Introducing uGroup: Uber’s Consumer Management Framework
October 21, 2021 / Global
Background
Apache Kafka® is widely used across Uber’s multiple business lines. Take the example of an Uber ride: When a user opens up the Uber app, demand and supply data are aggregated in Kafka queues to serve fare calculations. When a ride request is accepted by a driver, push notifications in Kafka queue are sent to mobile devices. After a ride is finished, post-trip processing, including payment and receipt sending, leverages Kafka. During the entire operation, the data and messages flowing between services are also ingested into Apache Hive™ for data analytic purposes. In a word, Apache Kafka is a critical service that empowers Uber’s business.
Given its high popularity, we are operating large scale Kafka clusters across multiple regions. We started our Kafka journey in early 2015 with a few-node Kafka cluster in one region. With the tremendous growth of Uber’s business and expansion of Kafka usages, we ran into scaling and operational issues, and got many interesting user requests from customers.
One of the most common issues we have run into is how to efficiently monitor the state of a large number of consumers. Having evaluated many open source solutions, with the large scale and unique setup, we finally decided to build a new observability framework for monitoring the state of Kafka consumers. Today, we are delighted to introduce uGroup, our internal Kafka consumer monitoring service.
Challenges
At Uber’s scale, improving Kafka consumer observability can greatly simplify the process of problem detection, debugging, and outage mitigation. As the majority of consumers use consumer groups to coordinate, it’s a natural thought to achieve the goal by improving consumer group observability.
Initially, we relied on consumer-side metrics to improve observability.
- If users are using Uber’s in-house Kafka consumer libraries, we provide built-in metric reporting mechanisms
- If users are using open source Kafka consumer libraries, they need to build customized mechanisms for metric reporting
- If users are using the Kafka event processing framework (for example, Apache Flink®), the framework owners will provide metric reporting mechanisms
Although the current consumer-side monitoring solution works, it suffers from the following problems:
- It is impossible to get the consumer-side metric report 100% correct, since the consumer side does not have visibility to all the consumer group activities, especially when consumers are having problems. For example, if a consumer has issues talking to Kafka servers, metrics reported by this consumer might be totally wrong.
- Library, platform, or even service owners need to do duplicate work to provide metrics reporting mechanisms that work for them. Whenever there is a new consumer library or a new message processing framework, developers need to re-design and re-implement the consumer group monitoring mechanism to fit it.
- It is not convenient to use. Kafka users need to update their consumer group (monitoring) dashboards/alerts when migrating from one library/framework to another. In order to monitor all consumer groups, the Kafka team needs to be aware of all consumer library/framework use cases.
- Metric reporting mechanisms are not standardized, making it hard for the Kafka team to understand or troubleshoot user problems.
History of Development
In the early versions of Kafka, consumer group activity records were stored as Apache Zookeeper™ nodes; since version 0.9 they have been stored as a Kafka internal topic named __consumer_offsets. This design improves the scalability and safety of Zookeepers.
Each message inside the __consumer_offsets topic stores one operation of one consumer group, for example: creation of a consumer group, one consumer joins a consumer group, and, most importantly, a consumer instance of a consumer group commits offsets. To summarize, this Kafka topic is basically the change logs of consumer group objects. When a Kafka broker starts, it will read through the entire history of __consumer_offsets topic, replay the updates, and then have the correct state of all consumer groups.
Over time, we have run into the need that whenever a consumer group commits offset, a special action needs to be triggered. After some investigation we decided that it would be very reliable and simple to decode the Kafka internal topic __consumer_offsets and get all consumer group activity records. We started a project to implement this idea, which developed into this uGroup service. By leveraging this idea, uGroup can solve the above challenges in a standard, easy, accurate, and scalable way.
High-Level Architecture Overview
As shown in the following figure, the uGroup service consists of many deployments, each for a single cluster or for a set of related clusters.
