Improving HDFS I/O Utilization for Efficiency
October 13, 2021 / Global
Scaling our data infrastructure with lower hardware costs while maintaining high performance and service reliability has been no easy feat. To accommodate the exponential growth in both Data Storage and Analytics Compute at Uber, the Data Infrastructure team massively overhauled its approach in scaling the Apache Hadoop® Data File System (HDFS) by re-architecting the software layer in conjunction with a hardware redesign:
- HDFS Federation, Warm Storage, YARN co-location on HDFS data nodes and increased YARN utilization improved the systems’ CPU & Memory usage efficiency
- Combining multiple Hardware server designs (24 x 2TB HDD, 24 x 4TB HDD, 35 x 8TB HDD) into a unified design of 35 x 16TB HDD for 30% Hardware cost reduction
The New “CAP” Theorem
One may have seen the CAP theorem in the headlines of many articles and papers related to distributed systems, and it states: Consistency, Availability, and Partition tolerance: Pick Two!
The next generation of Data Infrastructure applies logic similar to the CAP theorem—that infrastructure can deliver only 2 of the 3 desired characteristics, namely: Cost efficiency, Availability, and Performance.
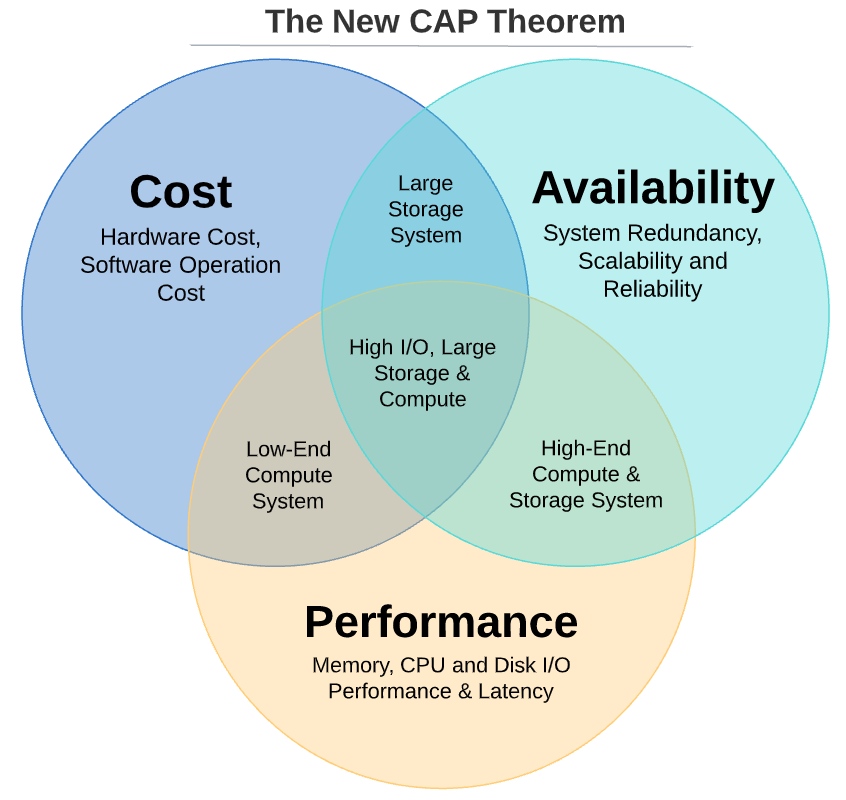
Cost efficiency is one of Uber’s top priorities, and HDFS is an essential data service at Uber that must achieve 99.9+% availability. We cannot compromise either of these two characteristics. The question then becomes: do we have to sacrifice HDFS performance (especially IO performance) in exchange for cost efficiency and availability?
In the following blog, we try to analyze current HDFS disk IO utilization to evaluate whether we will hit the “IO wall” when multiple data services are running on our next generation, industry-leading, high-density hardware.
How Busy are the Hard Drives?
With that question in mind, we turned to usage metrics to analyze IO utilization for all 134,000 hard drives in the HDFS clusters. The data we got was astonishing:
- The Good: ~90% of the disks have an average IO utilization of less than 6%.
