
Over the last decade, deep learning models have proven highly effective at performing a wide variety of machine learning tasks in vision, speech, and language. At Uber we are using these models for a variety of tasks, including customer support, object detection, improving maps, streamlining chat communications, forecasting, and preventing fraud.
Many open source libraries, including TensorFlow, PyTorch, CNTK, MXNET, and Chainer, among others, have implemented the building blocks needed to build such models, allowing for faster and less error-prone development. This, in turn, has propelled the adoption of such models both by the machine learning research community and by industry practitioners, resulting in fast progress in both architecture design and industrial solutions.
At Uber AI, we decided to avoid reinventing the wheel and to develop packages built on top of the strong foundations open source libraries provide. To this end, in 2017 we released Pyro, a deep probabilistic programming language built on PyTorch, and continued to improve it with the help of the open source community. Another major open source AI tool created by Uber is Horovod, a framework hosted by the LF Deep Learning Foundation that allows distributed training of deep learning models over multiple GPUs and several machines.
Extending our commitment to making deep learning more accessible, we are releasing Ludwig, an open source, deep learning toolbox built on top of TensorFlow that allows users to train and test deep learning models without writing code.
Ludwig is unique in its ability to help make deep learning easier to understand for non-experts and enable faster model improvement iteration cycles for experienced machine learning developers and researchers alike. By using Ludwig, experts and researchers can simplify the prototyping process and streamline data processing so that they can focus on developing deep learning architectures rather than data wrangling.
We have been developing Ludwig internally at Uber over the past two years to streamline and simplify the use of deep learning models in applied projects, as they usually require comparisons among different architectures and fast iteration. We have witnessed its value to several of Uber’s own projects, including our Customer Obsession Ticket Assistant (COTA), information extraction from driver licenses, identification of points of interest during conversations between driver-partners and riders, food delivery time prediction, and much more. For this reason we decided to release it as open source, as we believe there is no other solution currently available with the same ease of use and flexibility.
We originally designed Ludwig as a generic tool for simplifying the model development and comparison process when dealing with new applied machine learning problems. In order to do so, we drew inspiration from other machine learning software: from Weka and MLlib, the idea of working directly with raw data and providing a certain number of pre-built models; from Caffe, the declarative nature of the definition file; and from scikit-learn, its simple programmatic API. This mix of influences makes it a pretty different tool from the usual deep learning libraries that provide tensor algebra primitives and few other utilities to code models, while at the same time making it more general than other specialized libraries like PyText, StanfordNLP, AllenNLP, and OpenCV.
Ludwig provides a set of model architectures that can be combined together to create an end-to-end model for a given use case. As an analogy, if deep learning libraries provide the building blocks to make your building, Ludwig provides the buildings to make your city, and you can chose among the available buildings or add your own building to the set of available ones.
The core design principles we baked into the toolbox are:
- No coding required: no coding skills are required to train a model and use it for obtaining predictions.
- Generality: a new data type-based approach to deep learning model design that makes the tool usable across many different use cases.
- Flexibility: experienced users have extensive control over model building and training, while newcomers will find it easy to use.
- Extensibility: easy to add new model architecture and new feature data types.
- Understandability: deep learning model internals are often considered black boxes, but we provide standard visualizations to understand their performance and compare their predictions.
Ludwig allows its users to train a deep learning model by providing just a tabular file (like CSV) containing the data and a YAML configuration file that specifies which columns of the tabular file are input features and which are output target variables. The simplicity of the configuration file enables faster prototyping, potentially reducing hours of coding down to a few minutes. If more than one output target variable is specified, Ludwig will perform multi-task learning, learning to predict all the outputs simultaneously, a task that usually requires custom code.
The model definition can contain additional information, in particular preprocessing information for each feature in the dataset, which encoder or decoder to use for each feature, architectural parameters for each encoder and decoder, and training parameters. Default values of preprocessing, training, and various model architecture parameters are chosen based on our experience or are adapted from the academic literature, allowing novices to easily train complex models. At the same time, the ability to set each of them individually in the model configuration file offers full flexibility to experts. Each model trained with Ludwig is saved and can be loaded at a later time to obtain predictions on new data. As an example, models can be loaded in a serving environment to provide predictions in software applications.
