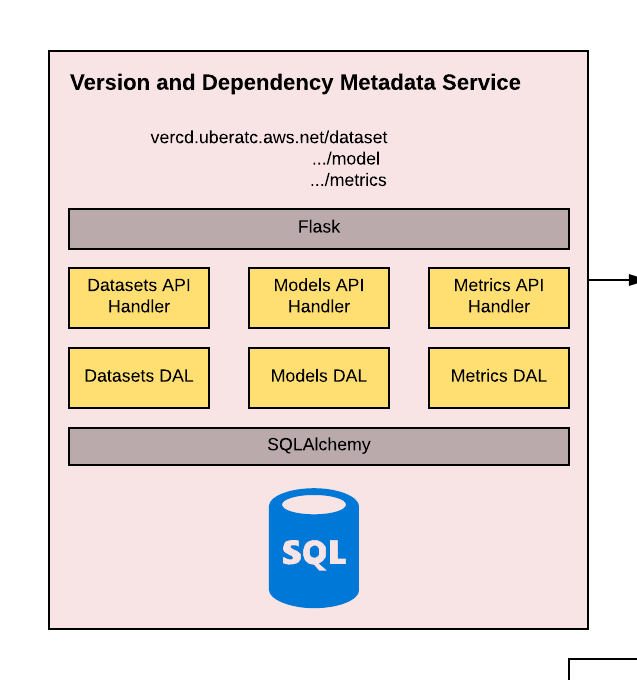
For the same reasons, VerCD was designed as a set of separate microservices for data set building, model training, and metrics computation. We chose to leverage a microservice-based architecture, a popular choice at Uber, where each microservice is responsible for a specific function, allowing the system to scale and provide isolation between the services. Whereas the VerCD CI/CD workflow is linear and fixed, the experimental workflow requires greater flexibility, often involving custom workflows and ad hoc runs that may focus only on a subset of data set extraction, model training, or metrics evaluation. Having a set of individual microservices allows for the flexibility necessary to leverage the same functionalities among these two different workflows.
To address dependency tracking, the user provides explicit dependencies of any data set, model, or metric builds that are registered with VerCD, and then the system manages this information in a database backend. As shown in Figure 9, below, we use a stock Jenkins orchestrator to kick off regular builds, and augment the functionality of the orchestrator by providing connectors and integration code so that it can interpret dependency metadata and operate ATG-specific systems.
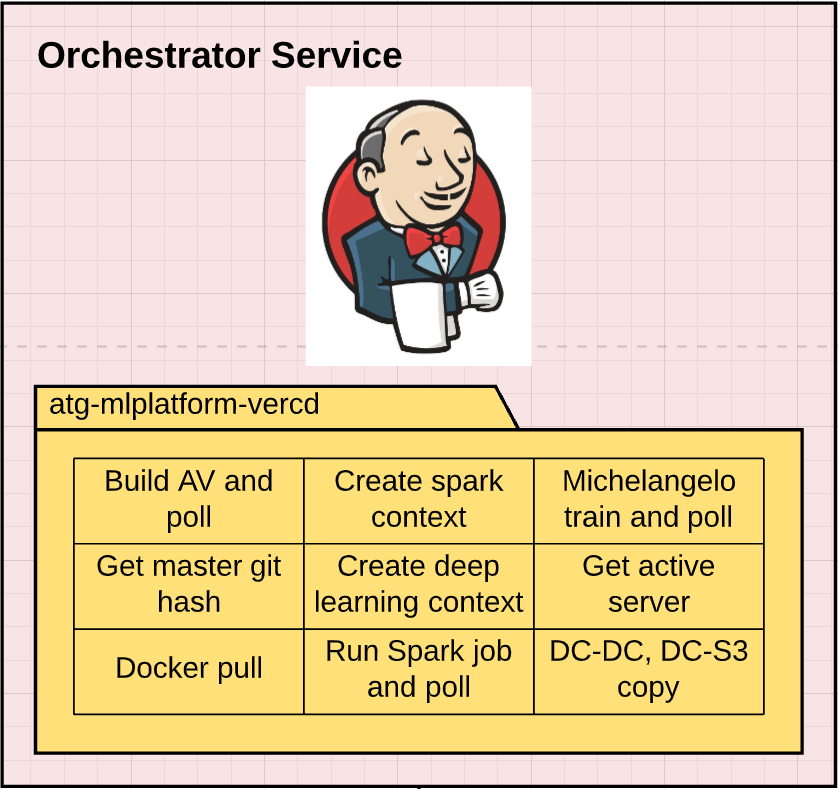
For example, our orchestrator can call these primitives to build a runtime of a self-driving vehicle for testing, interact with our code repository, or create images with deep learning or Apache Spark libraries. Other primitives include replicating data sets between data centers and to and from the cloud, should model training occur in these locations.
Example sequence of events: registering a new data set
Upon user-registration of a new data set, the VerCD Data set Service stores the dependency metadata in our database. For data sets, models, and metrics, the dependencies will include the Git hash of the repository and a path to the code entry point. Depending on which artifact is being built, there will also be references to other versioned elements (for example, versioned sets of labels and source data, or another versioned data set or model). We expect all dependencies to be versioned and immutable; in the case of data sets, for instance, a dependency would be a time series of sensor data from a versioned source.
As the last step of registration, the metadata service initiates a build with the orchestrator service. This kicks off an Apache Spark job to run the code, monitor the job (restarting if necessary), and finally, replicate the data set to managed storage locations (such as on-premise data centers or the cloud). Then, the metadata service is updated with the different locations to which we have replicated the data.
Microservice APIs
The APIs for each of our microservices were designed to facilitate programmatic access for both our production and experimental workflows. Since the goal of our system is to ensure reproducibility and traceability for data set building, model training, and metrics runs, we require all of the versioned immutable dependencies of these three workflows to be specified during registration. The APIs ensure traceability by providing access to build information, such as where artifacts were generated as well as the build lifecycle. Such information is particularly important when attempting to debug ML artifacts or regressions in performance.
Data set service API
The data set service is responsible for tracking the dependencies for building a given data set. The REST API supports the functions of creating a new data set, reading the metadata for a data set, updating the metadata of a data set, deleting a data set, and getting the artifact locations of the data set (such as in S3 or HDFS). When the user registers a new dataset, the backend orchestrator immediately proceeds to build and validate the dataset.
