
Painting the Picture
Before 2021, Uber engineers would have to take quite a taxing journey to make a code change to the Go Monorepo. First, the engineer would make their changes on a local branch and put up a code revision to our internal code review system, Phabricator. Next, our infrastructure would see the request and initiate a number of validation jobs on our CI. Those jobs would run build and test validation using the Bazel™ build system, check the coverage, do some other work, and report back to the user a red light (i.e., tests failed or some other issues) or green light. Next, the user, after seeing the “green light,” would get their code reviewed and then initiate a “land” request to the Submit Queue. The queue, after receiving their request, would patch their changes on the latest HEAD of the main branch and re-run these associated builds and tests to make sure their change would be valid at the current state of the repository. If everything looked good, the changes would be pushed and the revision would be closed.
This sounds pretty easy, right? Make sure everything is green, reviewed, and then let the queue do the work to push your change!
Well… what if the change is to a fundamental and widely used library? All packages depending on the library will need to be validated, even though the change itself is only a few lines of code. This might slow down the “build and test” part. Validating this change could sometimes take several hours. Internally, we call such changes big changes.
CTC: Changed Targets Calculation
Our CI uses an algorithm we call Changed Targets Calculation (CTC). CTC creates a Merkle-style tree, where each node (representing each Go package) is computed from all of its source files and inputs. Using this, we can compute this tree before and after a change, and see which Go packages (Bazel targets) have been altered by the change. These targets represent both “directly” and “indirectly” changed targets, which will all need to be retested and rebuilt to validate whether the change is in fact green. Changed targets calculation at the time took about 5 minutes to run and had to be run for every single change. If a change has more than a certain number (say 10,000) of affected targets, then it is labeled a big change.
The Problem
But one big change here and there—what’s the big deal? SubmitQueue can still validate and land other changes concurrently, right?
Not really… SubmitQueue has a Conflict Analyzer to decide whether a change is in conflict with other changes earlier in the queue. If there is no conflict, SubmitQueue can validate and land the change concurrently. However, when there is a change in the SubmitQueue that affects a very large portion of the repository, it will be in conflict with most other changes. Consequently, most changes that SubmitQueue receives after the big change will have to wait. SubmitQueue also speculates on the most likely outcomes of preceding changes, so the validation of a change can start (and possibly finish) before all proceeding changes in the queue have been validated. However, a change still has to wait for the validation outcome of all preceding conflicting changes in order to decide which speculation path to take. As a result, we often saw a big change blocking many changes behind it, and all those changes had finished their validation on several speculation paths.