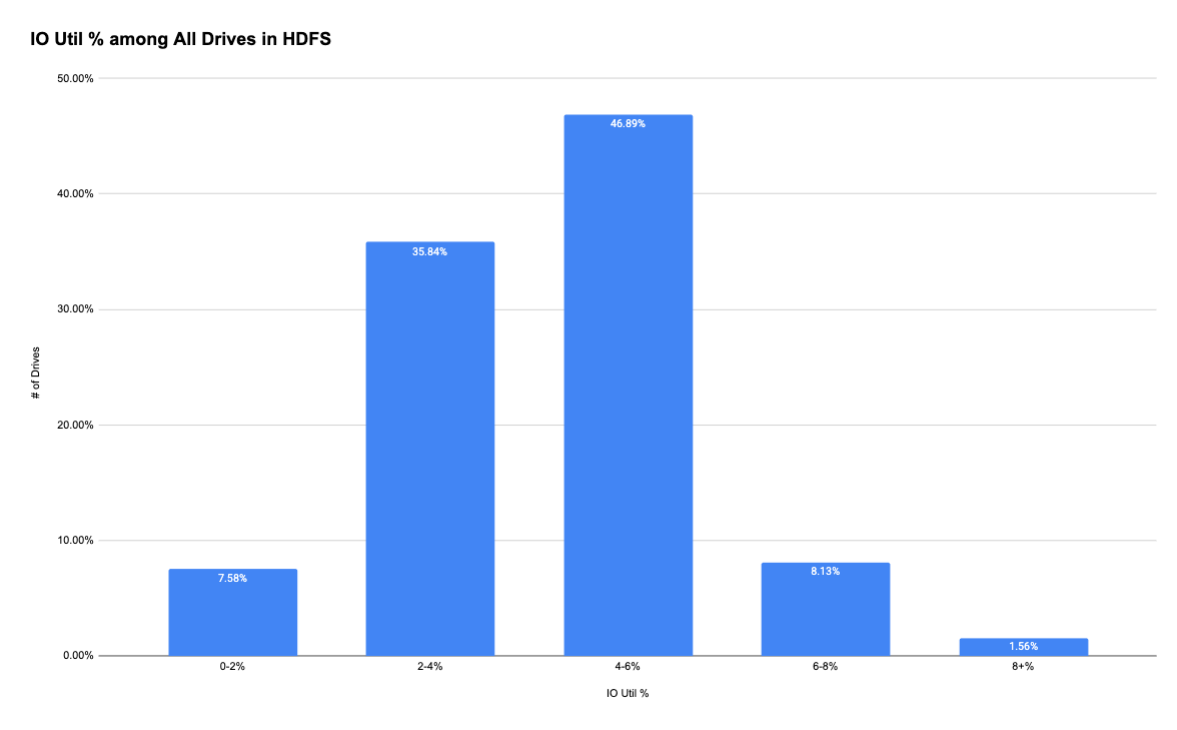
- The Bad: the tail end of disk IO utilization can be as high as more than 15%, which is more than 5 times greater than the average disk IO utilization. Even though these disks are a fraction of the entire disk pool, they represent thousands of drives.
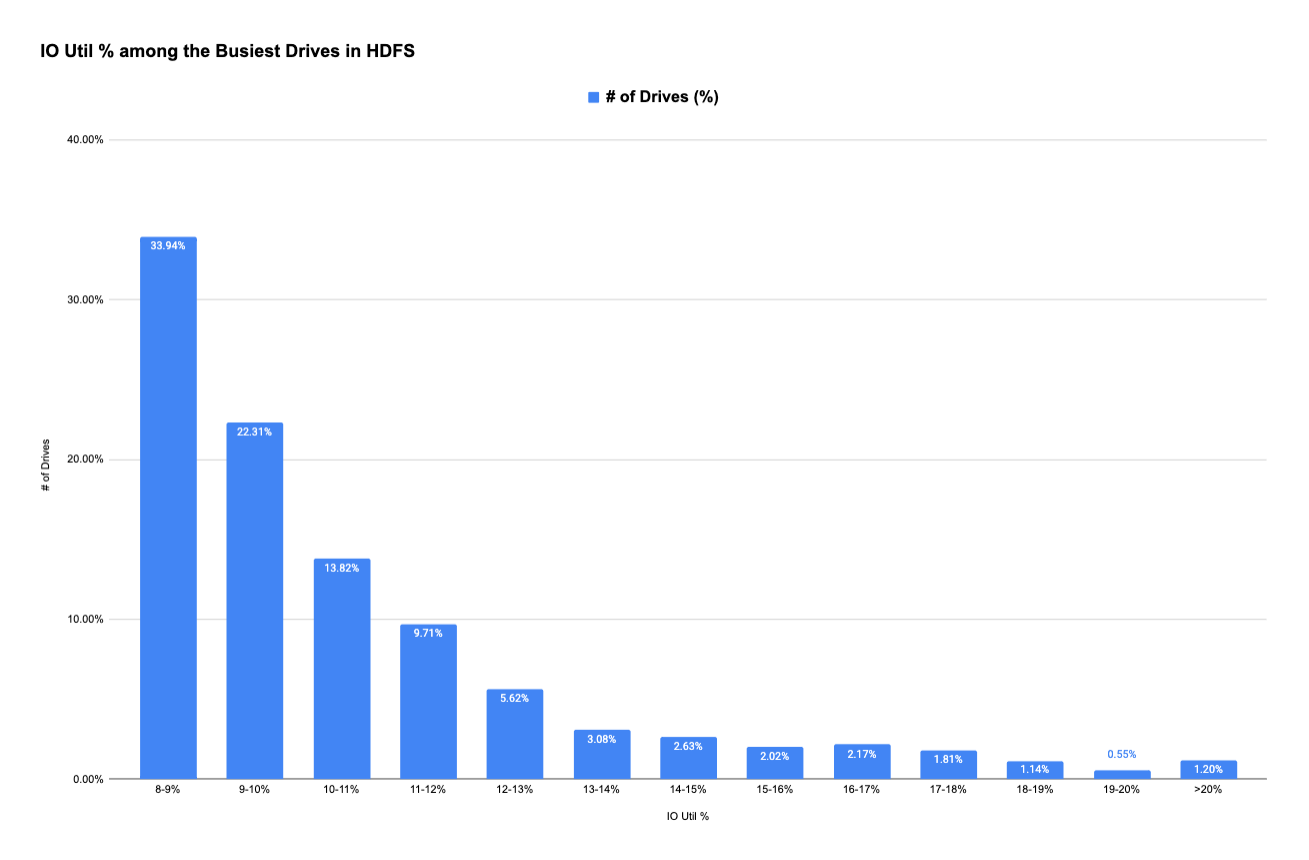
How are these busy disks distributed among all HDFS hosts: evenly distributed among a large number of the hosts, or concentrated in a small group of hosts? If the answer is the latter, then this may pose a significant issue for the upcoming high-density HDFS servers, which are running multiple services.
