
Introduction
Data is crucial for our products. Data analytics help us provide a frictionless experience to the people that use our services. It also enables our engineers, product managers, data analysts, and data scientists to make informed decisions. The impact of data analysis can be seen in every screen of our app: what is displayed on the home screen, the order in which products are shown, what relevant messages are shown to users, what is stopping users from taking rides or signing up, and so on.
With such a huge user base and wide range of features, support across all geographic regions is a complicated problem to solve. Furthermore, our app keeps expanding with new products, which mandates that the underlying tech also be flexible enough to evolve and support them.
Data is the primary tool enabling this. The following article will focus on rider data in particular: how we collect and process it, and how that has informed concrete improvements to the Rider app.
Rider Data
Rider data comprises all the rider’s interaction with the Uber Rider App. This accounts for billions of events from Uber’s online systems every day, which are in turn converted into hundreds of Apache Hive™ tables for different use cases, powering the Rider app.
These are some of the top problem areas which can make use of rider data analytics:
-
-
- Increasing funnel conversion
- Increasing user engagement
- Personalization
- User communication
-
Online Data Collection
Mobile Event Logging
Rider data has multiple sources, but a primary one is capturing how users interact with the App. User interaction is captured through event logging from mobile. The Logging architecture is designed around the following key principles:
-
-
- Standardization of logs
- Consistency across platforms (iOS, Android, Web)
- Respecting user privacy settings
- Optimizing network usage
- Reliable without degrading the user experience
-
Standardizing Logs
It’s important to have a standardized process for logging, since hundreds of engineers are involved in adding or editing events. Logs that are captured on the client are either platformized (e.g., events like user interactions with UI elements, impressions etc.), or added manually by the developers.
A default set of metadata is standardized and extracted out as a common payload, which is sent with every event, such as location, app version, device, screen name etc. This can be essential for formulating metrics at the back end.
Furthermore, to ensure that all events are consistent across platforms and have standardized metadata, we have defined thrift structs that need to be implemented by the event models to define its payload. Thrift schema include an enum representing the event ID on different platforms, and a payload struct defining all the data that needs to be associated with the event at the time of registration, and finally the event type.
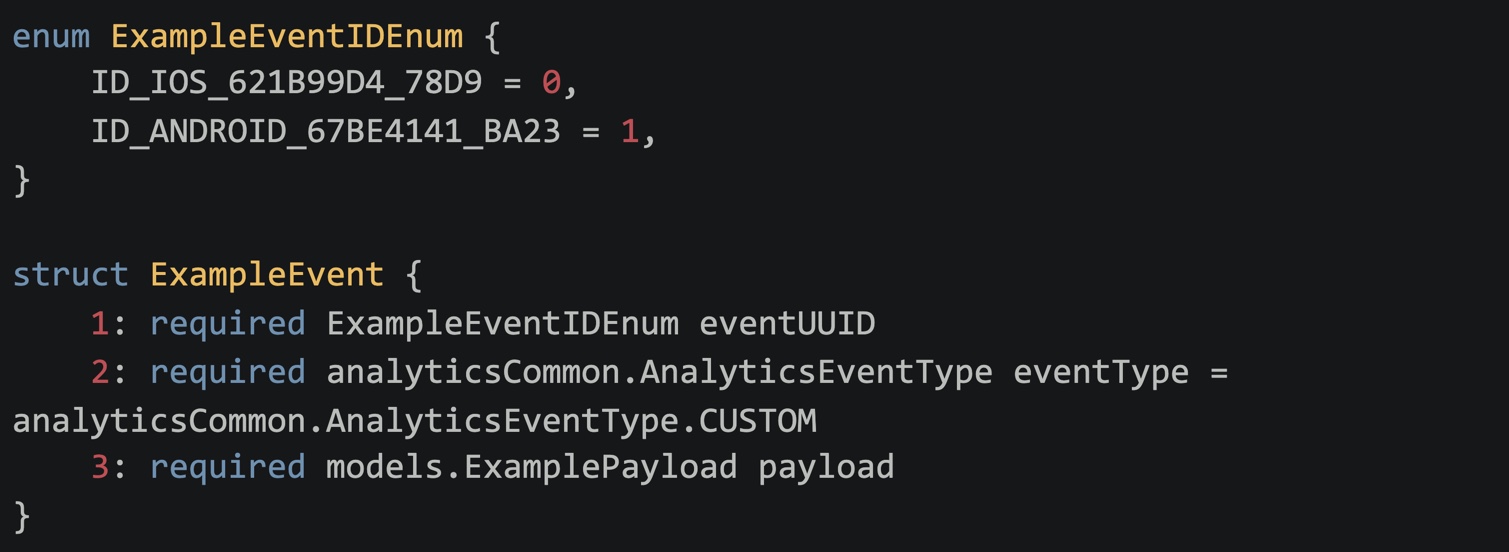
Publishing Logs
These logs are piped into Unified Reporter, a framework within the client for ingesting all the messages that the client produces. The Unified Reporter then stores messages in a queue, aggregates them, and sends them over the wire in a batched fashion every few seconds to the backend Event Processor.