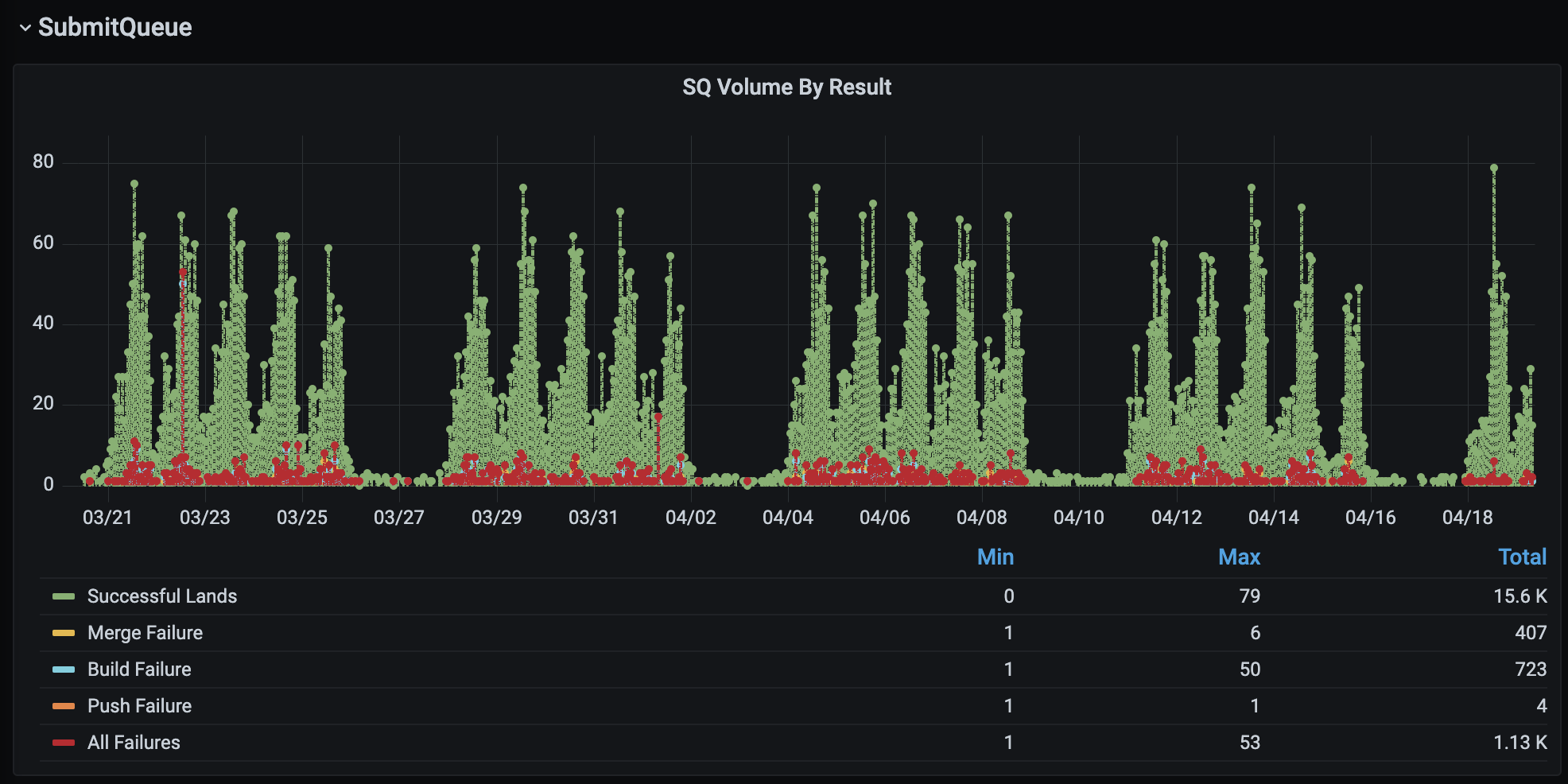
Currently, Uber engineers introduce around 50 code changes per hour to the Go Monorepo during working hours. This means if the change at the head of the queue is large enough to affect other changes and takes an hour to test, none of the other 49 changes can proceed until this change lands. Now each of these 50 engineers will wait for over an hour for their code to land.
So, what can we do here to fix this problem? Well, we came up with these three options:
- Optimizing SubmitQueue
- Make sure there aren’t any “big” (slow) changes waiting in line
- Make the build and test faster
Optimizing SubmitQueue
First, we optimized the Conflict Analyzer algorithm to simplify the conflicts graph, which reduced cost and latency due to a decrease of job load. Next, we worked on speeding up pushing the change to the main branch. Before CI, diffs will enter a validation stage, where the system tries to cherry-pick the change onto the current HEAD of the repository and rejects the change if there’s a conflict. Meanwhile, it would also push the cherry-picked branch to the remote to share with other actions. Finally, if everything looks good, the cherry-picked commit is pushed. This way, we minimize the effort of having to perform expensive fetch and patch.
These optimizations reduced our push time by around 65% and even more for overall in-queue time. This effort required a lot of research and experimentation, which we will cover more in future posts.
Blocking Large Changes During Working Hours
Despite all possible solutions, the lack of infrastructure features and the urgency of this issue required an easy, short-term fix. Thus, we chose the easiest to implement and fastest to deliver (delivered in days) feature option: blocking large changes during working hours.
We did this by engineering a “guard,” which would stop any change from entering the landing queue during work hours if it was considered “large”.
Implementation of the guard was easy, and showed immediate success in queue times; however, we received some complaints:
- Wait: Engineers with large and important changes do not want to have to wait until after the work day to land their changes.
- Time: Finding a proper blackout landing window is tricky. Uber Engineering offices are distributed across the globe, meaning any hour of the day is during someone’s “working hours”. However, the load distribution is not even. So we switched to the term “peak hours” instead (i.e., block large diffs during peak hours, which are mostly US time zones).
