Jellyfish: Cost-Effective Data Tiering for Uber’s Largest Storage System
September 9, 2021 / Global
Problem
Uber deploys a few storage technologies to store business data based on their application model. One such technology is called Schemaless, which enables the modeling of related entries in one single row of multiple columns, as well as versioning per column.
Schemaless has been around for a couple of years, amassing Uber’s data. While Uber is consolidating all the use cases on Docstore, Schemaless is still the source of truth for different pre-existing customer pipelines. As such, Schemaless uses fast (but expensive) underlying storage technology to enable millisecond-order latency at high QPS. Furthermore, Schemaless deploys a number of replicas per region to ensure data durability and availability in the face of different failure models.
Accumulating more data while using expensive storage, Schemaless has increasingly become a key concern for cost and thus required attention. To this end, we carried out measurements for understanding data access patterns. We found that data is frequently accessed for a period of time, after which it is accessed less frequently. The exact period varies from one use case to another, however, old data must still be readily available upon request.
Requirements
To sketch the right solution for the problem, we set out 4 main requirements:
Backward Compatibility
Schemaless has been around for so long that it is integral to many of Uber’s services and even the hierarchy of services. Consequently, changing the behaviour of existing APIs or introducing a new set of APIs were not options, since they would require a chain of changes across Uber product services, delaying landing efficiency. This pinned the unwavering requirement of backward compatibility—customers should not need to change their code a single bit, while still being able to enjoy whatever efficiency that we can achieve.
Latency
Low latency is essential for getting data in a timely manner, so we collaborated with our customer teams to investigate different use cases. Studies showed that P99 latency on the order of hundreds of milliseconds is acceptable for use cases with old data, while latency for recent data must still remain within a few tens of milliseconds.
Efficiency
Any change to the implementation of existing APIs should remain as efficient as possible not only to keep latency low, but also to prevent overuse of resources, such as CPU and memory. This will require optimization to reduce read/write amplification, as we shall show later on.
Configurability
As mentioned earlier, Schemaless has many use cases across Uber, which differ in access pattern and latency tolerance, among other variables. This necessitates our solution to be parameterizable in key places, so it can be configured and tuned for the different use cases.
Solution
The key idea for the solution is treating data based on their access patterns, so we have a commensurate ROI. That is, frequently accessed data can incur relatively high costs, whereas infrequently accessed data must incur lower costs. This is exactly what data tiering achieves – similar to the concept of Memory Hierarchy. However, we needed a way to keep backward compatibility to ensure no changes for our customers. This required us having the data within the same tier as complex operations, which would prove challenging for cross-tier coordination.
We looked into ways to reduce the footprint for old data. We experimented with batching data cells (e.g., a trip) and applying different compression methods on the application level so we could tune compressibility based on the application’s expected performance. This also resulted in less read/write amplification for backfill jobs, which we will discuss later. We explored different compression methods with different configurations for different use cases. We found that the ZSTD compression algorithm can obtain up to 40% overall saving when we batch and compress a number of cells together.
At this point, we realized that we can tier the data internally in the same tier, while still reducing the footprint due to old data, thanks to compression and batching. This will allow us to keep the latency within the required few hundreds of milliseconds. Since the batch size and ZSTD are configurable, we could tune our solution for the different use cases that are currently served by Schemaless. With a proper implementation, we could nail the efficiency requirement too, hitting all the 4 requirements discussed above.
We called the project Jellyfish after the ocean’s most efficient swimmer, which spends less energy for its mass to travel a given distance than any other aquatic animal, including the powerful salmon.
Proof of Concept
Now that the solution was sketched, we needed to quickly evaluate its merit. For that, we carried out a set of experiments and mocked up a quick proof of concept. The goal was to evaluate the overall footprint savings.
