
At Uber, we provide a centralized, reliable, and interactive logging platform that empowers engineers to work quickly and confidently at scale. The logs are tagged with a rich set of contextual key value pairs, with which engineers can slice and dice their data to surface abnormal or interesting patterns that can guide product improvement. Right now, the platform is ingesting millions of logs per second from thousands of services across regions, storing several PBs worth, and serving hundreds of queries per second from both dashboards and programs.
Since starting with ELK for logging in 2014, our system traffic volume and use case variance had both grown significantly. As we reached a scale bottleneck to support this rapidly growing traffic, we decided to take our insights about Uber’s many logging use cases and build our next-gen platform to fundamentally improve the reliability, scalability, performance, and most importantly to ensure a pleasant experience for both its users and operators.
Background
In the past few years, the organic logging traffic growth resulted in a massive platform deployment size and the user requirements evolved significantly too. Both surfaced a lot of challenges to the ELK based platform, which were not visible at lower scale:
- Log schema: Our logs are semi-structured. ES (Elasticsearch) infers schemas automatically, keeps it consistent across the cluster, and enforces it on following logs. Incompatible field types cause type conflict error in ES, which drops the offending logs. While enforcing a consistent schema is reasonable for business events with well-defined structures, for logging this leads to significant reduction in developer productivity because log schema organically evolves over time. For example, a large API platform can be updated by hundreds of engineers, accumulating thousands of fields in the ES index mapping and there is a high chance for different engineers to use the same field name, but with different types in field values, which leads to type conflicts in ES. Forcing engineers to learn about the existing schema and maintain its consistency just to print some service logs is inefficient. Ideally, the platform should treat schema changes as a norm and be able to handle fields with multiple types for the users.
- Operational cost: We had to run 20+ ES clusters in each region to limit the blast radius if a cluster was affected negatively by heavy queries or mapping explosions. The number of Logstash pipelines was even higher with 50+ per region to accommodate special use cases and custom configurations. Both expensive queries and mapping explosions could degrade the ES cluster severely and sometimes even “freeze” it, when we had to restart the cluster to bring it back. As the number of clusters increased, this kind of outage grew more frequent. Despite our best efforts to automate processes such as detecting and disabling fields that would cause mapping explosions and type conflicts, rebalancing traffic among ES clusters, and so on, manual intervention for resolving issues like type conflicts was still inevitable. We would like a platform that is able to support our organization’s large scale and new use cases without incurring as much operational overhead.
- Hardware Cost: Indexing fields is pretty costly in ES, because it needs to build and maintain sophisticated inverted indexing and forward indexing structures, write it to transaction log, flush the in-memory buffer periodically to disk, and perform regular background merges to keep the number of flushed index segments from growing unbounded, all of which requires significant processing power and increases the latency for logs to become queryable. So instead of indexing all fields in the logs, our ES clusters were configured to index those up to three levels. But ingesting all of the generated logs still consumed a lot of hardware resources and was too expensive to scale.
- Aggregation: As found in our production environment, more than 80% queries are aggregation queries, such as terms, histogram and percentile aggregations. While ES has made improvements to optimize forward indexing structures, it is nonetheless not designed to support fast aggregations across large datasets. The performance inefficiency led to an unpleasant user experience. For example, the critical dashboards for a service with large log volume loaded very slowly when querying last 1h logs (around 1.3TB) and frequently timed out when querying last 6h logs, making it impossible to diagnose production issues.
With our ELK based platform, we only managed to ingest part of the logs generated inside Uber. The already-massive deployment and many inherent inefficiencies in our ELK based platform made it prohibitively expensive to scale in order to ingest all logs and provide a complete, high-resolution overview of our production environment.
Introducing a New Schema-Agnostic Log Analytic Platform
We aim to collect all logs generated in Uber, store and serve them with low platform cost, and ensure a pleasant experience for both users and operators. Overall, we have designed a new log analytics platform with these key requirements in mind:
- Functionalities:
- Schema-agnostic for developer productivity
- Efficient support of aggregation queries
- Support multi-region and cross-tenant queries
- Efficiency and maintenance:
- Support multi-tenant properly to consolidate deployment
- Reduce cost and be able to handle 10X scale
- Improve reliability and simplify operation
- Transparent migration from ELK platform, e.g. users can keep using Kibana to analyze logs interactively.
We evaluated a wide range of logging products and storage solutions. Eventually, we decided to use ClickHouse, an open source distributed columnar DBMS, as the underlying logging storage technology and built an abstraction layer above it to support the schema-agnostic data model.
Schema-agnostic data model
Our raw logs are formatted into JSON, whose schema can change gradually. While emitting log messages like “Job finished”, developers can tag them with key value pairs as context. The log message and tags are encoded in the output logs as fields. The tag values can be primitive types like number or string and composite types like array or object. In Uber, logs have 40+ fields on average, all treated equally by our platform and providing rich context.
To support schema evolution natively, we track all types seen in a field during ingestion in the log schema, as shown below. The schema is persisted and used during query execution, explained later. Each field type is tagged with a timestamp, which indicates when the type is observed and can be used to purge stale info from the schema.