- Special attention needed: Large changes are also more prone to outages. If we land them outside the working hours, there would be limited resources to mitigate potential outages. To prevent this, we ended up asking engineers to get up early to deploy these changes (e.g., a Go compiler upgrade).
We have added a “delayed lands” feature to support this solution, which automatically would land the diff after the peak hours. However, that wasn’t good enough.
We need to validate the changes faster.
Designing Faster CI Builds
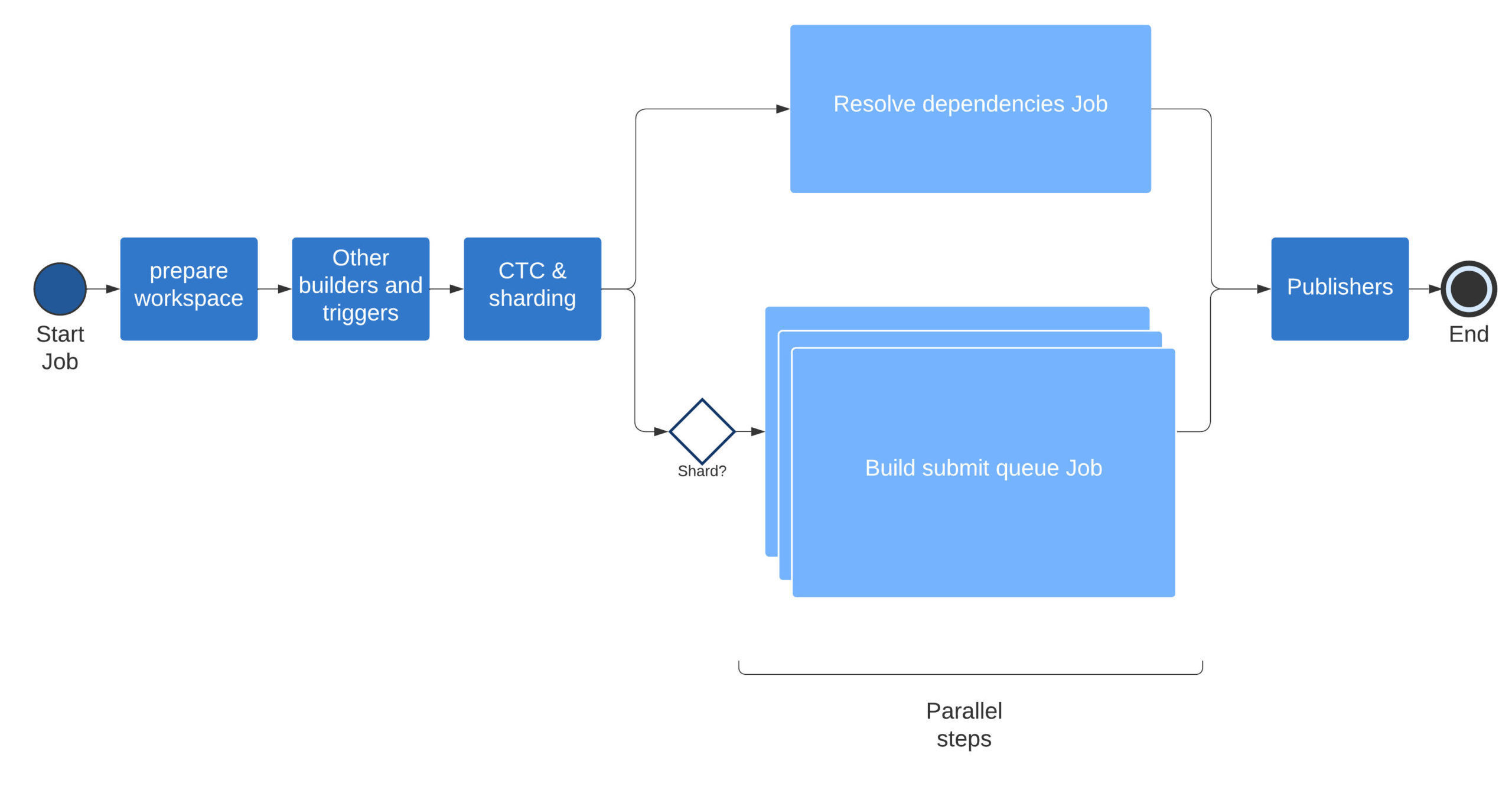
Existing CI builds contained these main steps:
- Build environment preparation
- Various build pre-checks: to fail faster (e.g., dependency checks or linting checks)
- CTC: to detect what to validate
- Bazel build and test: the most time-consuming part of validation
- Results analyzer and publisher: to report to an Engineer and related systems
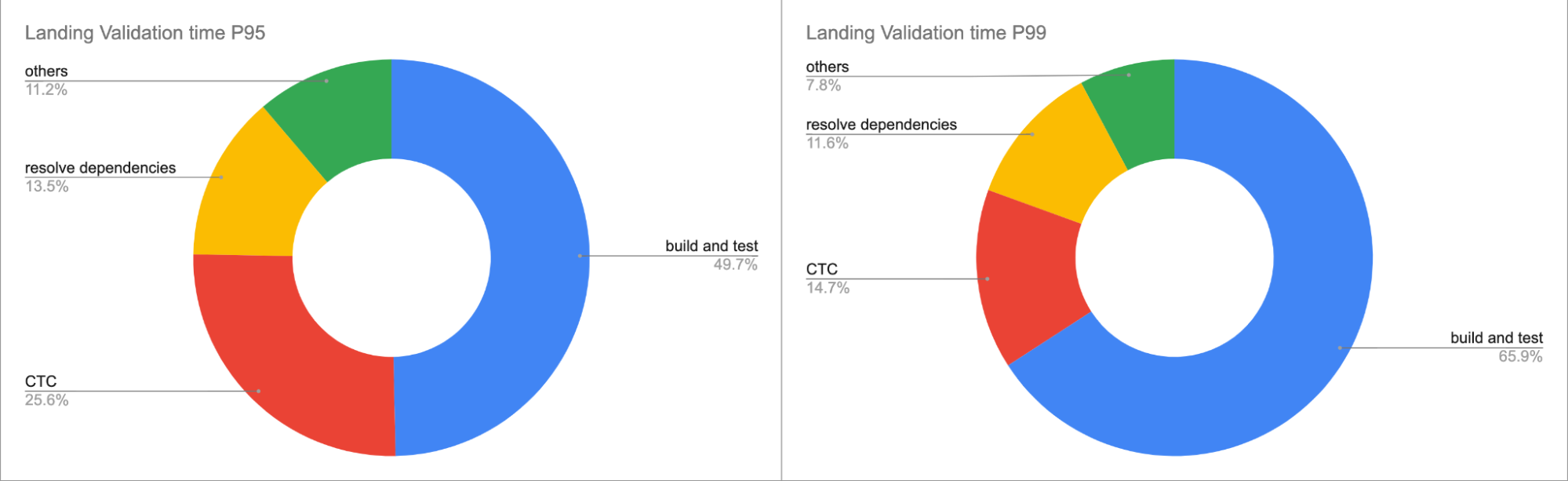
All these steps were executed in sequence. The main question was which parts we could parallelize and how.
As seen in the chart above, the main consumers are Bazel build/test, CTC, and resolve dependencies check. It turns out that the Resolve dependencies check is independent of CTC and Bazel builds and could be executed in parallel, which was a free win. Bazel build is dependent on CTC results so it can’t be parallelized. The main part that could be parallelized and provide the wanted results was Bazel build.
Because our CTC yielded a list of changed targets, why not just split these up and run them on separate machines or hosts? Well, that’s exactly what we did.
Optimizing Legacy Jenkins
Uber’s CI used to run on Jenkins using a MultiJob plugin to define a graph of Jenkins jobs that will be executed in sequence or in parallel. Even though that plugin requires a static hierarchy, with some tricks we managed to get it to act dynamically. We statically defined 50 shards and each shard was launched depending on the metadata. In the end, it looked like dynamic sharding.
Now, rather than running 10,000 targets in an hour, we could run them in ~10 minutes.