Jellyfish uses 2 main parameters to control its overall savings, as well as the impact on CPU utilization:
- Batch size: controls the number of rows to batch together
- Compression level: controls speed vs. ZSTD compression
Using measurements from the proof of concept, we settled on a batch size of 100 rows, and a ZSTD level of 7, which should be light on CPU.
Together, this combination results in an overall compression ratio around 40%, highlighted in the figure below. The figure also shows other configurations we tried that showed either diminishing returns or lower savings.
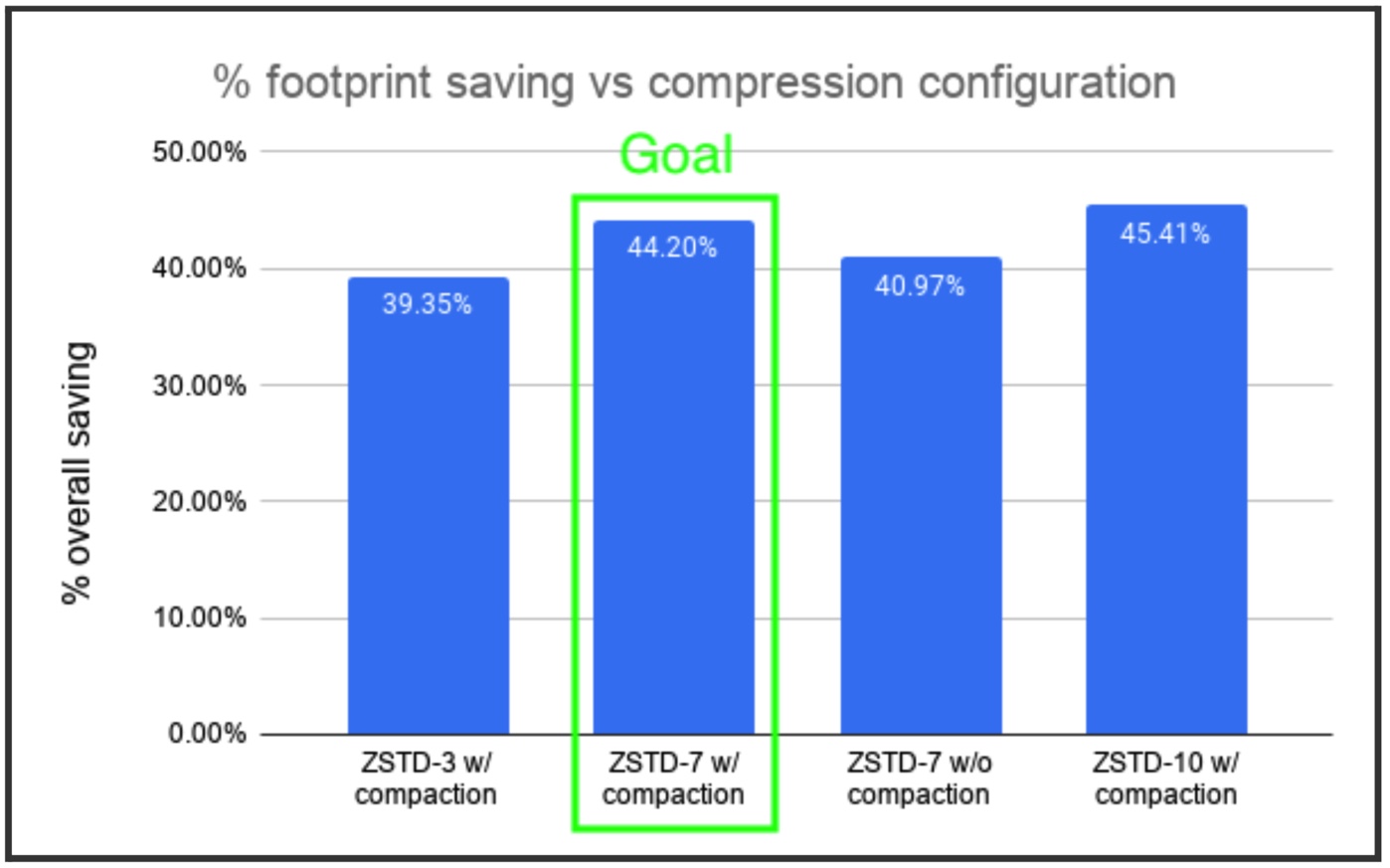
One key metric we have yet to observe at scale is the latency for “batch” requests. We tracked that early on in our implementation with some stress testing, and could confirm that we are within the required latency SLA, hundreds of milliseconds.