ClickHouse table schema
In the beginning, we tried two table schemas to keep logs in ClickHouse. The first schema only kept raw logs in json format under the _source column and during query execution log fields were accessed via ClickHouse’s json unmarshal function, visitParamExtractString. But the query was too slow with this schema, due to the overhead of json unmarshalling.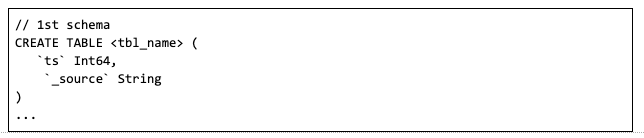
The second schema not only kept raw logs in _source for quick raw log retrieval, but also flattened all fields to dedicated columns with field names and types to handle type conflicts, so that the field values could be queried directly from the columns. We found the query could be 50x faster than the first schema. But this model didn’t scale either, because the number of disk files grew linearly with the number of table columns and ClickHouse stopped responding to writes and reads, overburdened by merging parts in the background.

In the end, we arrived at the table schema shown below (simplified for brevity) to provide good query performance while preventing the number of disk files from growing unbounded. Basically, each log is flattened into a set of key-value pairs; those pairs are grouped by their value types like String, Number, or StringArray. In the table, we use a pair of arrays to store those groups of key-value pairs: (string.names, string.values) is used to store the group of key-value pairs with string values, (number_array.names, number_array.values) for the key-value pairs with number array values, and so on.
The common metadata fields are kept in dedicated columns for fast retrieval. In particular, the _namespace column allows us to support multi-tenant effectively. Please note that we always keep raw logs in the _source column to avoid reconstructing the full log on the fly, which can be complex and costly for nested structures. Even though we essentially store logs twice, it doesn’t add too much disk usage, due to effective compression. As experimented with our production traffic, the compression ratio could be 3x (even 30x in some cases) with this table schema, comparable to and often better than what we could achieve with ES.
During query execution, we use ClickHouse’s array functions to access field values, such as string.values[indexOf(string.names, ‘endpoint’)] = ‘/health’. We can access any fields from those array columns about 5x faster than by unmarshalling the raw logs to retrieve values. Extracting field values from the array column is slower than accessing them from the dedicated column as compared with the second schema above. Considering most of the filters are evaluated upon fields, we propose to write field values in dedicated columns if they are accessed commonly to speedup query, i.e. indexing fields adaptively, leveraging the materialized column feature in ClickHouse.
In addition to the performance and flexibility for query execution, this table schema allows for efficient log ingestion as well. As shown in our experiments, a single ClickHouse node could ingest 300K logs per second, about ten times what a single ES node could achieve.
Ingest all and query any, fast
In this section, we discuss how to ingest all logs into the ClickHouse tables created as above, no matter how the log schema evolves; query them out via a set of custom, high-level interfaces, which allow field type to be inferred; and use materialized columns adaptively to boost up query performance based on access patterns.
Schema-free ingestion
Logs are critical for oncall engineers to debug outages. In order to reduce MTTR, we strive to make logs ingestion as fast and as complete as possible in our log analytics platform.
As shown in the figure above, logs are ingested from Kafka to ClickHouse. Our platform’s ingestion pipeline has two major parts: ingester and batcher. The ingester consumes logs from Kafka and flattens the JSON-formatted logs into key-value pairs. Those key-value pairs are grouped by their value type and sent downstream via m3msg. The ingester won’t commit Kafka offsets until it receives acks from the batcher, which means the logs have been successfully written to ClickHouse, providing at-least once delivery guarantee. The m3msg transport also makes it easy to implement back pressure along the ingestion pipeline that leverages Kafka to buffer logs when our downstream slows down.
ClickHouse works best when writing in large batches, so we pack multiple tenants into tables properly, in order to ensure fast enough batching to reduce ingestion latency without increasing write rate. During ingestion, the log schema is extracted from the current log batches and persisted in the metadata stored by the batcher for query service in order to generate SQL. Unlike with ES, where index update is a blocking step on the data ingestion path, we continue the data ingestion to ClickHouse even with errors updating schema. We assume log schema can always evolve but most tags are repetitive, so it’s highly possible that subsequent batches can update the schema and make it in sync with logs in ClickHouse eventually. What’s more, the metadata store can keep very large log schemas, making our platform much more immune to the mapping explosions issue.
Type-aware query
It would be daunting to ask users to write ClickHouse SQL directly to retrieve logs under our custom table schema. It requires the user to know how array columns are used to represent the key-value pairs, how logs may be moved between tables to improve the placement of data, and how adaptive indexing is built based on query history, etc. To provide a familiar and pleasant user experience, we provide a set of high-level query interfaces crafted for our logging use cases, and have built a query service to generate SQLs automatically and interact with the ClickHouse clusters.
Query interface
The query interface is demonstrated below, simplified for brevity. RawQuery retrieves raw logs with filtering conditions; AggregationQuery calculates statistics about logs after grouping them by the raw values of some fields; and BucketQuery enables grouping logs by the result of an expression evaluated against the log, such as to bucketize the logs every 10min. Please note that the Calculation clause can have its own Filter clause to leverage the conditional aggregation feature in ClickHouse, which allows for the convenient expression of complex analytics. Furthermore, all those queries can access logs from a list of namespaces (i.e. tenants), using merge() function behind the scenes.