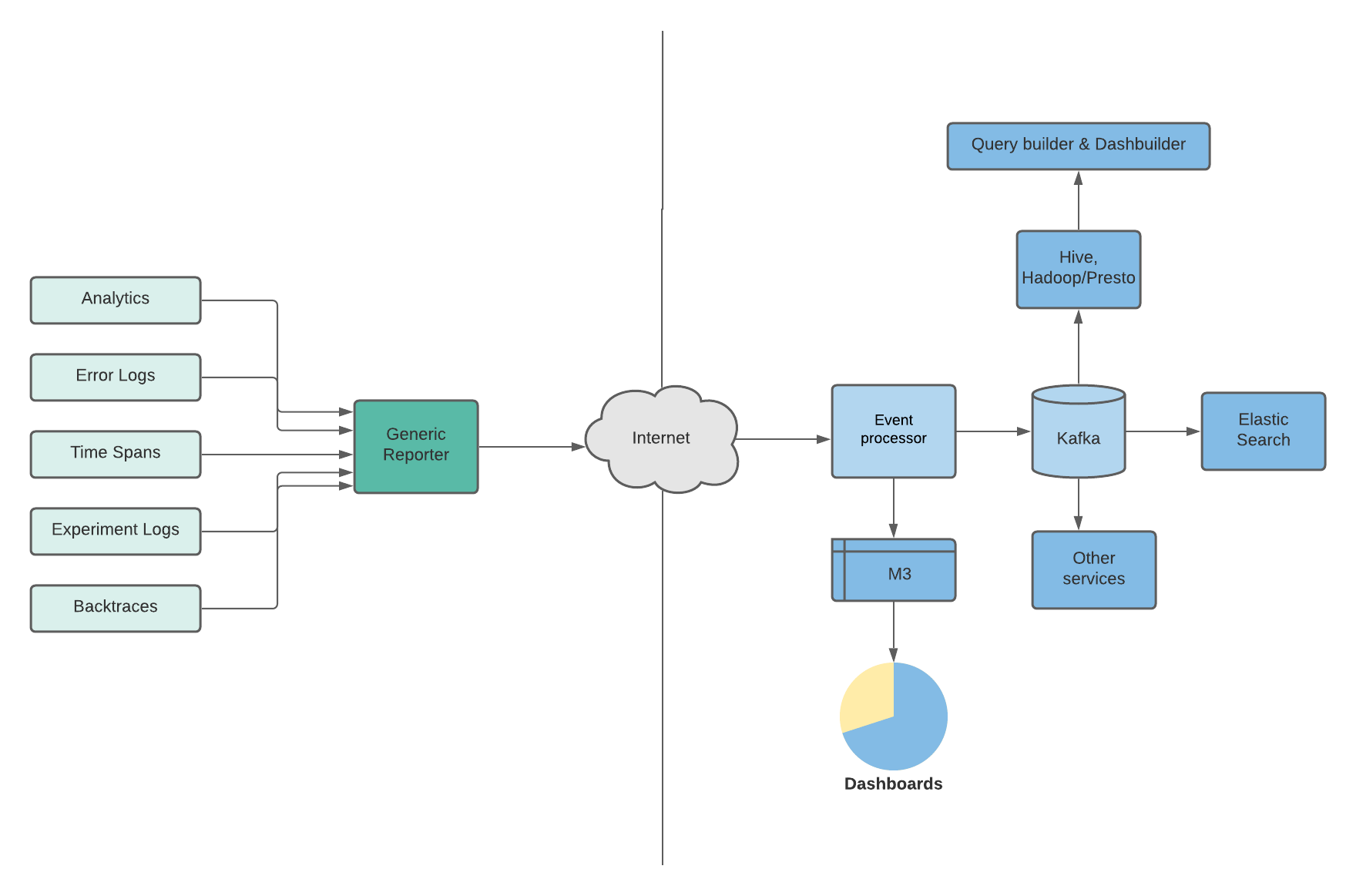
Events keep growing or changing—there are hundreds of types of events being processed today. Other problems of growing severity are platformization logs across different OS (Android and iOS), discoverability, and maintaining a good signal-to-noise ratio. The Event Manager portal is where metadata about these events are managed and appropriate sink for the events are chosen.