Architecture
Although we considered several alternatives, we will only discuss the final design here. The overall architecture is shown in the figure below. There are batch and real-time backends. The batch backend hosts old data after migration from the real-time backend. The real-time backend is exactly the same as the old backend, but is only used to store recent data. That is, new data is always written into the real-time backend, much like before. Data is then migrated out once it becomes cold after some period of time.
The figure below shows a high-level view of the new architecture of the frontend (Query Layer) and backend (Storage Engine) components after implementing Jellyfish. For brevity, we will mainly focus on the new parts, shown in green. At the core of the architecture are 2 tables: (1) the standard “realtime” table and (2) the new batch table. Customer data is written initially into the real-time table as it has been. After some amount of time (configurable per use case), data is moved to the batch table after being batched and compressed. Batching is done by cell, which is the basic unit of Schemaless.
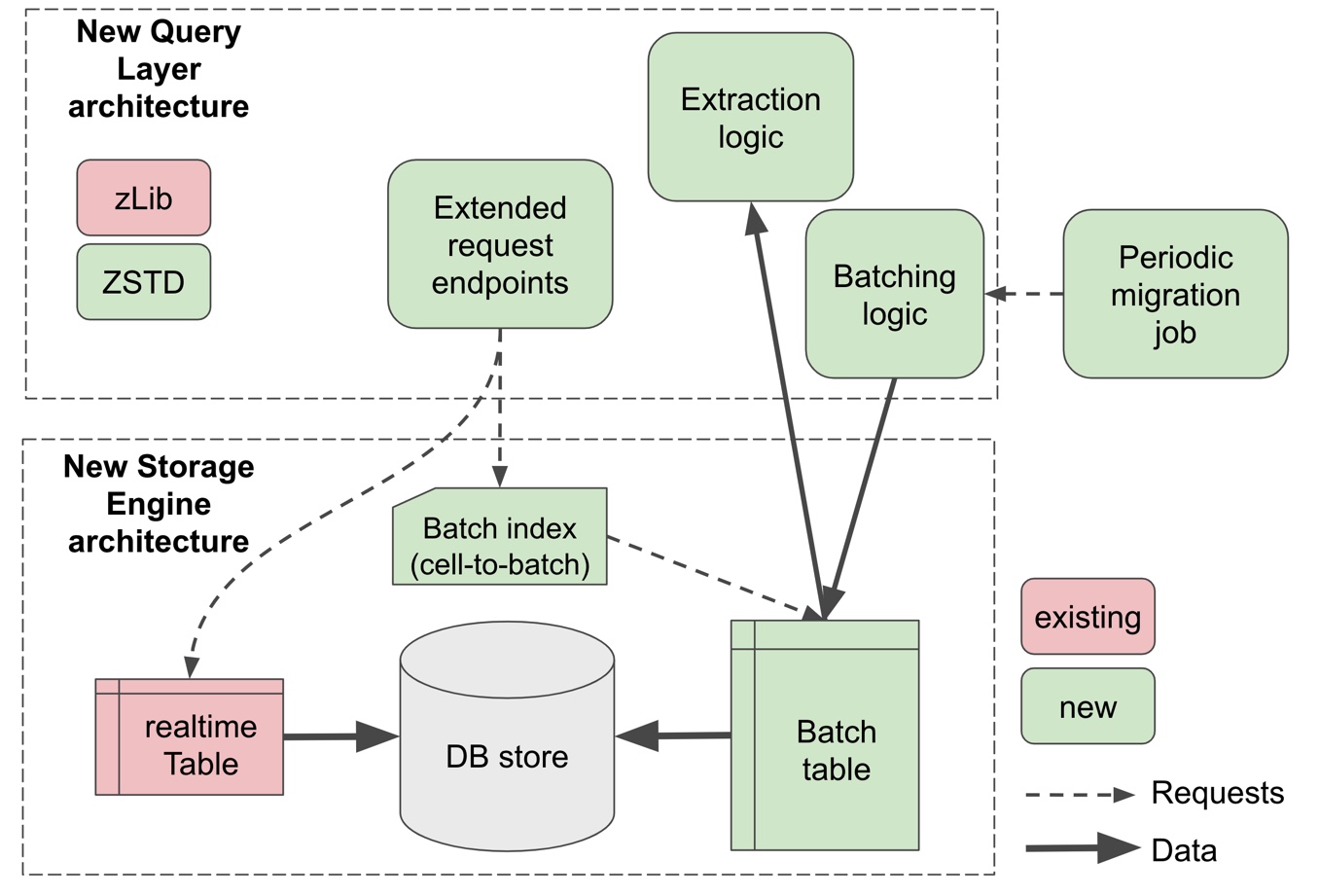
As the figure shows, Schemaless uses a batch index, which maps from a cell UUID to the corresponding batch UUID (UUID to BID). During reads of old data, the batch index is used to quickly retrieve the right batch, decompress, and index into it to extract the requested cell.