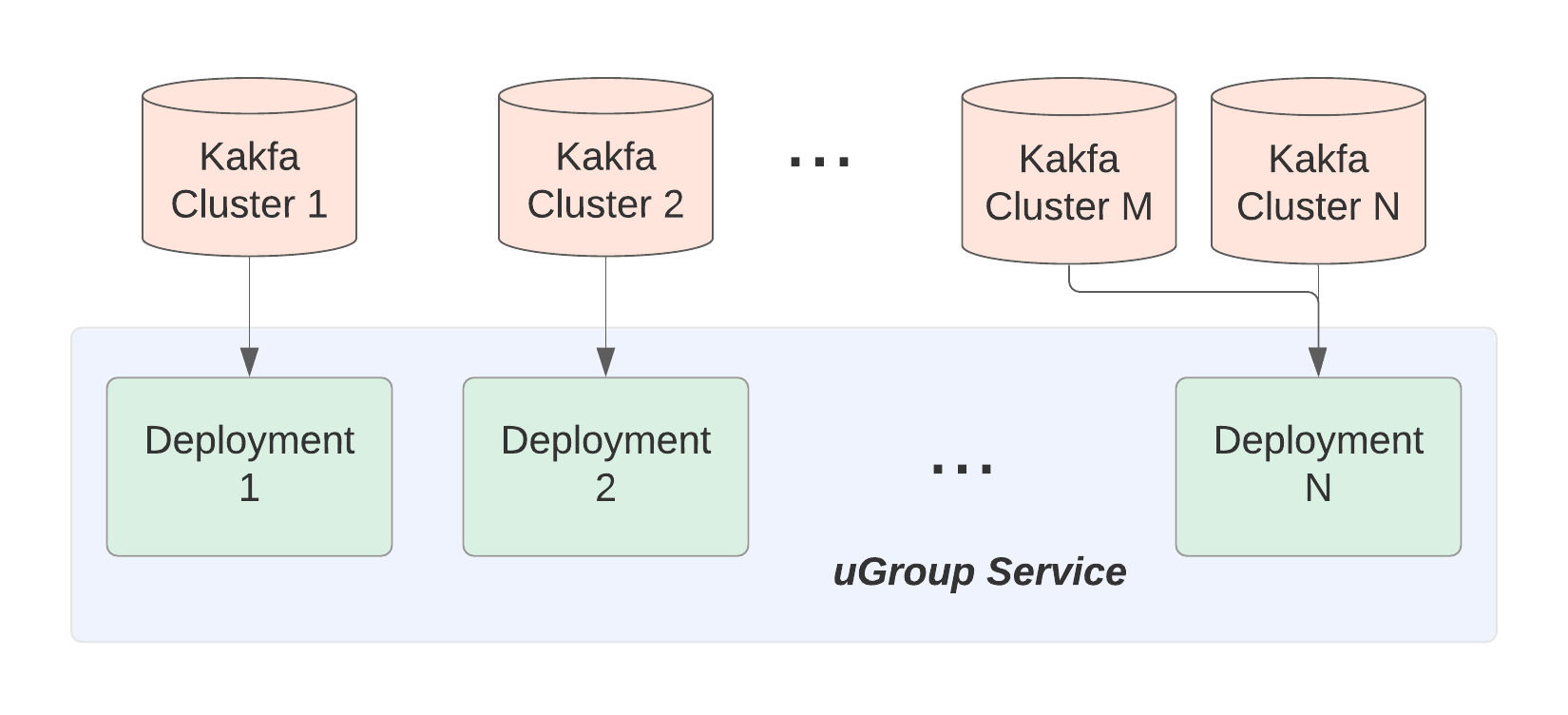
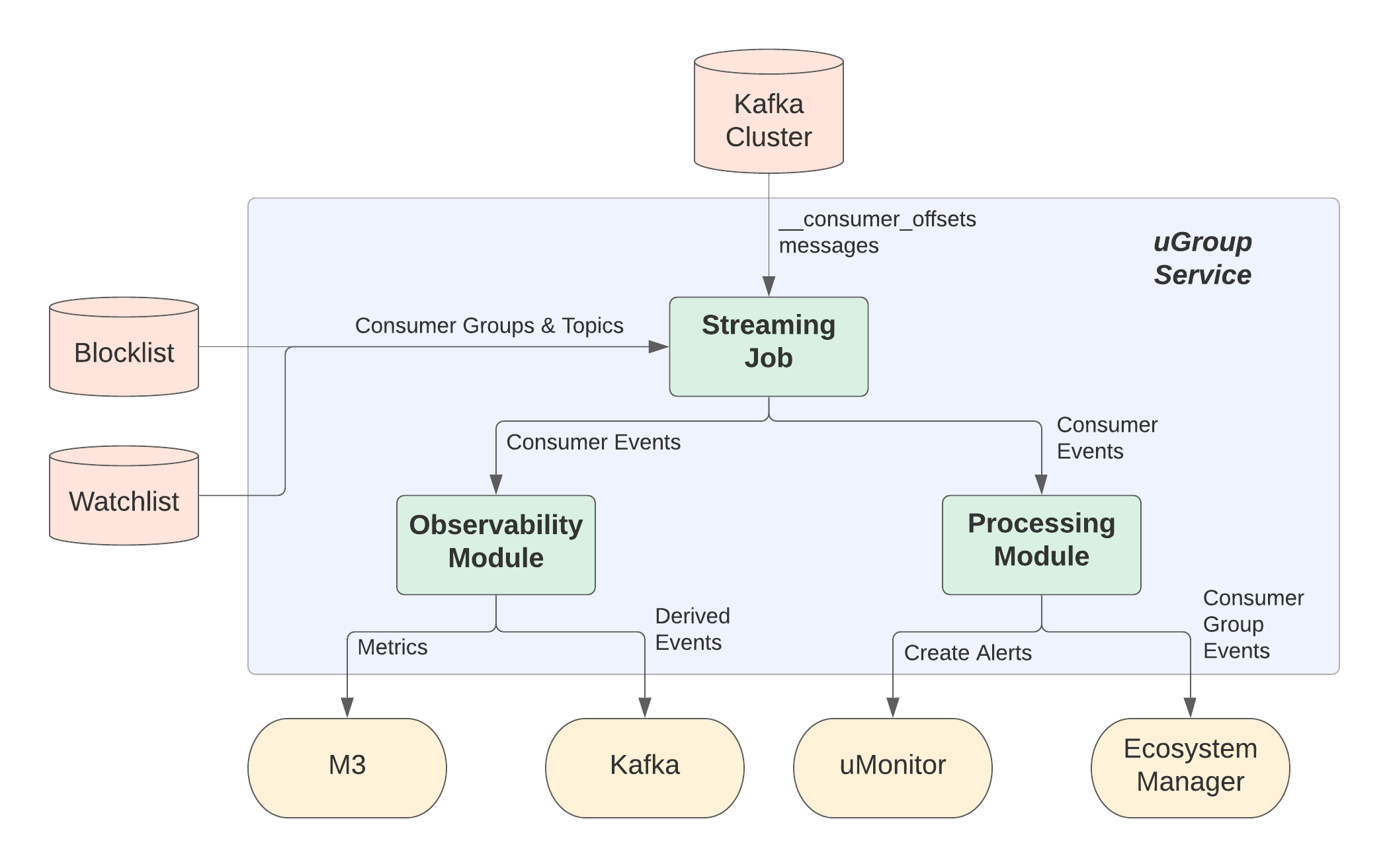
From a very high level, a single uGroup service deployment consists of 3 major modules:
- A streaming job that reads and processes messages from the __consumer_offset topic, it outputs consumer group events
- An observability module that reads the output of the streaming job and report statistics
- A processing module that reads the output of the streaming job and invokes other services to take actions
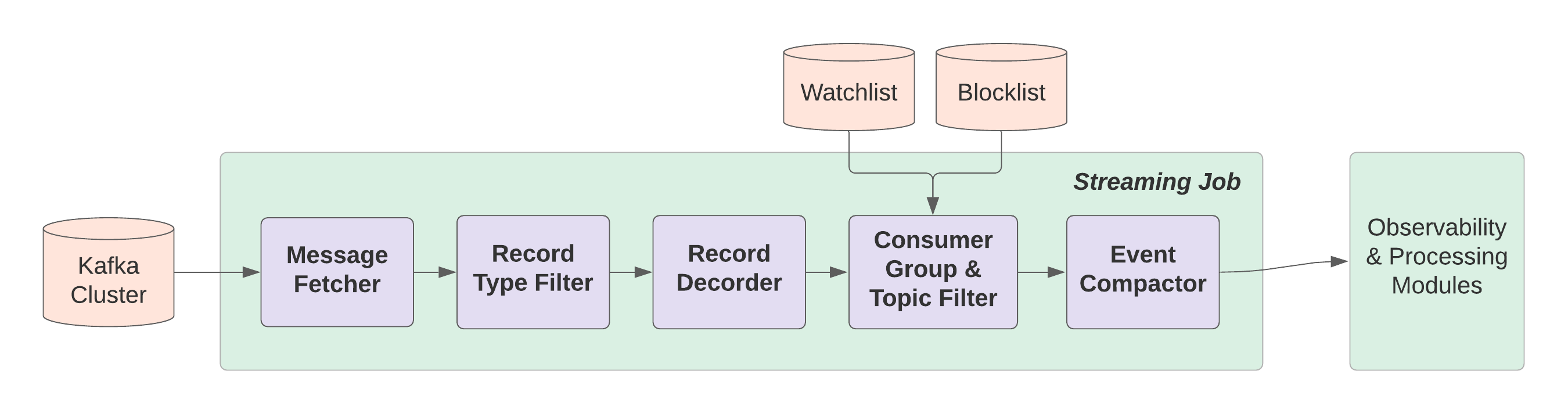
Streaming Job
The streaming job comprises a chain of components, shown in the following figure:
- A fetcher to read all messages from the __consumer_offsets topic
- A message filter to filter out types of records that we don’t care about
- A decoder to decode consumer group activities
- A consumer group & topic filter to read watchlists or blocklists from a datastore, and filter out consumer groups and topics that we don’t want to process
- A compactor that compacts events by time intervals, which can greatly reduce the workload of the observability and processing modules.