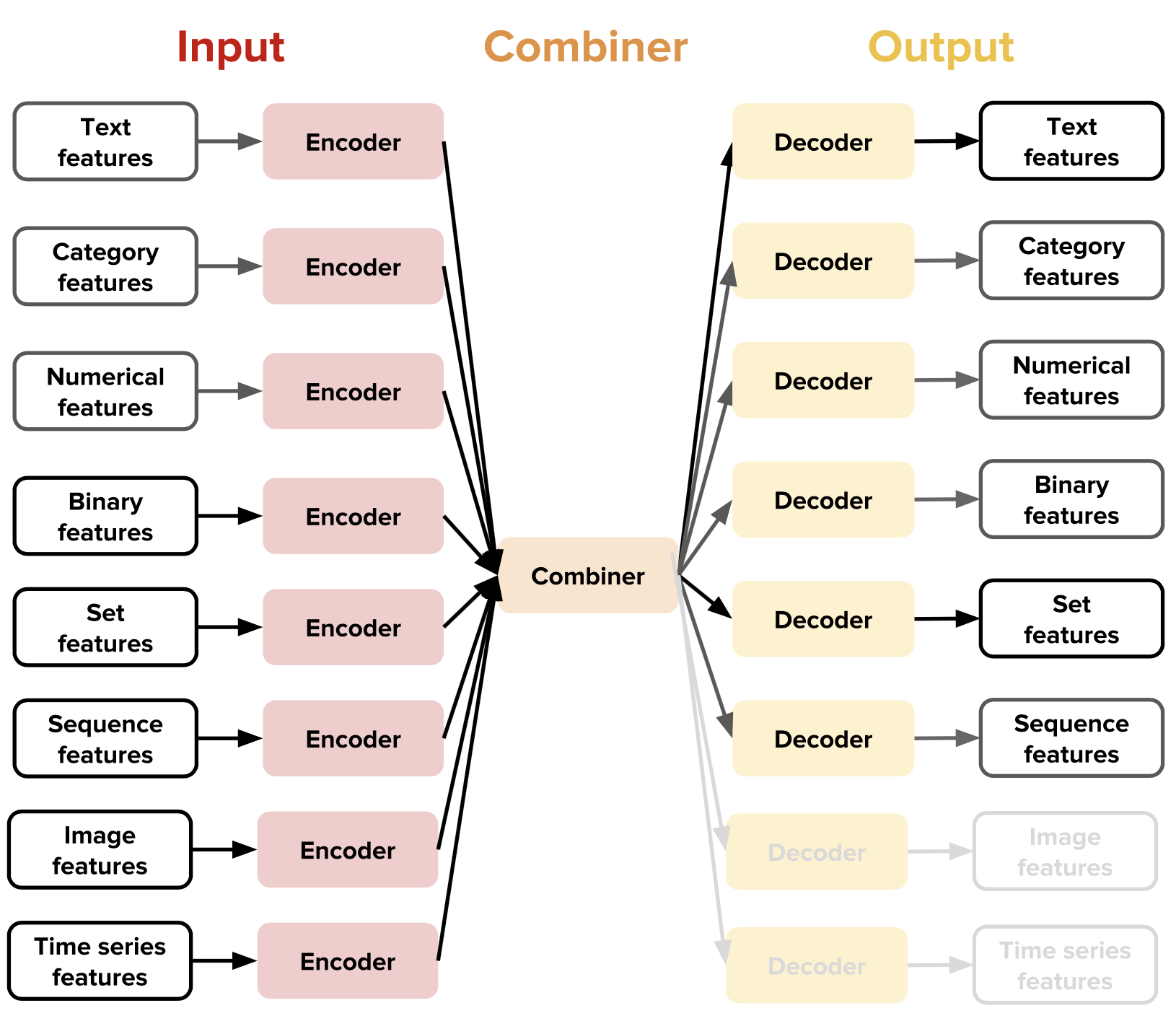
The main new idea that Ludwig introduces is the notion of data type-specific encoders and decoders, which results in a highly modularized and extensible architecture: each type of data supported (text, images, categories, and so on) has a specific preprocessing function. In short, encoders map the raw data to tensors, and decoders map tensors to the raw data.