Request Flow
The new architecture has consequences for the flow of user requests, which we will illustrate for reads and writes.
Reads
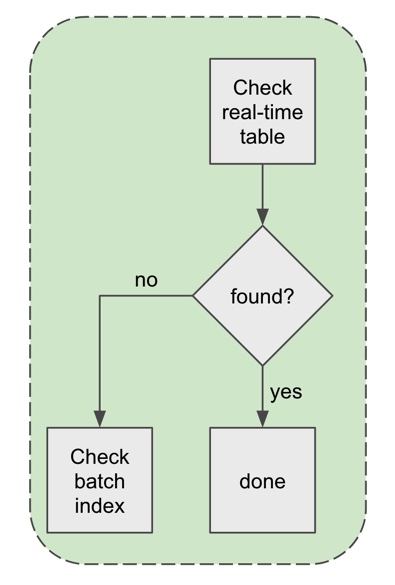
Reads for single cells proceed as usual to the real-time table, since the majority of requests (> 90%) are for recent data. If successful, requests terminate after that. If not, requests spill over to the batch index to identify the batch table and fetch it in the same query. The figure below shows the flow.
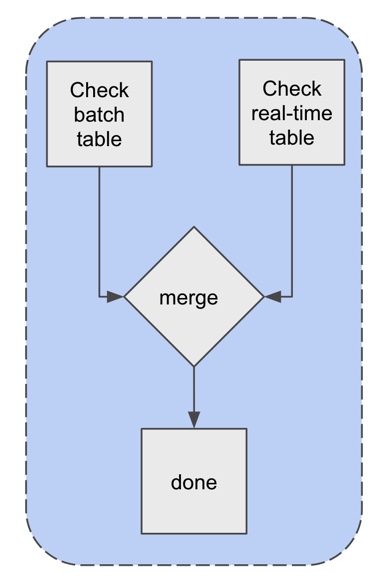
 There is another type of read which requests a full row (a number of cells that make up a logical business entity, such as a trip). Such requests can have data straddled across the boundary of real-time and batch tables. For such requests we call both backends and merge the results based on some order defined by the user, shown in the figure below.
There is another type of read which requests a full row (a number of cells that make up a logical business entity, such as a trip). Such requests can have data straddled across the boundary of real-time and batch tables. For such requests we call both backends and merge the results based on some order defined by the user, shown in the figure below.
