
Introduction
In 2017, we introduced Horovod, an open source framework for scaling deep learning training across hundreds of GPUs in parallel. At the time, most of the deep learning use cases at Uber were related to the research and development of self-driving vehicles, while in Michelangelo, the vast majority of production machine learning models were tree models based on XGBoost.
Now in 2021, the state of deep learning is changing. Increasingly, deep learning models are outperforming tree-based models for tabular data problems, and more deep learning models are moving from research to production. As a result, we’ve had to rethink our existing deep learning platform to accommodate for increasing demand and new requirements:
- Autoscaling and Fault Tolerance
- Hyperparameter Search
- Unified Compute Infrastructure
Autoscaling and Fault Tolerance
Our previous deep learning platform allocated a fixed-size Horovod cluster for training an individual model. When running on-premise, users would frequently find themselves unable to start large training jobs due to lack of resources. We provide the option to train in cloud data centers, but lack of autoscaling means running on dedicated instances, which are often 3-5x the cost of running on preemptible or “spot” instances.
Even when capacity is not a primary concern, fault tolerance often is. As jobs train for more epochs with more machines, the chance of failure increases. Frequent checkpointing can help mitigate this, but requires a lot of additional bespoke platform tooling to support.
Elastic Horovod
In Horovod v0.20, we introduced Elastic Horovod to allow distributed training that scales the number of workers dynamically throughout the training process. With a few lines of code added to an existing Horovod training script, jobs can now continue training with minimal interruption when machines come and go from the job.
From an API level of abstraction, Elastic Horovod solves the problem of autoscaling the training process, but does not operationalize it. We wrote Elastic Horovod to be generic of any particular orchestration system or cloud provider, which meant leaving the following components as interfaces to be implemented:
- Discovery of hosts that can be added to (or should be removed from) the training job
- Resource requests for additional workers as they become available and the job can make use of them
Our original assumption was that we would need to implement each of these interfaces within separate components for each major cloud provider (e.g., AWS, Azure, GCP) or orchestration system (e.g., Kubernetes, Peloton) we wanted to support for our internal and open source users.
As it turned out, there was already an open source solution to this problem of multi-cloud distributed computing: Ray.
Elastic Horovod on Ray
Ray is a distributed execution engine for parallel and distributed programming. Developed at UC Berkeley, Ray was initially built to scale out machine learning workloads and experiments with a simple class/function-based Python API.
Since its inception, the Ray ecosystem has grown to include a variety of features and tools useful for training ML models on the cloud, including Ray Tune for distributed hyperparameter tuning, the Ray Cluster Launcher for cluster provisioning, and load-based autoscaling. Now, Ray also integrates with a variety of machine learning libraries, such as RLLib, XGBoost and PyTorch.
With the new ElasticRayExecutor API, Horovod is able to leverage Ray to simplify the discovery and orchestration of the underlying hosts. To leverage Ray with Horovod for elastic training, you first need to start a Ray runtime consisting of multiple nodes (a Ray cluster)
Ray Runtime/Clusters: Ray programs are able to parallelize and distribute by leveraging an underlying Ray runtime. The Ray runtime can be started on one or multiple nodes, forming a Ray cluster.
Ray is bundled with a lightweight cluster launcher that simplifies the provision of a cluster on any cloud (AWS, Azure, GCP, or even cluster managers like Kubernetes and YARN.). The cluster launcher provisions clusters according to a given cluster configuration, like the example shown below:
To start a Ray cluster on AWS, you can simply save the above configuration as `cfg.yaml` and then call `ray up cfg.yaml`. In the above example, note that the head node is a CPU-only node, while the workers are GPU preemptible instances.
Further, Ray clusters can be configured to be “autoscaling”, meaning that Ray can transparently provision new nodes under different workload requirements. For example, if a Ray program needs a GPU in the middle of the application, Ray can provision a cheap GPU instance, run the Ray task or actor on the instance, then terminate the instance when finished.
You can check out the Ray documentation for an example of creating an autoscaling Ray program on AWS/GCP.