Unfortunately, we could not cut the time by 1/50 with 50 shards. Although we tried to distribute the same amount of changed targets to every shard, targets built on different shards may depend on the same targets. Such targets may need to be built more than once, on every shard that needs them. Imagine there is a build graph, where target //a depends on target //b, and target //c depends on target //d. If a developer changed both //b and //d, then CTC would return //a, //b, //c, //d for building and testing. In a naive sharding strategy, //a and //c may be assigned to one shard, and //b and //d to another. Because of the dependency, the sharding building //a and //c will have to build //b and //d too, causing //b and //d to be built on both shards, which is inefficient.
To reduce the overlap, we changed CTC to compute the root targets, which means no other targets in the build graph depend on them. In the above example, //a and //c are root targets. Because of the dependencies, building //a implicitly requires building //b, building //c implicitly requires building //d, we don’t need to explicitly build //b and //d. If we assign shards according to root targets, //a and //b, //c and //d each will be built on the same shard, reducing the duplication.
This change was great and allowed us to remove our guard for large changes, which made everyone happy.
The end result was:
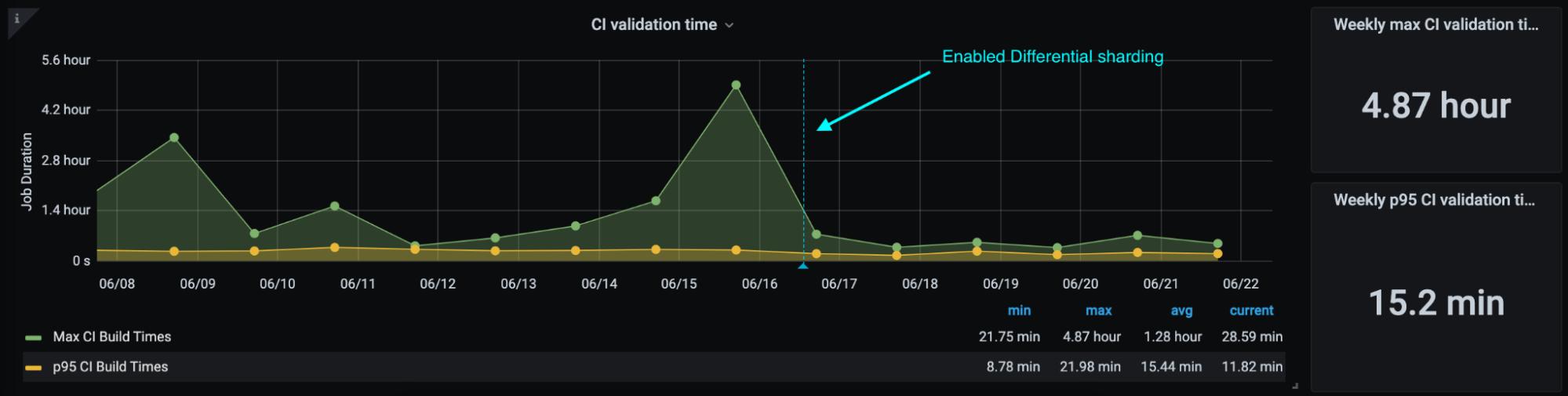
However, to improve further we required an actual dynamic CI system, so we started looking into Buildkite.
Building a True Dynamic CI in Buildkite
By “dynamic,” the root meaning of this improvement was that we could configure each build and its configuration at runtime. For example: If CTC didn’t yield any target changes, we could immediately skip the build/test step. If a change touched only a single target, we could run it in one “shard,” but if this number grew, we could dynamically and intelligently split the number of targets into a changing set of shards.
Buildkite runs each shard of each step in a separate container (i.e., separate checkout of the repo). While this reduces side effects from potential cross-contamination (environment variables, etc.), this introduces some other problems.
Checking out a repo with 500,000 files and a really complex history is… you guessed it… slow. The bottleneck became more about job “setup” than the actual validation of the change. Due to containerization, builds were not aware of each other and thus were doing repetitive work, without sharing a common cache. Initially, containerized Buildkite builds showed much lower P99 and P95 than non-containerized Jenkins jobs, but an increased P50 and mean, simply because of an important fact: In a repo with over 10,000,000 targets, most changes are small changes.