Based on the metadata, the Event Processor that receives the events decides how they need to be processed and propagated further. Event Processor also gates the events and doesn’t propagate the events downstream unless the metadata and mapping for that event are available. This is done in an effort to improve the signal-to-noise ratio.
Backend Event Logging
Along with user interactions, it is important to capture what is shown to the user in the app. This is done by logging data from the service layer at the backend. Backend logging handles more metadata, which is either not available for mobile or too much for a mobile phone to handle. Every backend call resulting from mobile or other systems logs the data. Each record logged has a ‘join’ key, with which it can be tied to the mobile interaction. This design also makes sure mobile bandwidth is efficiently used.
Offline Data Processing
Data collected from both the mobile and service layers is structured and copied over as offline datasets. Offline datasets help us to identify the problem areas from above, and measure the success of the solutions developed to address them.
Huge, raw, offline datasets are really hard to manage. Raw data gets enriched and modelled into tiered tables. In the process of enrichment, different datasets are joined together to make the data more meaningful. Modelled tables help in the following ways:
- Resources Saving: It is computed once and stored. Everyone else need not run their own queries on huge, raw data sets.
- Standardized Definition: Business logic and metric definition remains in ETL (Extract, Transform, and Load) and the consumer doesn’t need to worry about it. If left to the consumers, every team could compute it differently.
- Data Quality: Proper checks and balances can be maintained, as all the logic is in one place and the data is easily certified.
- Ownership: As the data evolves, owners can make sure the table is able to accommodate new features.
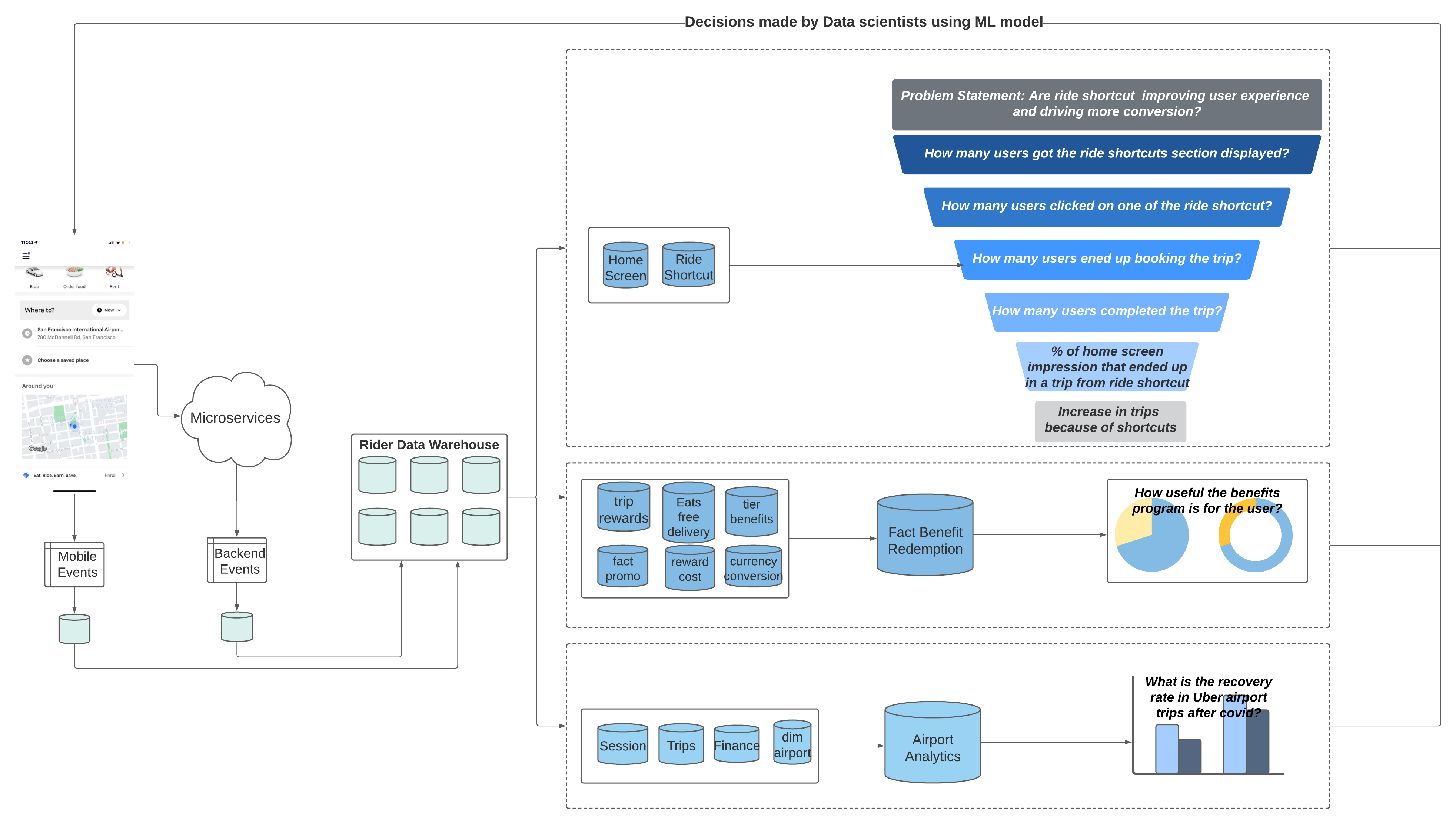
Let’s consider the following problem statements:
- Are ride shortcuts improving the rider experience and driving more conversion (trips)?
Base fact tables that capture user interaction and content of the home screen are filtered for ride shortcut-based information. It is enriched through integration with several other datasets, enabling funnel analysis:
-
-
- How many users had the rider shortcut section displayed?
- How many users clicked on one of the shortcuts?
- How many users (out of #2) ended up booking the trip?
- How many users (out of #3) completed the trip?