Observability Module
The observability module is a generic framework, and so new (consumer group) event processors can be easily created and plugged in. Currently, it has 2 processors:
- A metric emission processor that analyzes events and reports:
- Stuck partitions for each (consumer group, topic) tuple
- Consumer lag for each (consumer group, topic, partition) tuple
- Number of active consumer groups for each topic
- A Kafka producer that produces event summaries to Kafka
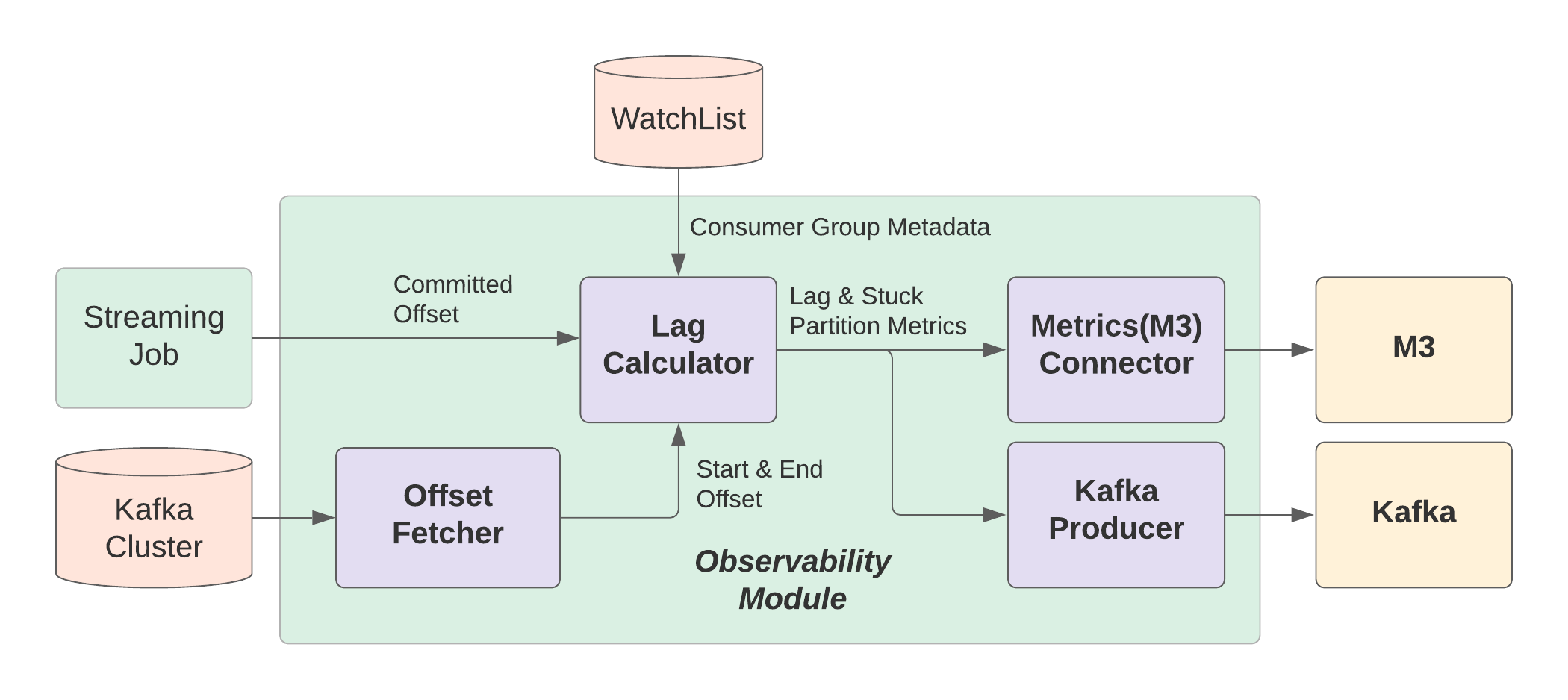
This observability module also reads watchlists dynamically from a datastore and statically from a file, to include the metadata in the reported metrics.
