Ludwig v0.3 Introduces Hyperparameter Optimization, Transformers and TensorFlow 2 support
October 6, 2020 / Global
In February 2019, Uber released Ludwig, an open source, code-free deep learning (DL) toolbox that gives non-programmers and advanced machine learning (ML) practitioners alike the power to develop models for a variety of DL tasks. With use cases spanning text classification, natural language understanding, image classification, and time series forecasting, among many others, Ludwig gives users the ability to easily train and test DL models, and the power to tweak parameters for exploring architectures, comparing models, and improving performance.
Today, we are excited to release Ludwig version 0.3, featuring several updates that take our framework to the next level. With the help and support of Ludwig’s growing community of users and contributors, and in collaboration with Stanford University’s HazyResearch group, our team has developed new features that improve Ludwig’s architecture, expand its automated machine learning (AutoML) capabilities, provide more options to the users, and overcome previous limitations in version 0.2.
Version 0.3 of Ludwig ships with:
- A hyperparameter optimization mechanism that squeezes additional performance from models.
- Code-free integration with Hugging Face’s Transformers repository, giving users access to state-of-the-art pre-trained models like GPT-2, T5, Electra, and DistilBERT for natural language processing tasks including text classification, sentiment analysis, named entity recognition, question answering, and much more.
- A new, faster, modular and extensible backend based on TensorFlow 2.
- Support for many new data formats, including TSV, Apache Parquet, JSON and JSONL.
- Out-of-the-box k-fold cross validation capability.
- An integration with Weights and Biases for monitoring and managing multiple model training processes.
- A new vector data type that supports noisy labels for weak supervision.
Modularity is the main theme of this release: a new backend with improved code structuring allowed for increased expandability, making adding new encoders, new data formats, new integrations and new feature types much easier. The same modularity principle was applied to design the new hyperopt feature, making it easy to add new samplers and executors. All these improvements make Ludwig a much better platform to build upon than the previous version, and a more solid foundation for future expansions and improvements.
We are very thankful for the many contributions from the open source community and encourage others to get involved in Ludwig’s development for future releases.
Hyperparameter optimization
Deep learning models often have several hyperparameters related to the training process (e.g. the learning rate or which optimizer to use), the dimensions of the model architecture (e.g. the number of layers or filters), and even the architecture choice itself (e.g. whether to use a transformer or a recurrent network to encode a textual input). Finding the parameters that yield the best performance on a data set is a time-consuming job that can be automated by hyperparameter optimization techniques.
To this end, we introduce a new command, hyperopt, that performs automated hyperparameter optimization based on the user’s desired configuration and hyperparameters. In Ludwig style, hyperparameters are typed, and these types influence how they are going to be sampled and optimized. Supported hyperparameter types are float, int, and category. To set the value of a hyperparameter from the configuration, users can use dot notation (e.g. training.learning_rate, utterance.num_layers or training.optimizer.type).
A float hyperparameter can be defined by specifying its minimum value, maximum value, and scale, for example:

An int hyperparameter can be defined by specifying just the minimum and maximum values, for example:

A category hyperparameter can be defined by specifying a list of possible values, for example:
 Additionally, users can specify which hyperparameter optimization sampler they’d like to use and how they’d like to execute their optimization. Ludwig currently supports grid, random, and pysot strategies, with the latter making use of PySOT bayesian optimization strategy, and can execute optimizations locally in serial order, in parallel, or remotely on a cluster using Fiber, Uber’s open source distributed computing library.
Additionally, users can specify which hyperparameter optimization sampler they’d like to use and how they’d like to execute their optimization. Ludwig currently supports grid, random, and pysot strategies, with the latter making use of PySOT bayesian optimization strategy, and can execute optimizations locally in serial order, in parallel, or remotely on a cluster using Fiber, Uber’s open source distributed computing library.

Finally, users can specify what metric to optimize for by describing the feature and metric:

Putting it all together, below is a full example of how to leverage Ludwig’s new hyperparameter optimization feature:

In order to perform the hyperparameter optimization on a given model, users just have to run:

The output of the hyperparameter optimization can be visualized with two new visualization commands: hyperopt_report for visualizing performance distributions over individual and pairs of hyperparameters and hyperopt_hiplot for comparing all parameter combinations.
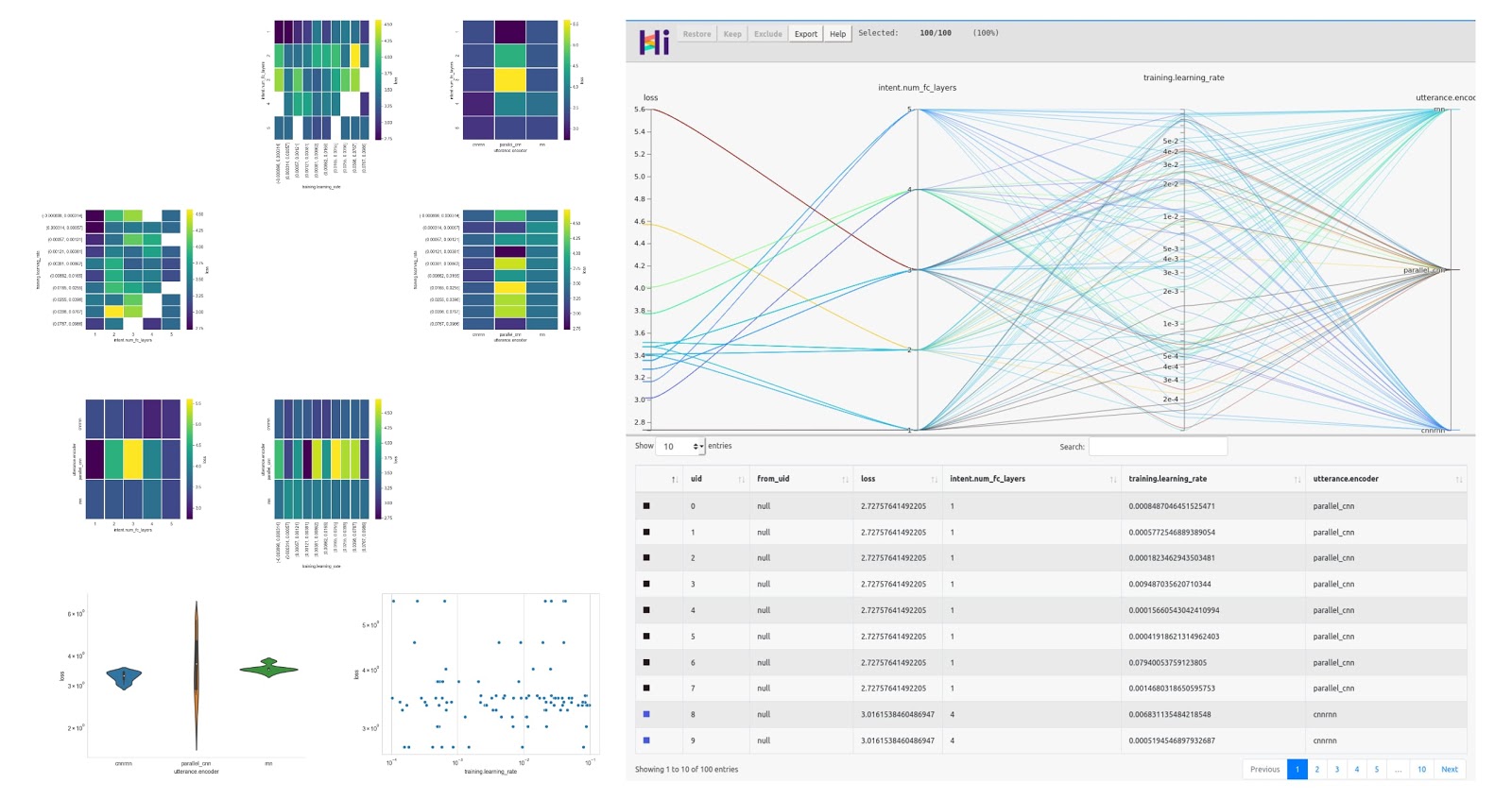
The hyperparameter optimization architecture is easy to expand and we plan to integrate with additional samplers and executors in the near future, like RayTune.
Ludwig version 0.3 features even more parameters than the examples described above, thanks to the contribution of Kaushik Bokka, Jiale Zhi and David Erilsson. Learn more about the new release’s hyperparameter optimization functionality in the official Ludwig user guide.
Transformers
In recent years, the use of pre-trained Transformers for ML model development has introduced substantial improvements in many natural language processing tasks. In Ludwig version 0.2, we introduced support for BERT, a type of pre-trained Transformer. In version 0.3 we extend this functionality by adding an integration with Hugging Face’s Transformers repository that gives users the ability to access and fine-tune any Transformer model in their collection.
Here is an example input feature:
input_features:

This feature enables anyone to train a state of the art NLP model without writing any code, and was made possible thanks to the contributions of Avanika Narayan and support from the Hugging Face team. For more details on the new text encoders check the user guide.
New backend
In this release, Ludwig has changed a lot under the hood. Originally, Ludwig was designed around TensorFlow 1 and its graph abstraction paradigm. Following the release of TensorFlow 2, which allows an imperative programming paradigm, and its much improved restructuring of APIs around object-oriented principles, we decided to fully port Ludwig to take advantage of these improvements. Unfortunately, the shift in paradigms meant that some of Ludwig’s components had to be rewritten from the ground up. Nonetheless, Ludwig version 0.3 ships with a revamped, more modular, and easier-to-extend backend based on TensorFlow 2, lending to greater flexibility all around.
Now, users can write their own encoders and decoders by simply extending the TensorFlow 2 Layer object and respective output dimensions:

In addition to simplifying the definition of model components, (e.g., encoders, decoders, and combiners), Ludwig’s new TensorFlow 2 backend makes it easy for users to share their pretrained models and modules. In the future, we intend to making model sharing even more accessible by launching a model hub. We will keep the community posted on this exciting new addition!
New data formats
One of the main limitations of Ludwig so far was the fact that it only supported CSV files as input format and Pandas DataFrames when using the programmatic APIs. In version 0.3 we are adding support to many new popular data formats: in memory dictionaries, excel, feather, fwf, hdf5, html tables, json, jsonl, parquet, pickle, sas, spss, stata and tsv.
Users can specify the data format of their inputs with a specific data_format parameter both in the CLI interface and in the programmatic API. If it is not specified, Ludwig will figure out the format automatically depending on the object type or the file extension.
Here is a CLI usage example
 And here is an API usage example:
And here is an API usage example:

Weights and Biases
Weights and Biases is a tool that lets users track their model training process and results. The Weights and Biases team, led by Chris van Pelt and Boris Dayma, contributed a new integration to Ludwig version 0.3 that allows models trained in Ludwig to be automatically monitored in their platform, so that different runs and experiments can be tracked and compared easily through a visual interface.
To use Ludwig’s new Weights and Biases integration, users just have to add the –wandb parameter to their commands. This will allow training and experiments to be tracked and interacted with on the corresponding Weights and Biases page.
And here is an usage example: And here you can find a Colab to play with this integration!
And here you can find a Colab to play with this integration!
K-fold cross-validation
K-fold cross-validation is an experimentation protocol widely used in machine learning that splits a data set into folds and, over the course of several experiments, uses each fold once as a validation set and the remaining folds as a training set. This prevents overfitting to a specific development or test set, because the performance of models on all test sets are averaged.
Since deep learning models are usually trained on large amounts of data, development and test sets are large enough that we are confident model performance will generalize to unseen data from the same distribution. However, when deep learning is applied to smaller data sets through transfer learning on pre-trained models, model performance on a single development or test set may not be a good indication of how well the model will generalize to unseen data and it will be easier to overfit. In such scenarios, using k-fold cross-validation may be very useful. With the help of key contributor Jim Thompson (who also helped on porting to TensorFlow 2), we added k-fold cross-validation functionality to Ludwig version 0.3.
Leveraging k-fold cross-validation in Ludwig is very straightforward; users just need to specify a data set, the number of folds, and the configuration, as shown in the example below:
Vector data type
A new addition among Ludwig-supported data types is the vector feature. This data type is provided with both an input encoder and an output decoder. The input encoder allows users to provide an entire vector as input, which can be obtained either by a separate model or a coherent set of observations from sensors or other event-detecting devices. The encoder allows users to specify a stack of fully connected layers to map the input vector to a hidden vector. The decoder, on the other hand, allows users to predict an entire vector of values at once by performing multiple regressions simultaneously. This also allows model training by providing noisy distributions as targets, like what happens with noise-aware losses used in weak supervision and distillation techniques.
Here is an example of how to specify a vector input feature:
And here is an example of how to specify a vector output feature:
Smaller improvements based on user feedback
Ludwig v0.3 contains a huge number of bug fixes and minor improvements in all areas, including new encoders, the tracking of metrics, improved test coverage, improved documentation, new examples through notebooks, faster and more flexible preprocessing, and new languages supported for text preprocessing. Learn more about these improvements by checking out the updated Ludwig user guide and changelog.
Moving forward
With the addition of hyperparameter optimization, Ludwig version 0.3 has solidified itself as a powerful solution for open-source AutoML, training and development for deep learning models.
While making the transition to TensorFlow 2 and integrating with the Transformer library enabled us to better support pretrained models, in the future we intend to broaden our selection of pretrained models for all data types, including images.
We hope that these new additions to the project and the improved documentation will help users get started with the software and better support our existing users and contributors, without whom none of this would be possible!
Interested in learning more about Ludwig? Check out our official site and watch our video tutorial!
Acknowledgments
We want to thank all our amazing open source contributors:
Jim Thompson for the help on the new backend and the K-fold cross validation, Kaushik Bokka, David Eriksson and Jiale Zhi for their help on the hyperparameter optimization, Avanika Narayan and the Hugging Face team (Thomas and Julien in particular) for their help on the Transformers integration, the Weights and Biases team (Chris and Boris in particular) for their help on the integration, and all the others that contributed to improve Ludwig!
We also want to thank Prof. Chris Ré and the whole of the Hazy Research group at Stanford University for supporting this release.

Piero Molino
Piero is a Staff Research Scientist in the Hazy research group at Stanford University. He is a former founding member of Uber AI where he created Ludwig, worked on applied projects (COTA, Graph Learning for Uber Eats, Uber’s Dialogue System) and published research on NLP, Dialogue, Visualization, Graph Learning, Reinforcement Learning and Computer Vision.

Yaroslav Dudin
Yaroslav Dudin is a senior software engineer on Uber's New Mobility Optimization team.
Posted by Kerri Brown, Piero Molino, Yaroslav Dudin
Related articles





Most popular

A beginner’s guide to Uber vouchers for transit agency riders

Uber Earner x Miami HEAT Ticket Sweepstakes OFFICIAL RULES

Case study: Tri-Rail’s role in paving the way for effortless commuting

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