SQL generation
The query service generates ClickHouse SQLs from requests in two major phases: logical and physical. During the logical phase, the query request is walked through to collect field type constraints, and field existence is checked against the log schema collected during ingestion time. After walking through the query request, a set of field names and their type constraints are collected. For example, field “foo” should access String or StringArray typed values because it’s present in a filter expression like “foo”=”abc”; or field “bar” should access String, Number, StringArray or NumberArray typed values because it’s used in a group-by, etc.
The next step of the logical phase is to resolve field type(s) by comparing the type constraints collected from the query request and the field type kept in the log schema. For example, field “foo,” as mentioned above, may only have a String type in the schema, and so we should only access the columns containing String values while generating the ClickHouse SQL; field “bar” in the example above may have both String and Number type in the schema, and so we should access both typed values in a single SQL.
Type conversion may be needed when accessing multiple typed values from a field, as the expressions in the SQL expect values of a specific type from that field. Currently, we follow the rules shown below to convert non-String types to String or StringArray, according to the operators used in expressions. The scalar and array types are also convertible when the former is the base type of the later.
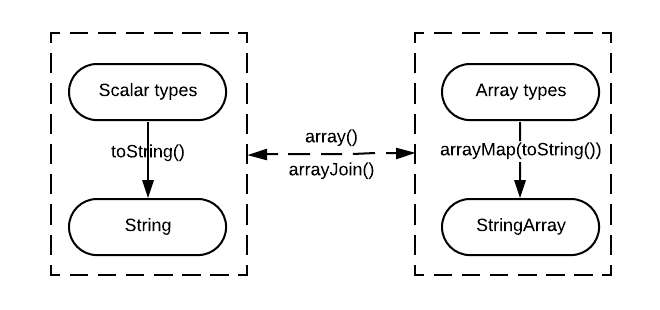
In this way, the type conflict issue impacting the usability of the ELK-based platform is simply treated as a norm in the new logging platform. At the end of the logical phase, the field types are determined and the table column access expressions are also figured out accordingly. For example, with the field “bar” we may end up with the following SQL expression:

The column expressions resolved in the logical phase tell us about how to access the values of each field. The various expressions specified in the query request are translated into the final SQL during the physical phase. At the end of the physical phase, the query settings are determined, which control how ClickHouse executes the query, such as how many threads it should allocate for the task. Here is an example of a typical translation:

While ES decides field type at write time, our platform delays field type resolution until the query, simplifying ingestion logic and improving data completeness greatly. In general, the write path has much less error budget than the query path, because it can’t be down for too long, otherwise the logs pile up in Kafka and are automatically deleted. With more error budgets, we can iterate the query service much faster and even apply sophisticated transformations to the logs while retrieving them, instead of doing complex preprocessing in the ingestion pipeline, like Logstash.
Adaptive indexing
After analyzing our production queries, we observed that only 5% of the indexed fields were being used. This meant that the indexing costs for the other 95% of fields were wasted in ES. Therefore we have designed the platform to ingest all logs and pay no upfront cost to index fields. However we also selectively index the most frequently queried fields by materializing them to dedicated columns for query speedup, such as below:

ClickHouse backfills field values to the materialized column in the background asynchronously, without blocking ongoing reads and writes. One of its cooler features is that when querying a materialized column, it can use the pre-populated values from the materialized column where applicable, and transparently fall back to array-based value extraction in cases where the materialized column has not yet been backfilled. This simplifies our logic to compose the SQL queries to use materialized columns. Basically, whether a field is materialized is checked while resolving the column access expression, and the fast access path is used whenever possible. as shown below:

Materializing fields adds extra cost on the write path, so the platform periodically cleans up those columns infrequently accessed.
Reliability, Scalability, Multi-region and Multi-tenant
In this section, we touch on the architecture design that enables our logging infrastructure to reliably scale up, how it works across regions, and how resource governance is applied for multi-tenant.
We use the ReplicatedMergeTable engine in ClickHouse and set RF=2 to improve the system reliability with extra redundancy. The replication is asynchronous and multi-master, so logs can be written to any available replica in the replica set, and queries can access logs from any replica as well. Therefore, losing one node temporarily, such as to a restart or upgrade, doesn’t impact the system availability and data durability. But due to asynchronous replication, it’s possible to lose some amount of logs when a node is lost permanently. We could configure replication to be synchronous for higher consistency, but for now we find that to be an acceptable trade-off for better availability.
To scale the system out, we turn to the table sharding support in ClickHouse. A table can have multiple shards. Currently we simply shard every table over the whole ClickHouse cluster. ClickHouse furthermore allows us to configure queries to skip unavailable shards and return results at their best availability, which is particularly useful when fast response is more desired than accuracy.
ClickHouse only provided very basic support for cluster management out of the box, so we enhanced this functionality in the admin service of the platform. Overall it’s like a state-driven cluster management framework. The goal states of the cluster describe what the cluster should be like and are kept in the metadata store. Administrative workflows are implemented upon the framework and invoked by the admin service upon goal state changes or as scheduled to transition the cluster from actual states to goal states. The workflows are idempotent and can be retried safely to manage the cluster in a fault-tolerant manner. Common operations–like onboarding tenants, expanding the cluster, replacing nodes, materializing fields, optimizing tenant placement, and purging old logs–are all reliably automated with this framework.
The distributed table feature is used to conveniently query logs from all shards. The distributed table doesn’t store any physical data, but requires the cluster info about all shards to fanout queries and aggregate partial results properly. In the beginning, we created all distributed tables on all ClickHouse nodes so that any one could serve distributed queries. But as we expanded our cluster to hundreds of nodes across regions, we found it hard to propagate cluster info from the global metadata store to all distributed tables in a timely and consistent manner. So we separated the nodes into query and data roles, then only query nodes need cluster topology info to serve distributed queries. Because the number of query nodes are much lower, it’s easy to propagate the cluster info to them and converge quickly. In addition, the separation of roles allows us to use different hardware SKUs for query and data nodes and scale them independently. The query nodes, for example, are pretty much stateless and very easy to scale.
 With this architecture, we can linearly scale the cluster by adding more CH nodes. But to support multi-tenant reliably, we also need proper isolation between tenants for both ingestion and query. In the ingester, we impose rate limits on each tenant. In query service, we control the max number of in-flight queries from each tenant, and allocate the resources to each query conservatively, like query threads, to leave rooms for concurrent queries and ingestion load.
With this architecture, we can linearly scale the cluster by adding more CH nodes. But to support multi-tenant reliably, we also need proper isolation between tenants for both ingestion and query. In the ingester, we impose rate limits on each tenant. In query service, we control the max number of in-flight queries from each tenant, and allocate the resources to each query conservatively, like query threads, to leave rooms for concurrent queries and ingestion load.
Cost and Performance
We reduced the hardware cost of the platform by more than half compared to the ELK stack, while serving the more production traffic. As to the operational overhead, we just need to run one single, unified log ingestion pipeline in each region, and have automated all common operations with the admin service. In addition, the platform is immune to type conflict errors, which used to be a major source of on-call workload when operating the old platform.
In terms of performance, the ingestion latency is capped under one minute. Our platform queries, retrieves, and aggregates logs across multiple regions, often under a few seconds, particularly when the query window is less than one day. And following queries (like from refreshing the dashboard) run much faster, because ClickHouse caches data in memory. With the proper support of resource isolation in ClickHouse, our platform continues to work under heavy query load without severe degradation or being choked up.
Transparent migration from ELK
There are about 10K Kibana dashboards saved by Uber engineers to analyze logs each month, in addition to many services calling ES endpoints directly to retrieve logs. So to facilitate migration without requiring user-side changes to their dashboards or code, we have built the QueryBridge service to translate the ES query into the new query interface, and vice versa for the response back. We add feature flags into the service to migrate users incrementally after verifying the query results.
We don’t aim to support the full ES query syntax, but only those found to be used in our production. Even so, the translation logic is still quite sophisticated. For example:
- Lucene queries can be embedded in ES query via query_string operator. We convert them into a subtree of the whole AST (abstract syntax tree) representing the whole ES query.
- Aggregation can have filtering conditions associated with it, like filter aggregation, and we translate it to Calculations with a specific filter in the query request.
- ES internal fields like @timestamp and _source have to be handled separately, because they are not data fields inside the log body.
- We have to translate filters for the keyword and text fields differently. For example, foo:”abc” expression is converted to equals(foo, “abc”) check if it is keyword type, but contains(foo, “abc”) check if it’s text type in the query request.
Future work
Logs convey high-resolution insight into the production environment, particularly when they are tagged with high-cardinality fields, like request ID, geo location or IP address. Being able to analyze those logs in near-real time proves very effective for debugging online systems and identifying interesting patterns to improve product quality. Based on the user experience so far, we believe this is an effective platform to fulfill the extensive log analytic needs at Uber. And ClickHouse is indeed a very powerful analytics engine, which we’d like to keep exploring.
Moving forward, we intend to follow up in these interesting areas:
- Support SQL queries in query service.
- Actively improve variance in query latency by using PreWhere and Where clauses adaptively, fine-tuning the index granularity, exploring the skipping indices, and fine-tuning query settings per more collected stats.
- Explore tiered storage to increase data retention and reduce cost.
- Build next-gen UI/UX to replace Kibana and better integrate with the backend to discover and analyze logs, and facilitate incident investigation by cross-checking logs, metrics and traces conveniently.
If you are interested in joining the Reliability Platform team at Uber and build the next-gen observability experiences, please apply to join our team!

Chao Wang
Chao is a software engineer at Uber. He worked in the observability area for the past 5 years and is currently leading the team building the next generation logging infrastructure.

Xiaobing Li
Xiaobing is a former software engineer in Uber’s Logging team. He led the projects around the new logging query service, focusing on migrating logging users from ELK transparently.
Posted by Chao Wang, Xiaobing Li
Related articles



How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Information for driving during the week of Super Bowl LVIII

Uber Reveals 2023 “Airport of the Year” Award Winners

DataCentral: Uber’s Big Data Observability and Chargeback Platform
How LedgerStore Supports Trillions of Indexes at Uber
Products
Company