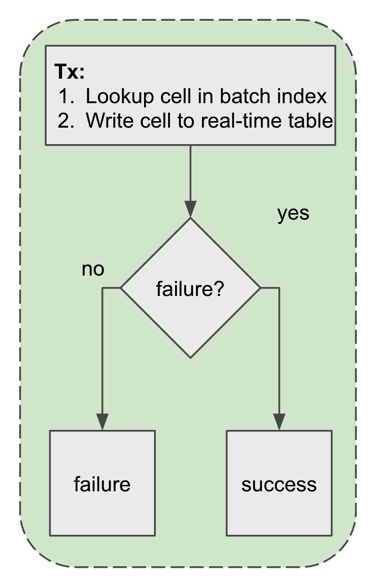
Writes
With data partitioned across 2 tables, the uniqueness of the primary key is no longer maintained. To counter, we needed to extend write queries to check data existence in the batch index as part of the same transaction. We found that lookups in the batch index are fast, thanks to its small size. The figure below shows the new flow for the write path.
Rollout
Because Schemaless has been mission critical to Uber, the rollout of Jellyfish needed to be absolutely immaculate. To this end, it was done through multiple validation stages, ending with a phased rollout to actual production instances. Validation was performed for all new and adapted endpoints to ensure correct functional behavior, but also to cover corner cases. Furthermore, we tested the non-functional aspects of the endpoints with micro-benchmarking in order to measure their new timing performance. Macro benchmarks were applied against Jellyfish-enabled test instances to characterize their performance under a mix of workloads. Stress testing was applied too for finding the relationship between throughput and latency. We could confirm that the latency SLA of a few hundred milliseconds is attainable under Jellyfish.
With Jellyfish ready, we set out to roll it out to production systems. Uber’s trip storage system, Mezzanine, has a particularly large footprint. We discuss the phased rollout of Jellyfish.
Phases
The rollout to production instances went through a number of phases, shown in the figure below. The following discussion outlines the rollout across a single shard we used. We rolled out gradually across shards and regions.
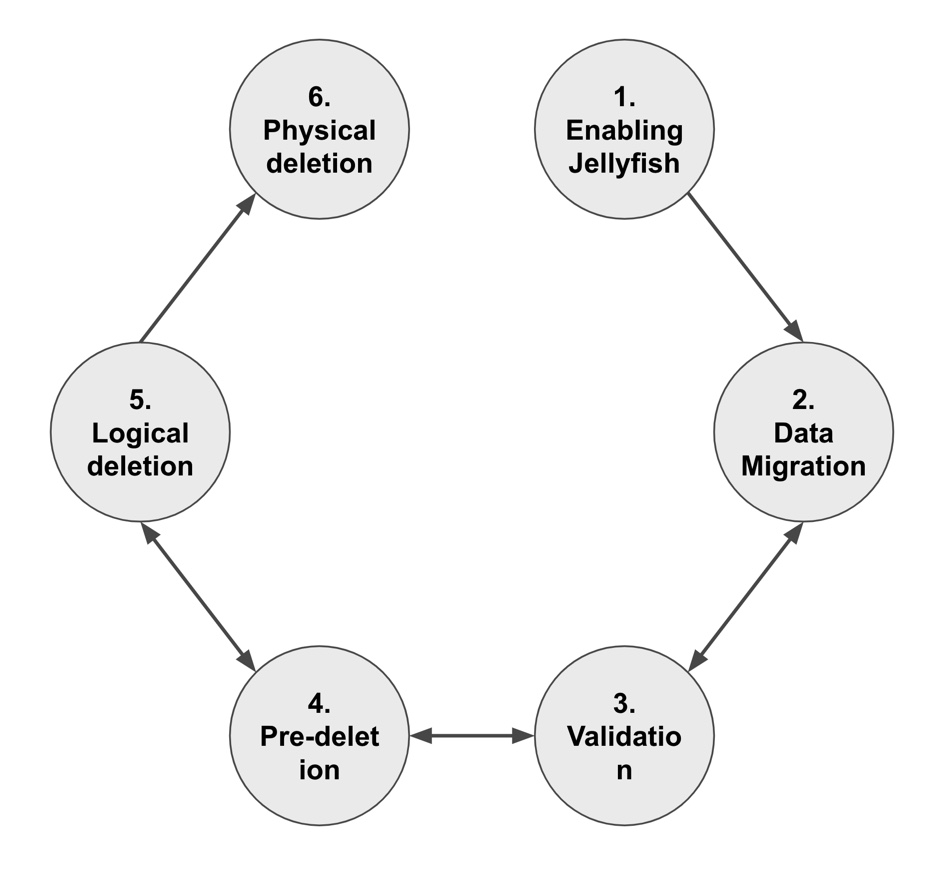
- Enabling Jellyfish configures Jellyfish and the migration range for the instance, and enables the creation of the batch backend.