How Busy are the Hosts?
To answer this question, we selected the top 10% of the busiest disks (>13,000 disks) and checked how they were distributed among the ~5,600 HDFS hosts. Interestingly, the results showed that about 55% of the busiest drives comprised 10% of the HDFS hosts.
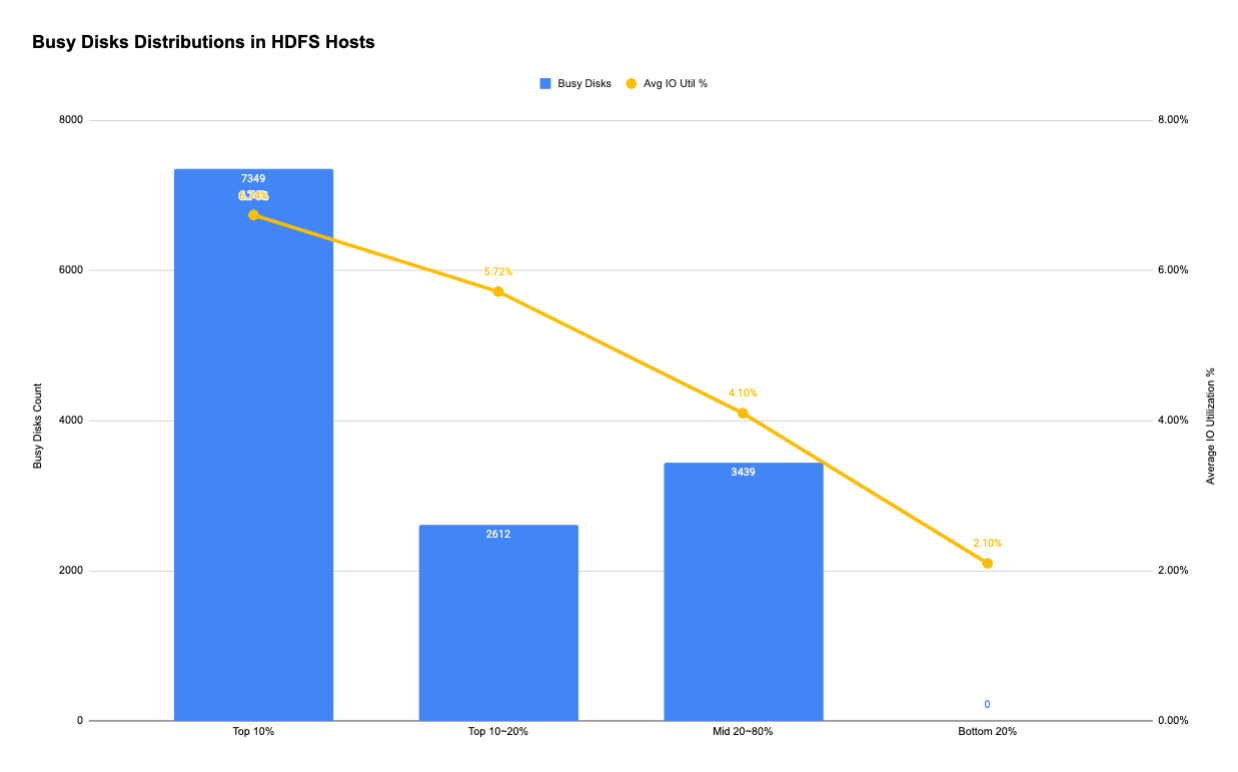
The data showed that the busiest disks are indeed concentrated in a small group of hosts, rather than distributed among all hosts. This suggested that we should focus our