With this design, the user has access to combiners (glue components of the architecture) that combine the tensors from all input encoders, process them, and return the tensors to be used for the output decoders. For instance, Ludwig’s default concat combiner concatenates the outputs of different encoders, passes them through fully connected layers, and provides the final activation as input for output decoders. Other combiners are available for other use cases, and many more can be easily added by implementing a simple function interface.
By composing these data type-specific components, users can make Ludwig train models on a wide variety of tasks. For example, by combining a text encoder and a category decoder, the user can obtain a text classifier, while combining an image encoder and a text decoder will enable the user to obtain an image captioning model.
Each data type may have more than one encoder and decoder. For instance, text can be encoded with a convolutional neural network (CNN), a recurrent neural network (RNN), or other encoders. The user can then specify which one to use and its hyperparameters directly in the model definition file without having to write a single line of code.
This versatile and flexible encoder-decoder architecture makes it easy for less experienced deep learning practitioners to train models for diverse machine learning tasks, such as text classification, object classification, image captioning, sequence tagging, regression, language modeling, machine translation, time series forecasting, and question answering. This opens up a variety of use cases that would typically be out of reach for inexperienced practitioners, and allows users experienced in one domain to approach new domains.
At the moment, Ludwig contains encoders and decoders for binary values, float numbers, categories, discrete sequences, sets, bags, images, text, and time series, together with the capability to load some pre-trained models (for instance word embeddings), but we plan to expand the supported data types in future releases.
In addition to its accessibility and flexible architecture, Ludwig also offers additional benefits for non-programmers. Ludwig incorporates a set of command line utilities for training, testing models, and obtaining predictions. Furthering its ease-of-use, the toolbox provides a programmatic API that allows users to train and use a model with just a couple lines of code.
Additionally, it includes a suite of other tools for evaluating models, comparing their performance and predictions through visualizations and extracting both model weights and activations from them.
Finally, the ability to train models on multiple GPUs locally and in a distributed fashion through the use of Horovod, an open source distributed training framework, makes it possible to iterate on models and obtain results quickly.
Using Ludwig
To better understand how to use Ludwig for real-world applications, let’s build a simple model with the toolbox. In this example, we create a model that predicts a book’s genre and price given its title, author, description, and cover.
Training the model
Our book dataset looks like the following:
| title | author | description | cover | genre | price |
| Do Androids Dream of Electric Sheep? | Philip K. Dick | By 2021, the World War has killed millions, driving entire species into extinction and sending mankind off-planet. … | path-to-image/do-android-cover.jpg | sci-fi | 9.32 |
| War and Peace | Leo Tolstoy | War and Peace broadly focuses on Napoleon’s invasion of Russia in 1812 and follows three of the most well-known characters in literature… | path-to-image/war-and-peace-cover.jpg | historical | 5.42 |
| The Name of the Rose | Umberto Eco | In 1327, Brother William of Baskerville is sent to investigate a wealthy Italian abbey whose monks are suspected of heresy. .. | path-to-image/name-of-the-rose-cover.jpg | historical | 16.99 |
| … | … | … | … | … | … |
In order to learn a model that uses the content of the title, author, description, and cover columns as inputs to predict the values in the genre and price columns, the model definition YAML would be:
input_features:
–
name: title
type: text
–
name: author
type: category
–
name: description
type: text
–
name: cover
type: image
output_features:
–
name: genre
type: category
–
name: price
type: numerical
training:
epochs: 10
We start the training by typing the following command in our console:
ludwig train –data_csv path/to/file.csv –model_definition_file model_definition.yaml
With this command, Ludwig performs a random split of the data in training, validation, and test sets, preprocess them, and builds four different encoders for the four inputs and one combiner and two decoders for the two output targets. Then, it trains the model on the training set until the accuracy on the validation set stops improving or the maximum number of ten epochs is reached.