We addressed this problem in a couple of directions:
Improving Our Git to be Faster
Because we run thousands of parallel builds, each of which clones the Monorepo, it quickly became a necessity for our repository-hosting backend to catch up with our usage. We then implemented our own internal plugin to replace the out-of-the-box Buildkite checkout strategy. In a nutshell, we maintain a periodically refreshed Git snapshot that can be fast downloaded atomically to the machine before the checkout happens. Each build can then refresh the index with that snapshot, rather than needing to manually checkout the repository. Eventually, only the commits after the latest cached state need to be fetched during checkout.
“Stateful” CI
Persistent Container Environment
Initially, we started a brand new docker container for each test shard, then tore it down when the shard finished. This means each time when a shard runs, there’s a fixed overhead, such as starting a new container, starting the Bazel server etc., and its memory state is reset. But what if we reuse the same container and keep the memory footprint? We then implemented a mechanism that starts a persistent container and only sends commands to it. The container is ID-ed by multiple variables such as Bazel version, image hash, job name, etc., to ensure that commands run on the correct container and new containers are created at the right time, such as Bazel upgrades and image updates. We noticed nearly 60% improvement in CTC run time with this approach.
Host Cache
To ensure the integrity of our dependency graph, we run go mod tidy in each of our CI jobs. This operation downloads all the dependency module cache for our entire repo, which can be both heavy for our internal module proxy and slow for CI machines, especially for the first job that runs on the host. To address this latency, we periodically prepare a snapshot of the cache. The first job on the machine will download it and mount it to the container to share with subsequent jobs. We also enable a similar sharing mechanism for the Bazel output base and prewarm the Bazel build graph prior to running CTC.
Another issue we discovered was that some targets couldn’t be separated, and were extremely slow to build and test every time. No matter how many shards we initiated, these would always become a bottleneck. This was optimized primarily through the implementation of a shared remote Bazel cache.
Remote Cache
We talked about sharding and root target calculation to avoid building the same target on more than one shard. Unfortunately, this may not work in all cases. Imagine there is a package depended on by many root targets; these root targets may still be assigned to different shards, causing the package to be built on multiple shards. Can we do better?
Exploiting the fact that Bazel is an artifact-based build system, and assuming that every build is deterministic, we can simply save these build artifacts in a shared place and reuse them if the build/test has already been done before. This shared place is called the remote cache. Once a package is built on a shard, the resulting artifacts are uploaded to the remote cache. Before a second shard builds the package, it can check the remote cache. If the artifacts produced by that package are already available, the second shard can download and reuse them.
We started with an internal implementation of the remote cache based on HTTP, and then migrated to an gRPC-based remote cache hosted by Google Cloud Services (GCS). This migration stabilized the P95, from fluctuating between 40 and over 100 minutes to being consistently below 40 minutes. In 2021, we further migrated the remote cache from GCS to Buildfarm, which cut down the build time by about half.
One thing you may have asked yourself along the way: if you’re running tests both as a CI validation step and again as a landing validation step, isn’t this redundant?
Yes and No.