- Migration reads old data from the real-time backend and copies it into the batch backend. It is the most time- and resource-intensive stage, and scales with the volume of data to be migrated.
- Consistency validation shadows traffic going to the real-time table in order to validate data in the batch backend. It calculates a digest for the requested old data and compares it to the data coming from Jellyfish. We report 2 types of consistency: content and count. For a successful migration, both must be zero.
- Pre-deletion is effectively reverse shadowing and is only enabled if consistency is 100%. Traffic to old data is served effectively from Jellyfish, while we still compute digests from the real-time backend and compare against them.
- Logical deletion switches out the read path from the real-time backend only for old data, so no digest calculation is performed for select shards. This stage exactly emulates old data disappearing from the real-time backend. It helps with testing the tiering logic and the new data flow once data is deleted for real.
- Physical deletion actually deletes data after confirming that logical deletion was successful, since this phase is irreversible, unlike the previous phases. Additionally, deletion was staggered for different replicas to ensure data availability and business continuity in the face of unexpected runtime issues.
Challenges
Changes to any live production system come with challenges. To ensure data safety and availability at all times, we proceeded with the phased approach cautiously. We made sure to allow enough time for our customers to monitor and test when moving from one phase to the next.
One challenge we faced was high load due to a particular service that was mainly scouring old data to recompute summaries. The high load resulted in unaccepted latencies, so we worked with the customer as they were deprecating that pipeline. Another more serious challenge was users getting incomplete data for old rows whose cells were recently updated. We needed to roll out a fix where results for such rows are merged from both real-time and batch before returning them to the user. A third challenge was around coordinating the migration work with other data-intensive tasks, like rebuilding user-defined indexes and backfill jobs.
The takeaway here is that there will always be challenges in production that will affect not only the timeline of the project, but also the applicability of the solution. Careful diagnosis and close collaboration with customers are absolutely necessary to overcome these challenges.
Optimizations
Throughout the implementation of the Jellyfish project we leaned towards optimizing latency or throughput for those parts where Jellyfish was clearly changing the data access model. Some of those optimizations include:
- Decode requested cell: When the user requests a cell, a whole batch is fetched at once. We decode the JSON part of the requested cell only, in order to avoid decoding for the other 99 cells.
- Delete metadata only: When deleting cells in place (due to TTL and the like), we only remove the entry of the cell from the batch index, so the user is not able to access it. The actual removal of the cell is done by a background job, which carries a read-modify-write operation to update the batch cell. We store information from the deleted cell in a journal table for the background job to consume. This way we prevent running this expensive operation in the foreground so that the online read/write path is not affected and the user-perceived latency is reduced.
- Collate updates by batch: When updating cells in place, a batch cell can be touched a few times. With read-modify-write, updates can be both resource- and time-consuming. By grouping updates per batch, we were able to reduce total update time for a job by 4x.