- What percentage of home screen impressions that ended up as completed trips in ride shortcut flow vs. usual flow?
- What was the overall effect on trip booking from ride shortcuts?
-
2. How useful is the rewards program for the rider?
In order to find an answer to this question, a table should capture the following data:
-
-
- Rewards selected/redeemed
- Rewards expired or not used
- How did the riders earn the reward?
-
And additional, interesting data points like:
-
-
- Does the rewards program increase overall app usage?
- Are the expenditures in line with the budget allocated for this program?
-
Rewards can be redeemed to benefit from different features across Eats, Rides, and other Uber apps. Once the user selects a benefit from their mobile, the centralized rewards backend service is invoked. It processes the rewards information and logs each reward selection as transaction data. Some of the benefits are auto-applied, but some are promo-driven. Promo-driven reward redemption is handled in a different, promo system. The system is also built such that Operations or Product teams are able to add new benefits easily as needed. We built our tools to capture the rewards metadata, which in turn flows into a different system. An ETL job reads data that flows across different systems to generate a model of benefit redemption data. In addition to providing a good understanding of the product, this data also aids the Finance teams in capturing Uber’s spend on Benefits.
3. What is the recovery rate in Uber airport trips after COVID-19?
-
-
- Different metrics for airports are collected from several upstream tables. It involves pulling from different domains like trips, sessions, finance, airport, and other rider tables. Data from different domains are aggregated and metrics are computed at a set of dimensions, and modelled into a table. Comparing the latest data with our aggregated historical data helps us to find an answer for the above problem.
- Airports data is also being used to plot a heatmap of drop-off data for airport pickups, computing total airport pick ups, gross booking etc., which are some of the other use cases. All of these data points help in evolving the business in general, as well as localizing it to meet the diverse needs of different locations.
-
Data Quality
Data provides signals that drive our business decisions. It thus becomes very important that data integrity and quality are maintained. In the end-to-end Rider architecture, we have several checks at various levels for ensuring data quality.