Datasets are uniquely identified by name and a version number, and the dependencies that are tracked by VerCD, which allows us to reproduce the exact same dataset artifact every time are:
- Sensor log IDs from the autonomous vehicle for each of train, test, and validation
- Git hash of the code used to extract the data set from raw sensor data
- Entry point for the extraction script
- Metadata describing the lifecycle of the data set and whether the specific version is the latest
Data sets may be annotated with their current lifecycle status such as when they were registered, when a build has failed or aborted, when a build succeeds and it is known to be good, when the data set is deprecated, and finally when the data set is at its end-of-life.
Model Service API
The model training service is responsible for tracking the dependencies for training a given model. The REST API supports the functions of train a new model, reading the metadata for it, updating the metadata of a registered model, and promoting to production. When the user registers a new model, the backend orchestrator immediately proceeds to train it.
Models are uniquely identified by name and version, and the dependencies that are tracked by VerCD, which allows us to reproduce the same training runs are:
- Versioned dataset as described in the previous section
- Git hash of the code used for training
- Entry point for the training script
- Path to training config files
- Path to the final trained artifacts
- Metadata describing the lifecycle of the data set and whether the specific version is the latest
Experimental, validation, and production workflows
Nearly all new ML models start as experiments, so VerCD supports a validation step to allow for a smooth transition between an experimental and production model. This validation step enforces additional constraints on model training to ensure reproducibility and traceability, both necessary to the production setting, whereas such constraints might have gotten in the way of quick development during experimentation.
As shown in Figure 10, below, once an ML engineer defines the experimental model in VerCD’s Model Service API, our system begins training it.
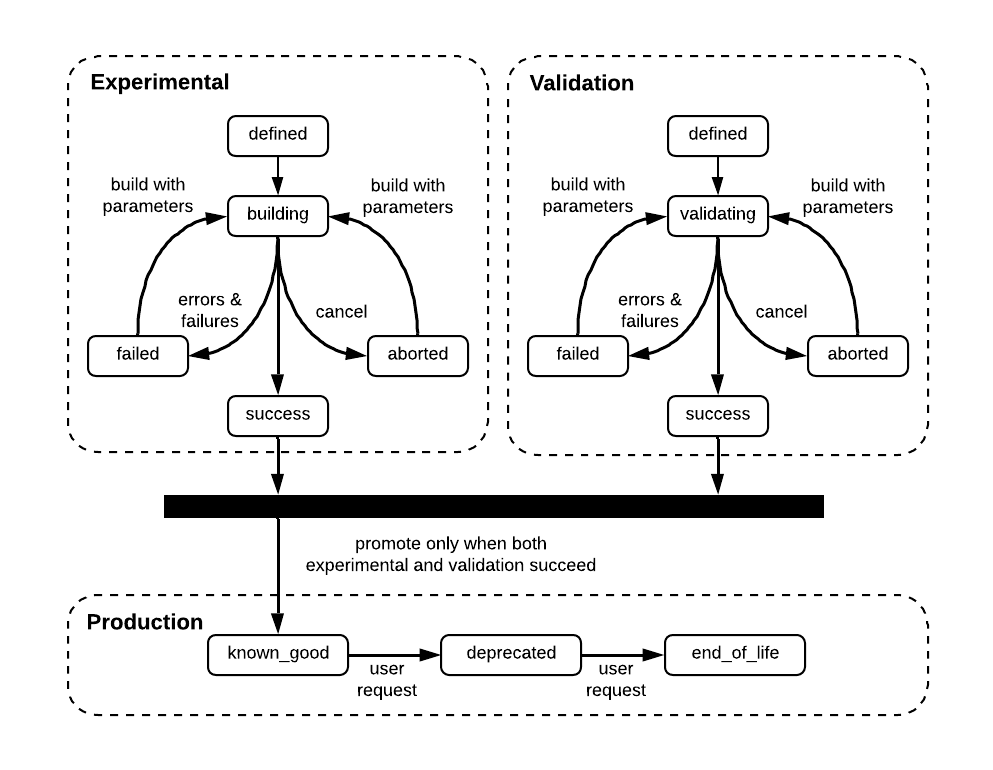
Depending on how it performs, we designate the model as failed, aborted, or successful. If a model fails or must be aborted, the ML engineer can opt to rebuild with a new set of parameters.
Asynchronously, VerCD can initiate validation of the model. As depicted in Figure 10, our experimental and validation processes include the same basic steps, except that the experimental diagram runs our model training code, while our validation diagram runs our model validation code. Our validation code performs various sanity checks on the model training pipeline, such as validating the build success, the output artifact exists, and the dependencies are immutable and versioned. Such checks will depend on the specific model being trained.
A model may be promoted to production only when both the experimental build succeeds and validation succeeds, and both may be invoked at any point in time and in any order. During the model promotion process, the user supplies a namespace, name, major version, and minor version. The endpoint then snapshots the training artifacts and versions them along with the model training metadata for future reference. Whereas during the experimental stage, the code and model performance fluctuate often. By the time the developer is ready to promote, the experiment will have largely yielded positive results and the system will be given the go-ahead to archive the result.