To support the feature of watchlist, the observability module also includes a fetcher, which wraps the Kafka admin client. This fetcher not only provides the start/end offsets required in lag calculations. It can also fetch the committed offsets, without the updates in __consumer_offsets. This is needed because for consumers that are not active all times, or are accidentally offline, their up-to-date states can only be observed via active queries to the Kafka brokers.
Processing Module
Similar to the observability module, the processing module is also a generic framework that supports plug-in consumer group event processors. Currently, it has 2 optional processors:
- A processor that creates alerts for consumer owners of increased lag or stuck partitions. Although users can set up alerts with the metrics emitted in the observability module, a predefined alert will ease the onboarding flow and ensure an extra layer of reliability.
- A processor that writes committed offsets to Kafka Offset Sync service, which supports the All-Active use case in our multi-region Kafka deployment
- A processor that writes consumer group consumption history to the Kafka Ecosystem Manager, so that users can query it to get information like “which consumer groups read my topics.”
uGroup Use Cases at Uber
Kafka Consumer Observability Improvement
The uGroup service is designed for improving Kafka consumer observeabiltty. It can help in the following aspects:
High E2E Latency Detection
Many Kafka use cases at Uber are time-sensitive, i.e., they cannot tolerate too-large E2E (the time between when a message is produced and consumed) latency. E2E latency might get high when:
- There are high-consumption lags
- Some partitions get stuck.
Users should be alerted when either case happens—those alerts can be set up using lag and stuck partition metrics emitted by the uGroup service.
Abnormal Consumer Behaviors Detection
Certain abnormal consumer behaviors might greatly hurt performance of Kafka clusters, such as:
- High-offset commit frequency
- Many randomly created consumer groups
- Many consumer groups having high lags
In some extreme cases, those behaviors might even bring down Kafka clusters.
Kafka system operators should be alerted when those cases happen—those alerts can be set up using consumer group commit count, consumer group count, and lag/stuck partition metrics emitted by the uGroup service.
Unstable Consumer Detection
Sometimes, even when Kafka consumers work normally, there might still be a hidden problem—the consumer group is rebalancing all the time. This might turn into real problems (e.g., high E2E latency, data loss) over time.
The uGroup service analyzes and emits metrics about consumer group activities, which can help both Kafka users and Kafka system operators to detect such problems.
Offset Management for Solving the Cluster Fault Tolerance Problems
Providing business resilience and continuity is a top priority for Uber. Another important use case of the uGroup service is to overcome the challenge of recovering from disasters (e.g., Kafka clusters’ downtime in one data center with the active-passive setup) by failing over the Kafka traffic to another cluster.
A typical challenge to Kafka’s active-passive solution is to manage the consumer’s consumption progress after failover, either to another cluster in the same data center or a different region. Because many services at Uber cannot tolerate any data loss, the consumer cannot resume from the high watermark (i.e., the latest messages). Meanwhile, to avoid too much backlog, nor should the consumer consume from the low watermark (i.e., the earliest messages). To solve this problem, we built a consumer offset sync service leveraging uGroup service output to continuously synchronize the consumer’s offsets from one cluster to another. In particular, the compaction feature in uGroup provides the control of synchronization frequency, to strike a balance between the number of offset updates on the destination and the number of messages to replay after failover.