ElasticRayExecutor API: ElasticRayExecutor can leverage an autoscaling Ray cluster to simplify the discovery of hosts and request more resources when appropriate. To use this API, define a training function that includes a higher level function that uses Horovod Elastic state synchronization decorator:

You can then attach to the underlying Ray cluster and execute the training function:

In this example, the ElasticRayExecutor will create multiple GPU workers, each participating in a data-parallel training routine. The number of workers will be automatically determined by the number of GPU worker nodes in the cluster — meaning that training will not be stopped even when nodes are removed arbitrarily via pre-emption.
As you can see, the integration of Ray with Horovod results in a solution that simplifies the operation of running elastic training jobs with Horovod across major cloud providers.
Benchmarks and Experiments
One of the biggest unknowns for us when considering adopting elastic training was convergence. Specifically, we were unsure if there was a limit to how often and to what extent the job could be resized during training, Would we need to make any adjustments during training to smooth out the effects of scaling up and down the number of workers at runtime?
To measure the effects of adjusting the number of workers dynamically on model convergence, we ran three jobs training a ResNet50 model on the Cifar10 dataset using 8x v100 GPUs in AWS (p3.2xlarge instances) over a fixed number of 90 epochs. We adjusted the frequency with which the number of workers would be adjusted up and down, and how many workers would be added / removed at a time, across 3 experiment configurations:
- Fixed number of 8 GPU workers with no autoscaling (8gpu_fixed).
- Initial 8 GPU workers scaled up or down by 1 every 60 seconds (8gpu_60_1).
- Initial 8 GPU workers scaled up or down by 3 every 180 seconds (8gpu_180_3).
For every resize event, if the number of workers is already at the max (8) we always scale down, and if the number of workers is at the min (2) we always scale up. Otherwise, we randomly choose to increase or decrease the number of workers with equal probability.
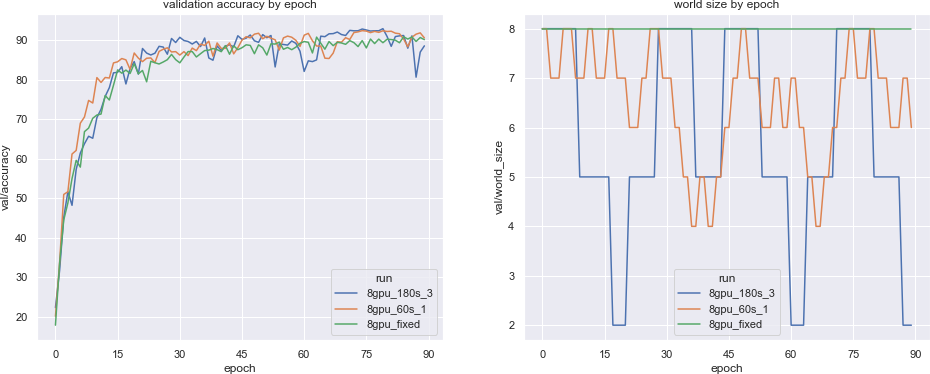
As shown in the results above, we observed that as we increased the magnitude of the resize events (measured by number of hosts added / removed at once) and decreased the frequency proportionately, the overall variance in the model performance between epochs increased, and actually improved overall model generalization against the baseline.
An additional benefit of elastic training is that it can even be used to reduce the overall variance in the training procedure when the timing of resize events can be controlled by the training process. As indicated by Smith et al. in Don’t Decay the Learning Rate, Increase the Batch Size, we can exploit the fact that increasing the batch size results in a simulated annealing effect that moves the model training from an exploration phase during the earlier epochs into an exploitation phase towards the end.
In practice, this procedure of periodically scaling up the batch size by increasing the number of workers allows the model to train to convergence in much less wall clock time, often with higher generalization accuracy, than keeping with the initial number of workers for the duration of training.
To illustrate this effect, we ran an additional set of experiments: repeating the training procedure above but with two new configurations:
- Fixed number of 2 GPU workers (2gpu_fixed)
- Dynamic number of workers that doubles every 30 epochs, starting at 2 and ending with 8 workers (8gpu_exp).