Training progress will be displayed in the console, but TensorBoard can also be used.
Text features are encoded by default with a CNN encoder, but we could use, say, an RNN encoder that uses a a bidirectional LSTM with a state size of 200 for encoding the title instead. We would only need to change the title encoder definition to:
name: title
type: text
encoder: rnn
cell_type: lstm
bidirectional: true
If we wanted to change training parameters like number of epochs, learning rate, and batch size, we would change the model definition like this:
input_features:
– …
output_features:
– …
training:
epochs: 100
learning_rate: 0.001
batch_size: 64
All parameters on how to perform the split and data preprocessing, the parameters of each encoder combiner and decoder have default values, but they are configurable. Refer to the user guide to discover the wide variety of model definitions and training parameters available, and take a look at our examples to see how Ludwig can be used for several different tasks.
Visualizing training results
After training, Ludwig creates a result directory containing the trained model with its hyperparameters and summary statistics of the training process. We can visualize them using one of the several visualization options available with the visualize tool, for instance:
ludwig visualize –visualization learning_curves –training_stats results/training_stats.json
This will display a graph that looks like the following, showing the loss and accuracy as functions of train epoch number:
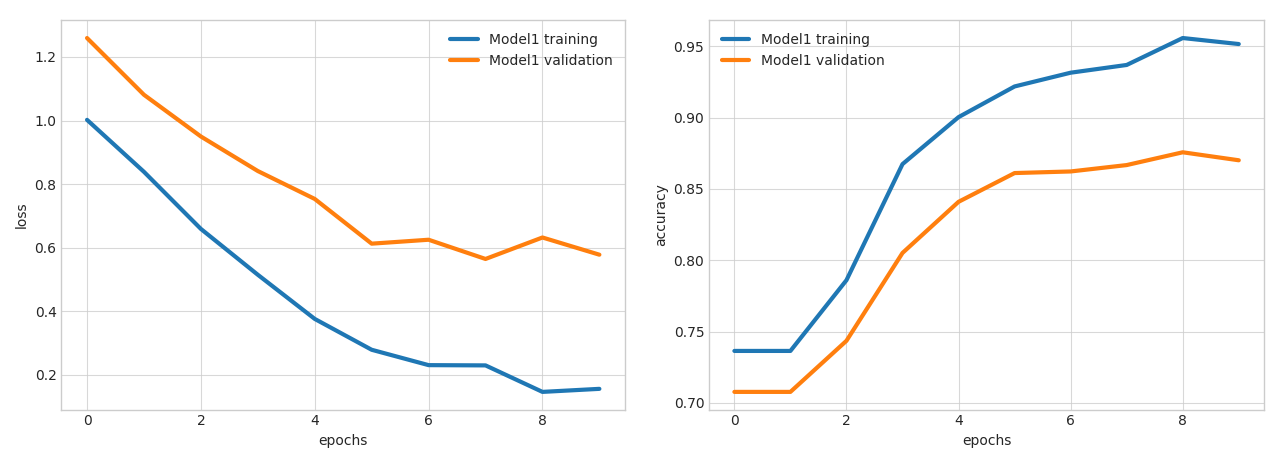
Several visualizations are available. The visualization section in the user guide offers more details.