Comparison with Other Open-Source Solutions
The major question we get from developing our own solution comes to a comparison with Burrow. Based on our investigation and reading through the well-written source code of Burrow, here are some of our great advantages:
- Easier to keep up with future Kafka versions and guaranteed compatibility
One major advantage that Burrow will not easily match is the convenience of binary compatibility. Decoding the serialized format correctly by understanding the binary format is not an easy task. Burrow did a great job by hundreds of lines of code. In contrast, since we are using Java and Kafka binary jars directly, those hundreds of lines can be accomplished by just one line in Java. Some may say it is not that complicated, but think about the following 2 scenarios:
- In the future when Kafka updates the binary format and provides more information that we need, it will be painful to add new code to decode binary in Burrow; meanwhile, there are lots of tests that need to be done. In our solution we get that upgrade for free, thanks to the high-quality code of Kafka binaries and the thorough testing that the Confluent team has done.
- __consumer_offsets has much more information than offset commits, and we should be able to provide visibility to it easily. For example, when a consumer joins a consumer group, rebalancing happens. We can find a special type of binary format/type of records in __consumer_offsets for each joining and leaving event. In our solution it is just a few simple lines of code to decode, while in Burrow it will be a workload comparable to that hundred lines of code to read that information.
2. Popular Java language binding
This project is written in Java, while Burrow is written in Golang. For the Kafka community, Java language binding is still more convenient and more popular. Our project can reach a far broader user base and attract admins to contribute to the project.
3. Flexible event processing framework with a multi-purpose design
This project was implemented with an event processing framework concept; it can be easily repurposed into a dedicated, specialized streaming job for consumer group related tasks. For example, in our production system, we have reconfigured the project quickly and started a consumer group offset sync/modification job quickly. Our project can be much more than a consumer group monitor. On the other hand, Burrow was designed as a “monitoring companion for Kafka.” It is neither flexible nor lean as an event processing framework.
Our project’s major disadvantage is that it does not have some features for admins (e.g., HTTP Query Endpoints, Slack Bot notifications, etc.). This is actually more a reason to open source it: users can contribute to developing such features in the future if there is a need.
4. Easy to track non-active consumers
By including proactive fetching in the compacting algorithm, uGroup is able to report metrics for non-active consumers. If a consumer is not active, no consumer update will be emitted by the broker to the topic __consumer_offsets, thus no metrics will be reported if we only rely on the events in this topic. However, since this will add extra overhead to the broker, uGroup will only do so if the state of the consumer is expired. It also requires the consumer group + topic pair being registered in the watchlist to activate this feature.
Future Work
We hope the open source community can help enrich the features of the consumer group monitoring service. For instance, reading and interpreting other consumer group activity records (except for consumer group commit activity records) of __consumer_offsets can be added to detect incorrectly configured consumer groups that are wasting lots of time rebalancing. Admin features and UI can also be added for easy interaction with the service (e.g., add consumer groups to a watchlist). Those features can potentially greatly improve the user experience of the service.
Apache®, Apache Kafka®, Apache Hive™, Apache Zookeeper™, Kafka®, Hive™, and Zookeeper™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.

Qichao Chu
Qichao Chu is a Senior Software Engineer on Uber’s Streaming Data Team. He has been working on highly available, fault resilient streaming systems, including Kafka Consumer Proxy and Uber internal Kafka client libraries.

Yupeng Fu
Yupeng Fu is a Principal Software Engineer on Uber’s Data team. He leads several streaming teams building scalable, reliable, and performant streaming solutions. Yupeng is an Apache Pinot committer.

Mingmin Chen
Mingmin Chen is a Director of Engineering and head of the Data Infrastructure Engineering team at Uber. He has been leading the team to build and operate Hadoop data lake to power multiple Exabytes of data in storage, Kafka infrastructure to power tens of trillions messages per day, and compute infrastructure to power hundreds of thousands compute jobs per day. His team builds highly scalable, highly reliable yet efficient data infrastructure with innovative ideas while leveraging many open-source technologies such as Hadoop (HDFS/YARN), Hudi, Kafka, Spark, Flink, Zookeeper etc.

Haitao Zhang
Haitao Zhang is a former Software Engineer on Uber’s Streaming Data Team. He has worked on projects and tools to improve the user experience of Kafka as a reliable and scalable async message queue, as well as improve monitoring and alerting of Kafka ecosystem.

Xiaoman Dong
Xiaoman Dong is a former Senior Software Engineer on Uber’s Streaming Data Team. He has worked on projects to provide improved monitoring and alerting of the Kafka ecosystem.
Posted by Qichao Chu, Yupeng Fu, Mingmin Chen, Haitao Zhang, Xiaoman Dong
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