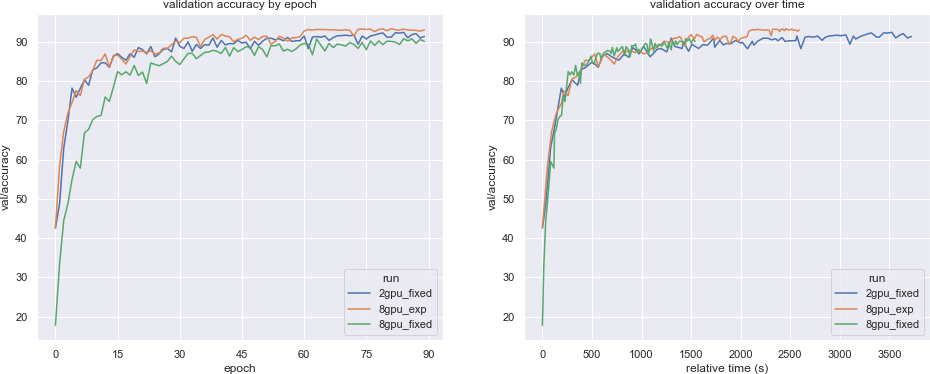
As expected, decreasing the number of workers from 8 to 2 improved the overall model convergence. This reveals one of the common pitfalls of data parallel distributed training when the model has been tuned for a smaller batch size. In practice, it’s recommended to use techniques like learning rate warmup / decay, Hyperparameter Search (see below), and Adasum to offset these effects.
Another solution to achieve good convergence with high amounts of parallelism is illustrated by the third experiment shown above: scaling the parallelism up over time. Not only did this approach complete in less total wall clock time than the 2 GPU baseline, it did so with higher validation accuracy!
The intuition behind this, as explained in the aforementioned paper by Smith et al, is that the training process benefits from moving from an “exploration” phase in the beginning to an “exploitation” phase towards the end. Increasing the parallelism has the effect of increasing the batch size, which helps smooth out the variance between the training examples, leading to less exploration in the later stages of training.
Adding this capability to Elastic Horovod on Ray can be done using Horovod on Ray’s Callback API:

These callbacks can also be used to simplify other aspects of training, including logging and metrics tracking, by forwarding messages from the workers to the driver.
Where this approach has the potential to provide the greatest improvement is when combined with hyperparameter search. Similar to the simulated annealing comparison for scaling the batch size, many modern hyperparameter search algorithms also follow an explore / exploit paradigm that can be combined with elastic training to both achieve optimal model performance and optimal resource utilization.
Hyperparameter Search
In the process of developing deep learning models, users often need to re-tune hyperparameters when training at scale, as many hyperparameters exhibit different behaviors at larger scales. This is even more true when training in an auto-scaling cluster, as there are additional hyperparameters to consider that can affect training throughput, convergence, and cost, including:
- How frequently to increase the maximum number of workers / effective batch size
- How frequently to commit shared worker state to achieve the greatest number of epochs in the least amount of time
- How many workers we allow to enter / remove the job at once
Tuning hyperparameters at scale with Horovod can often be a bit tricky. Executing a parallel hyperparameter search would require a separate higher level system to orchestrate and schedule the multi-node Horovod training jobs over the available resources. The AutoTune service supported within Michelangelo addresses some of the fundamental challenges of orchestrating long running hyperparameter search jobs, but does not support the kinds of population-based training and early stopping strategies that would allow us to reallocate GPU resources to speed up the best performing trials.
Ray is built with support for nested parallelism — this means that it is able to easily handle a distributed program that launches tasks that are themselves distributed. Taking advantage of this, we‘ve developed a Horovod + Ray Tune integration to enable parallel hyperparameter tuning with distributed training.
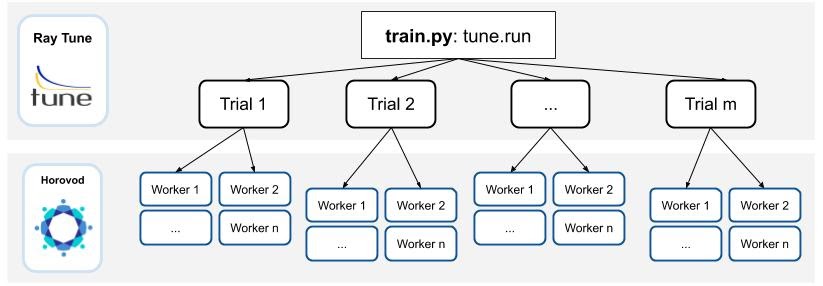
Ray Tune is a popular hyperparameter tuning library bundled with Ray. Ray Tune includes the latest hyperparameter search algorithms (such as population-based training, Bayesian optimization, and hyperband) and also supports failure handling, so users can better leverage the tradeoff of model performance to cloud costs to do hyperparameter tuning.