Metrics service API
The final step covered by VerCD of the ML workflows is the metrics evaluation of the trained model. Like our other microservices, in order to ensure traceability and reproducibility of the metrics, the architecture’s Metrics Service has a metadata service that tracks the necessary dependencies required to run the metrics job and its resulting artifacts. Similar to the case with data sets and model, we track:
- Versioned model as described in the previous section
- Git hash of the code used for running the metric jobs
- Entry point for the metrics running code
- Path to config files
- Metadata describing the lifecycle of the data set and whether the specific version is the latest
Data set and model onboarding and results
Today, VerCD provides regular daily integration tests for many of our data set building, model training, and metrics pipelines. These frequent integration tests ensure we know the current traceability and reproducibility statuses of these workflows, even with myriad versions of code, data, and model artifacts, as well as deep dependency graphs tying the entire system together.
For instance, the VerCD data set service has become a reliable source of truth for self-driving sensor training data for Uber ATG. Prior to having a service that can continuously deliver our sensor data, our data set generation process was very manual, both in terms of orchestration and record-keeping. By onboarding the data set building workflow onto VerCD, we have increased the frequency of fresh data set builds by over a factor of 10, leading to significant efficiency gains. Maintaining an inventory of frequently used data sets has also increased the iteration speed of ML engineers since the developer can continue their experimentation immediately without waiting several days for a new data set to be built.
Furthermore, we have also onboarded daily and weekly training jobs for the flagship object detection and path prediction models for our autonomous vehicles. This frequent cadence of training reduced the time to detect and fix certain bugs down to a few days, whereas prior to CICD training, the window for bugs was largely unknown, requiring the attention of many engineers.
Moving forward
Our ML model life cycle process and the tools that we’ve built to streamline it, such as VerCD, help us manage the many different models we use and iterate on models faster. These practices and solutions emerged from our need to work efficiently while developing an accurate self-driving vehicle system.
We have been able to make much progress by establishing the various workflow stages in ML development, and in turn developing the supporting systems such as VerCD to manage the increased complexity of the ML workflow. As our technology continues to mature, and increase in complexity and sophistication, relying on manual, human intervention to manage the ML workflow stages becomes increasingly infeasible. These tools enable engineers to make faster iterations of ML components, leading to higher performance of our self-driving vehicles.
Acknowledgments
This project is the result of collaboration with several teams and engineers at Uber, including Ivan Dimitrov, Luke Duncan, Joshua Goller, Yevgeni Litvin, and Sidney Zhang.

Yu Guo
Yu Guo is a Senior Manager of Software Engineering at Uber ATG.

Khalid Ashmawy
Khalid Ashmawy is a Senior Tech Lead Manager at Uber ATG.

Eric Huang
Eric Huang is a Senior Software Engineer and VerCD tech lead at Uber ATG.

Wei Zeng
Wei Zeng is a Software Engineer for VerCD at Uber ATG.
Posted by Yu Guo, Khalid Ashmawy, Eric Huang, Wei Zeng
Related articles





Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