efforts on these most IO-active hosts, since they have a much higher chance of becoming the IO bottleneck as we grow.
How Busy are the Clusters?
Our initial focus was the top 330 busiest hosts that we identified earlier. Further examination showed that these 330 hot Data Nodes resided in 4 out of the total ~20 HDFS clusters:
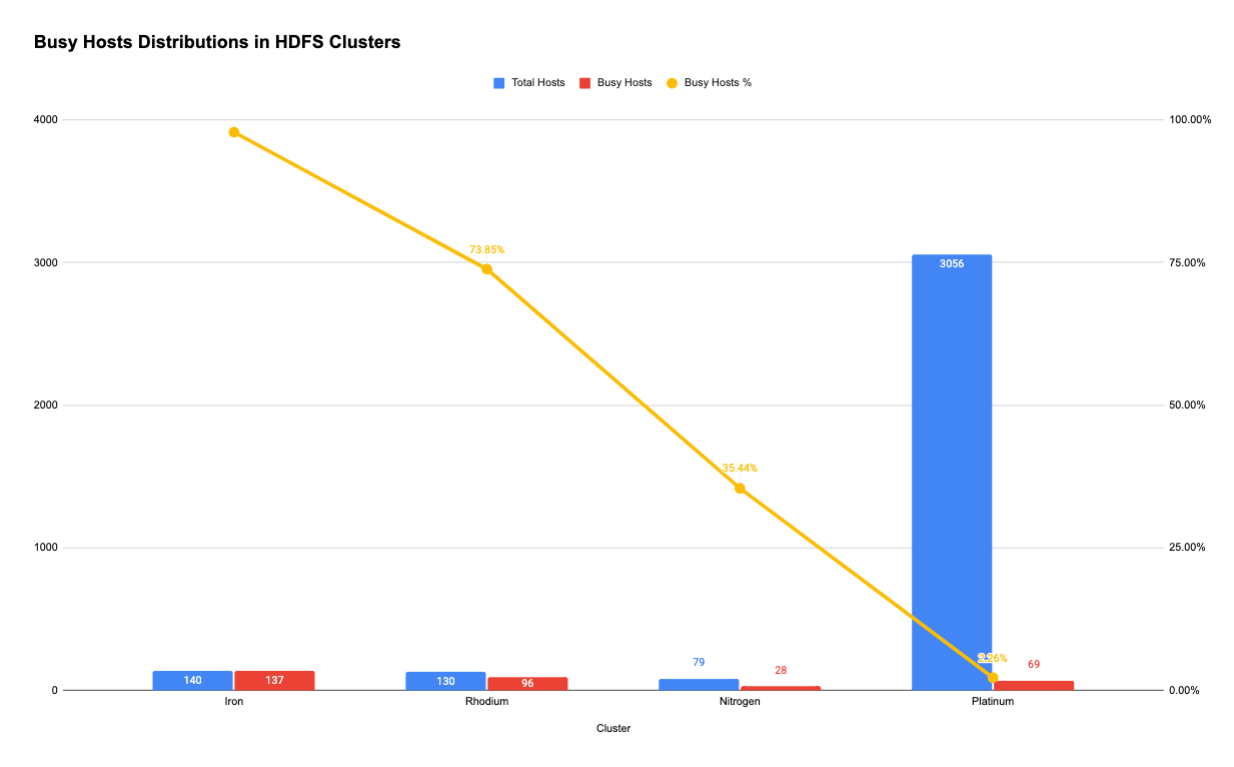
The data tells us one fact: cluster usage is a major factor of disk IO utilization. Cluster-level IO utilization, especially unbalanced IO traffic, is the top priority that the team should address.