While producing the events, we include test frameworks to ensure that build-time tests, schema, and semantic checks are added. These frameworks check if analytic events are fired, with the expected payload and in the right order.
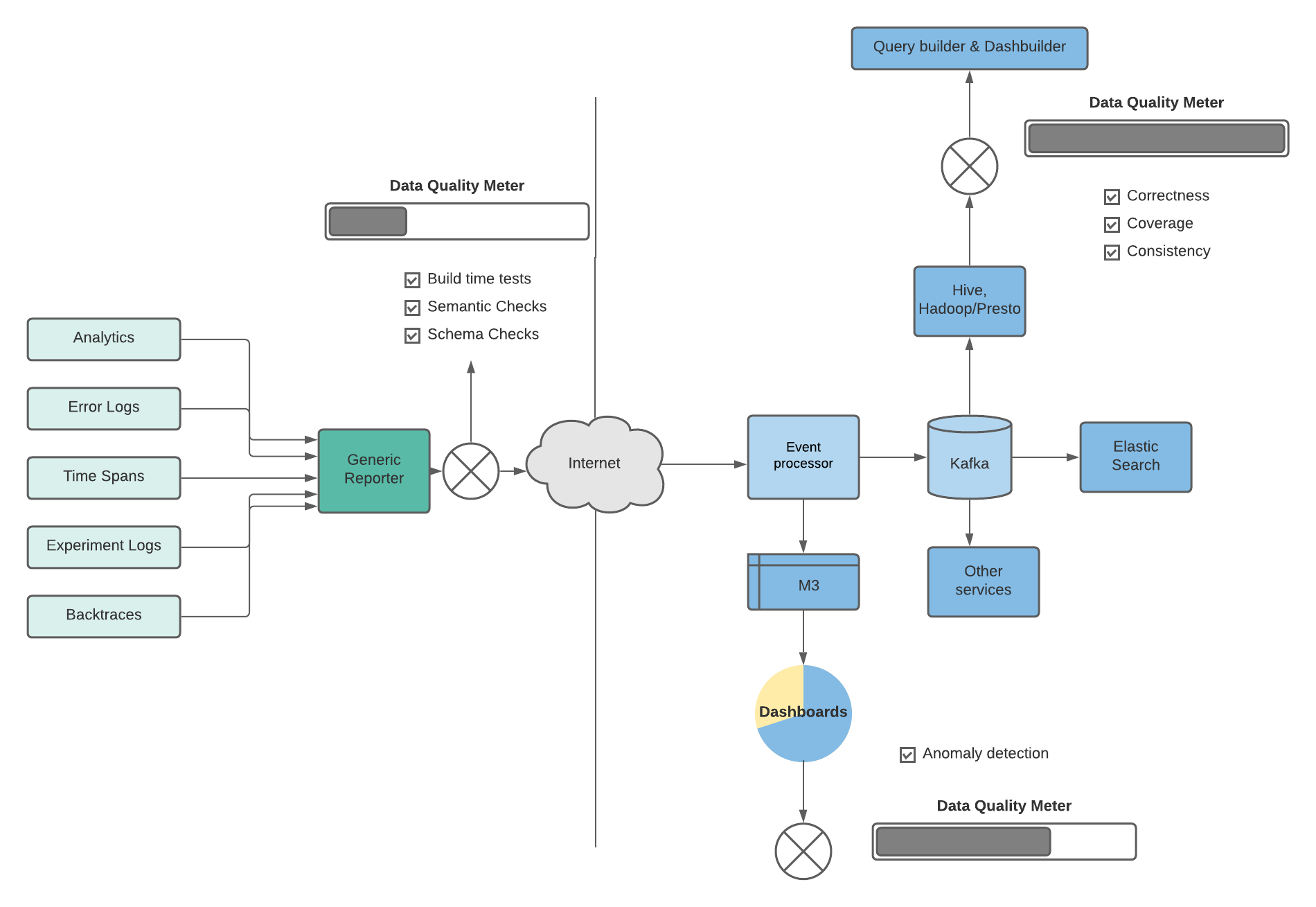
Once the events reach offline storage and processing, anomaly detection is added to make sure that the data is being logged and flowing as expected. The system monitors event volume, and alerts owners if there are sudden drops or spikes. This monitoring helps catch discrepancies and prevents missing silent outages. In offline modelled tables, testing frameworks are used to ensure data correctness, coverage, and consistency across various tables. Each run of the pipeline triggers the configured tests to make sure that any data produced is guaranteed for quality SLA (Service-Level Agreement).