Reaping Efficiency
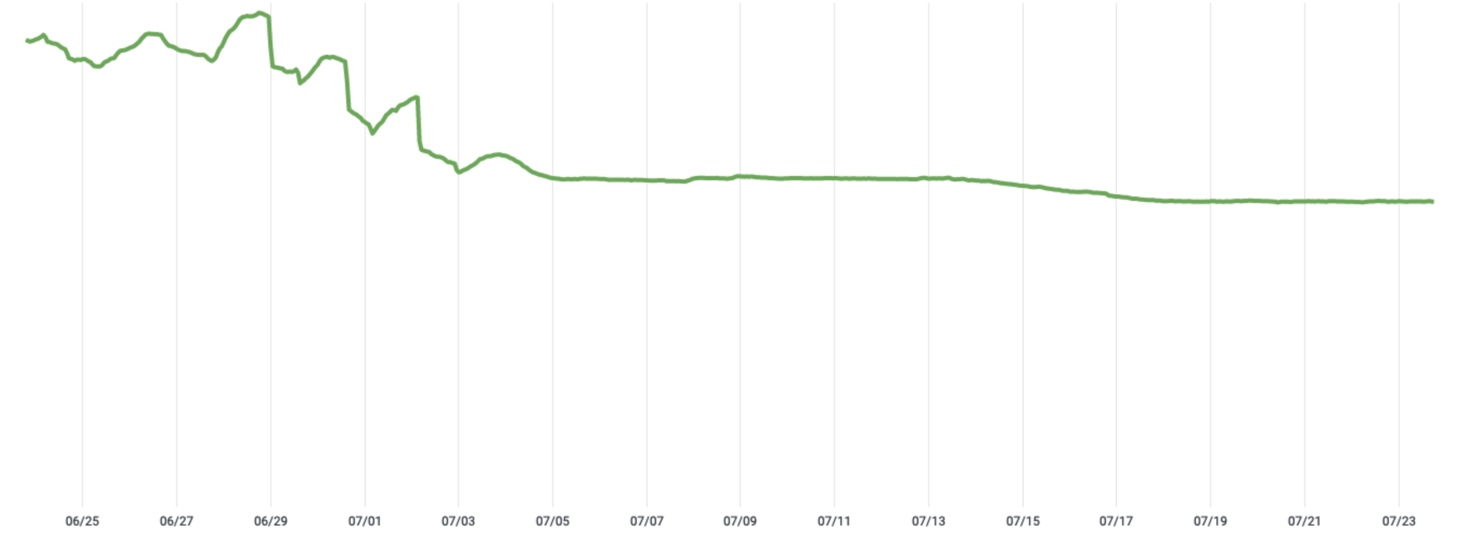
Once Jellyfish was fully rolled out and confirmed to meet our requirements, we were ready to reap the benefits. To this end, we started deleting data from the old backend in a phased way. The figure below shows the actual footprint decreasing over a period of a few days when deletion was taking place. Jellyfish realized an actual reduction of 33% of storage space in this specific case.
Future Work
The Jellyfish project has been successful in reducing the operating expenses for Uber and unlocking more savings in the future. The tiering concept presented here can be extended in several ways to attain more efficiency and reduce cost further. Some directions that we are thinking of taking Jellyfish into are applying it to Docstore, explicit tiering, and using physically distinct tiers. Part of achieving this is exposing a new set of APIs to the user to access old data, and optimizing both the software and hardware stacks for distinct tiers. Uber is looking for talented engineers to join such efforts.

Mohammed Khatib
Mohammed G Khatib is a Staff Software Engineer on Uber’s Core Storage team. He has been working in the area of storage systems and distributed systems for the past 10 years. His work focuses on improving availability, scalability, efficiency, and performance. He has worked in the areas of pub-sub system, efficiency, power capping, and non-volatile memory. Mohammed holds a PhD in Computer Science and has co-authored over 15 peer-reviewed technical articles. He is also a named inventor on 5 US patents.
Posted by Mohammed Khatib
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