How to Improve the HDFS IO Utilization?
The Hadoop team took actions to address the issue immediately:
- Increased the cluster size for small, busy clusters, such as Tmp and Ingestion clusters;
- Rebalanced the disk capacity usage among all HDFS nodes
- Working on data block balance and placement based on data age
After actions were taken, we once again studied the top 10% of busiest HDFS nodes. We found that the small, busy clusters disappeared. However, the top 10% (or 558) most active hosts were all in the main HDFS cluster, which has over 3,000 Data Nodes. This raised another question: why were they all in one of the largest HDFS clusters? Further study showed that these 558 hosts have one thing in common: they were co-located with the newly added YARN services to fully utilize the hardware resources that were not being used by the HDFS service.
To understand the impact of co-located YARN services on the HDFS hosts, we examined the entire disk IO utilization again, and we compared all disk IO utilization based on the services running on the hosts. The differences were significant: disks taking both HDFS and YARN workloads had much higher IO utilization than those running HDFS only.
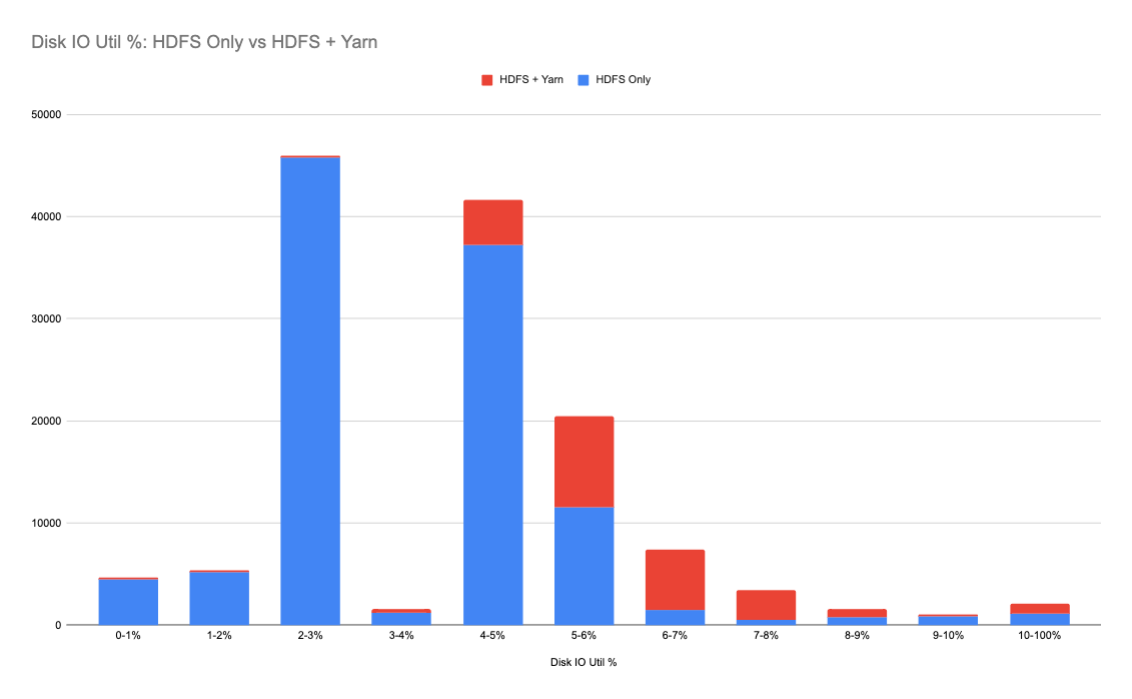
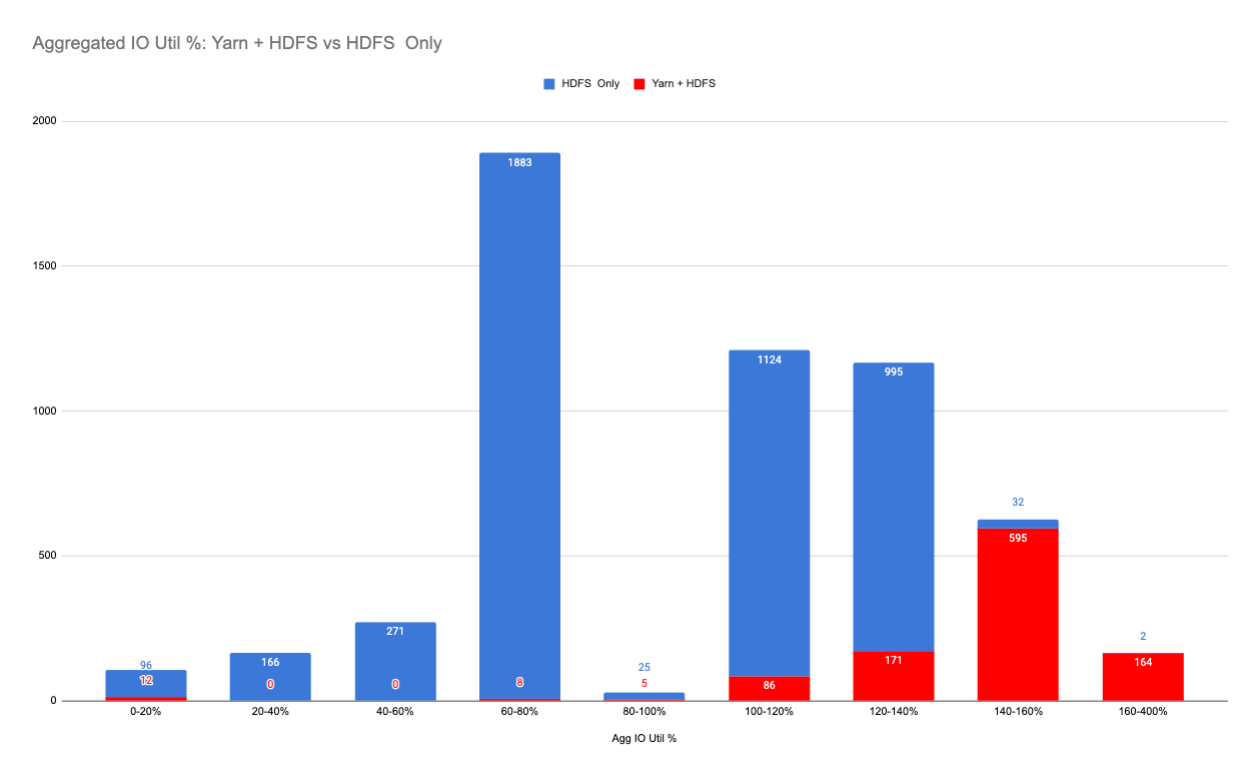
At the host level, the aggregated disk IO utilization was more significant: the co-located YARN service brought in much higher IO requests to the HDFS nodes at the per-host level.
What is the Long-term Strategy?