Evolution of the Uber Rider App
Based on what we learned from the data collection mechanism described above, these are some of the examples of concrete changes to the Rider app, informed by our analytics:
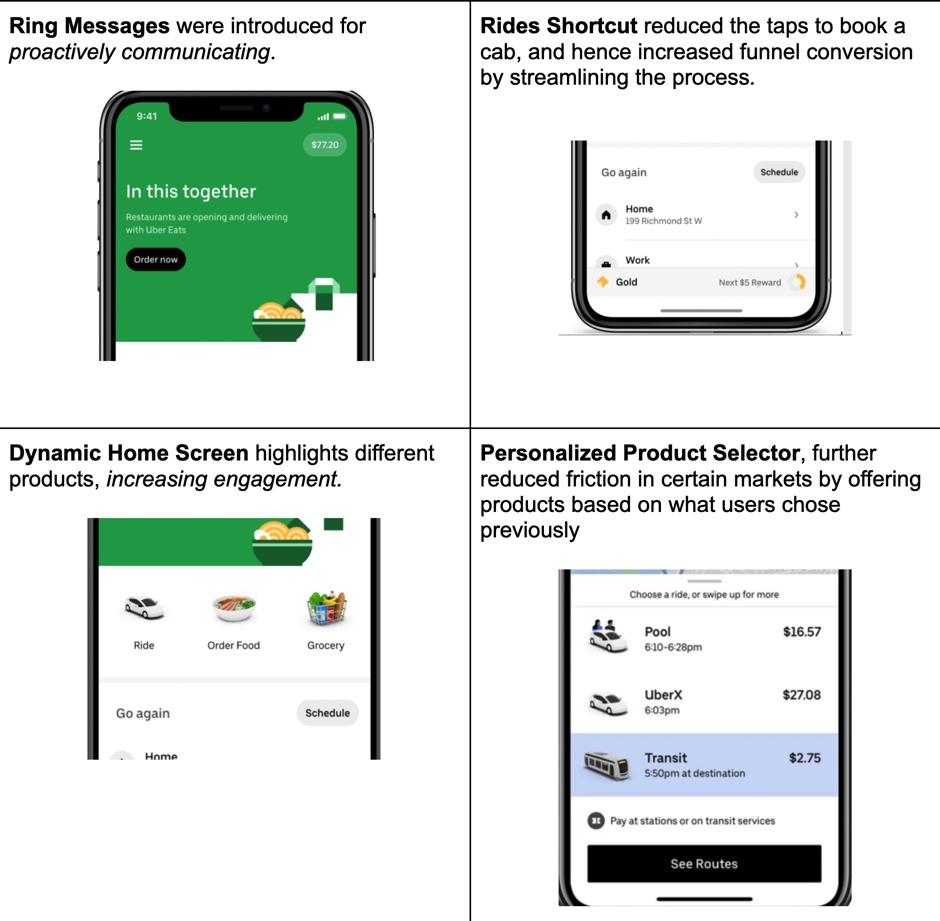
High-quality Data is a very powerful tool for shaping the application’s evolution. Among other things, it helps us improve the user experience, which in turn results in user retention and growth. Data is also the key to understanding what works best for users with respect to adding new features while ensuring that changes don’t degrade the user experience. We understand data’s importance, and are always focused on creating a better data culture at Uber.
Apache®, Apache Hive™, and Hive™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.

Divya Babu Ravichandran
Divya Babu Ravichandran is a Senior Software Engineer II on Uber’s Data Intelligence team, based in Bangalore, India. She is a data lead responsible for defining the architecture of various Source of Truth datasets used across Uber Rider, Driver, and Marketplace.

Varun Verma
Varun Verma is a Software Engineer II on Uber’s Data Intelligence team, based in Bangalore, India. He has worked on several projects for the Rider Mobile Platform team, and is currently working on solving data challenges at Uber.
Posted by Divya Babu Ravichandran, Varun Verma
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global



Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