Predicting results with trained models
Users with new data who want their previously trained models to predict target output values can type the following command:
ludwig predict –data_csv path/to/data.csv –model_path /path/to/model
If a dataset contains ground truth information to compare with predictions, running this command returns model predictions and also some test performance statistics. These can be visualized via the visualize command (above), which can also be used to compare the performance and results prediction of different models. For instance:
ludwig visualize –visualization compare_performance –test_stats path/to/test_stats_model_1.json path/to/test_stats_model_2.json
will return a bar plot comparing the models on different measures:
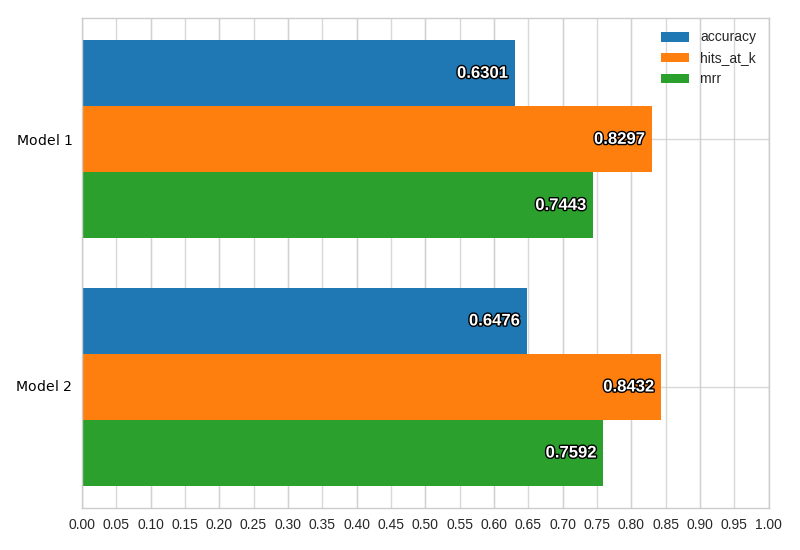
There is also a handi experiment command that performs first training and then prediction without the need to use two separate command.
Using Ludwig’s programmatic API
Ludwig also provides a simple Python programmatic API that lets users train or load a model and use it to obtain predictions on new data:
from ludwig import LudwigModel
# train a model
model_definition = {…}
model = LudwigModel(model_definition)
train_stats = model.train(training_dataframe)
# or load a model
model = LudwigModel.load(model_path)
# obtain predictions
predictions = model.predict(test_dataframe)
model.close()
This API enables using models trained with Ludwig inside existing code to build applications on top of them. More details on using a programmatic API with Ludwig are provided in the user guide and in the API documentation.
Conclusions
We decided to open source Ludwig because we believe that it can be a useful tool for non-expert machine learning practitioners and experienced deep learning developers and researchers alike. The non-experts can quickly train and test deep learning models without having to write code. Experts can obtain strong baselines to compare their models against and have an experimentation setting that makes it easy to test new ideas and analyze models by performing standard data preprocessing and visualization.
In future releases, we hope to add several new encoders for each data type, such as Transformer, ELMo, and BERT for text, and DenseNet and FractalNet for images. We also want to add additional data types like audio, point clouds, and graphs, while at the same time integrating more scalable solutions for managing big data sets, like Petastorm.
Ludwig is built with extensibility principles in mind and, in order to facilitate contributions from the community, we provide a developer guide that showcases how simple it is to add additional data types as well as additional encoders and decoders for already existing ones.
We hope you will enjoy using our tool as much as we enjoyed building it!
If building the next generation of machine learning tools interests you, consider applying for a role with Uber AI!

Piero Molino
Piero is a Staff Research Scientist in the Hazy research group at Stanford University. He is a former founding member of Uber AI where he created Ludwig, worked on applied projects (COTA, Graph Learning for Uber Eats, Uber’s Dialogue System) and published research on NLP, Dialogue, Visualization, Graph Learning, Reinforcement Learning and Computer Vision.

Yaroslav Dudin
Yaroslav Dudin is a senior software engineer on Uber's New Mobility Optimization team.

Sai Sumanth Miryala
Sai Sumanth Miryala is a data scientist on Uber's Conversational AI team.
Posted by Piero Molino, Yaroslav Dudin, Sai Sumanth Miryala
Related articles





Most popular

A beginner’s guide to Uber vouchers for transit agency riders

Uber Earner x Miami HEAT Ticket Sweepstakes OFFICIAL RULES

Case study: Tri-Rail’s role in paving the way for effortless commuting

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