Massive disk IO operations from YARN service were not only hurting the IO performance, but they also occupied disk space, generating a higher disk failure rate and adding additional cost to the daily operation of hosts. We recognized these challenges, and decided to add a dedicated SSD in our next generation HDFS servers to handle disk IO requests from YARN service. This will eliminate all the negative impacts introduced by YARN co-location with a fractional cost. Meanwhile, the Spark team has come up with a remote shuffle service that will cut down about 50% of local disk writes, and will roll this out in the next couple of months.
We believe that all excellent engineering wins come from understanding our applications well and shaping the engineering decisions around these use cases. If using your detective skills to determine how to optimize Big Data and make our Data Infrastructure more efficient appeals to you, consider applying for a role on our team!
Apache®, Apache Hadoop®, and Hadoop® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.

Kevin Cheng
Kevin Cheng is a Senior Software Engineer II on Uber’s Core Data team. He is managing Data’s infrastructure reliability, efficiency, and performance. Before Uber, he worked on system design for over 20 years.

Jeffrey Zhong
Jeffrey Zhong is a former Engineering manager on Uber’s Core Data team, and managed data lake storage (Hadoop HDFS & Apache Hudi), batch compute scheduling (Hadoop YARN), and Data’s hardware and performance. Before Uber, he worked on Apache HBase and Apache Phoenix.
Posted by Kevin Cheng, Jeffrey Zhong
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