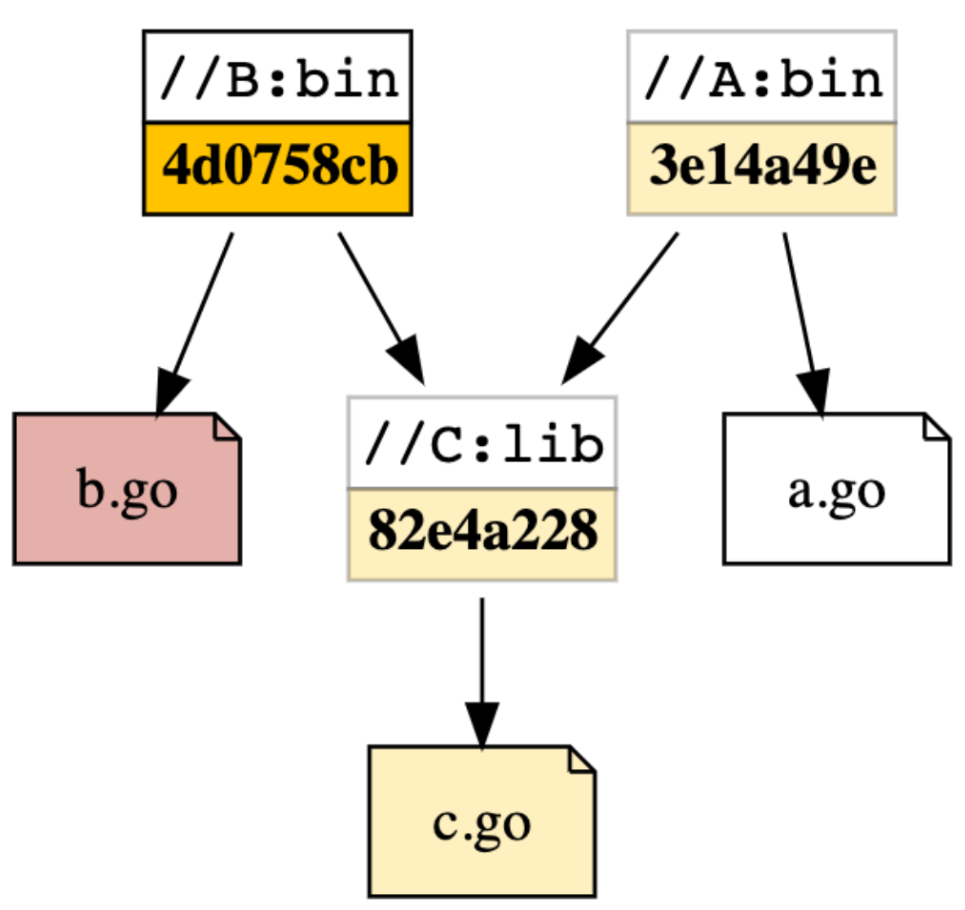
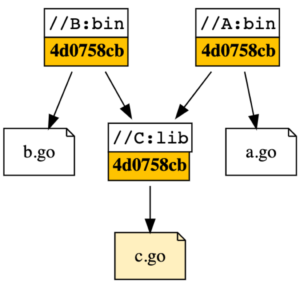
Let’s say there are two targets, //A:bin and //B:bin, which depend on a common library //C:lib. Imagine two separate changes, diff1 change to A and C, and diff2 change to B. When the changes are first authored, jobs will need to run to validate A, B, and C in diff1, and separately but similarly diff2 will test B.
Now, consider when a user pushes diff1 into the landing queue. Since A, B, C have already been done, rerunning this test would actually be redundant work, since we know that nothing here has changed since it was tested. Then imagine diff2 is later pushed into the queue after diff1 landed. Because B depends on C, but C was just updated in diff1, B needs to be retested with the new C to ensure this change is still valid at the HEAD of main.
How do we optimize this without having some shared “higher power” that knows everything that’s already been tested? We can’t, so that’s exactly what we’ll do, using a shared remote cache. Bazel caches both build artifacts and test results in the remote cache. Although a test was run a few days ago when diff1 was created on a different machine and a different Buildkite pipeline, Bazel can check the remote cache and check whether any of the test’s dependencies have changed since then. If not, it will fetch the test result from the remote cache when we are landing diff1, thus avoiding running tests for //A:bin, //B:bin, and //C:lib again.
Conclusion
Even with a rate of 50 changes per hour, an engineer can land a change that affects the entire repository in under 15 minutes. This efficiency helps keep engineering productivity high, reduces merge conflicts from staleness, and increases morale.
Additionally, it helped our team focus on increasing the complexity and features of our change validation process.

Tyler French
Tyler French is a Software Engineer II on Uber's Developer Platform team and is based in New York City. Tyler leads the dependency management initiative within the Go developer experience. His interests lie in leveraging data and analyzing patterns to strategically improve the engineering experience.

Mindaugas Rukas
Mindaugas Rukas is a Sr. Software Engineer on Uber's Developer Platform team. Mindaugas leads the infrastructure part of the Go Monorepo project, making it more reliable, scalable, and performant.

Xiaoyang Tan
Xiaoyang Tan is a Sr. Software Engineer on Uber's Developer Platform team. He leads the CI architecture in the Go Monorepo and other various tooling infrastructures to better the developer experience at Uber.
Posted by Tyler French, Mindaugas Rukas, Xiaoyang Tan
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