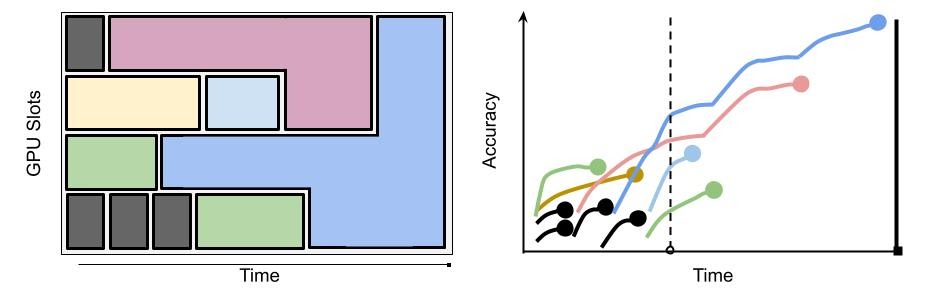
As demonstrated by Liaw et al in HyperSched: Dynamic Resource Reallocation for Model Development on a Deadline, combining hyperparameter search with distributed training in this way can enable us to optimize for finding the best model given a fixed amount of time and compute resources. This is particularly useful to an organization like ours at Uber, where most training occurs on fixed-size on-premise GPU clusters.
Next Steps: Unifying Compute Infrastructure for Machine Learning and Deep Learning
Our early results from integrating Elastic Horovod with Ray and Ray Tune have demonstrated the flexibility and ease of use of Ray as a means of scripting complex distributed compute systems together into a unified workflow.
In addition to the previous challenges we discussed, machine learning platforms often need to integrate several different technologies such as SparkML, XGBoost, SKLearn and RLlib etc. These different technologies run on different compute platforms. For example, at Uber, the ML workload can run on general containerized compute infra (Peloton, Kubernetes), Spark (YARN, Peloton), and Ray (Peloton, Kubernetes), etc. As a result, a production ML pipeline is often broken into distinct tasks and orchestrated by a pipeline orchestrator such as Airflow or Kubeflow Pipelines. This increases the software and operational complexity of the platform.
In the past, we’ve invested in creating bespoke systems to provision and run deep learning workflows, but with a number of disadvantages in comparison to Horovod on Ray:
- Extensibility: Because internal systems were designed for specific applications, and not general computing, adding support for frameworks like Elastic Horovod requires major rearchitecting of the code base, and implementing a custom autoscaler similar to the one provided by Ray.
- Flexibility: Systems built to run distributed deep learning cannot be easily adapted to run other workloads, such as data processing (Dask, Modin), hyperparameter search (Ray Tune), or reinforcement learning (RLlib).
- Maintenance: Unlike open-source systems like Ray, our internal deep learning infrastructure must be maintained by a dedicated group of engineers, whose time and energy could instead be put into solving higher-level problems.
By consolidating more of the deep learning stack on Ray, we can further optimize more of the end-to-end within the deep learning workflow. For example, currently there exists a sharp boundary between feature engineering (Apache Spark) and distributed training (Horovod). For each stage of the workflow, we must provision separate compute infrastructure that must be operationalized independently, and materialize the output of the Spark process to disk so it can be consumed by the Horovod process. This is not only difficult to maintain, but equally difficult to replace if we wish to explore alternative frameworks for different stages of the workflow.
Being able to swap in and out different distributed frameworks is one of the core advantages of Ray. Because Ray is a general distributed compute platform, users of Ray are free to choose among a growing number of distributed data processing frameworks, including Spark, running on the same resources provisioned by Ray for the deep learning workflow. This simplifies the compute infrastructure because there is no longer the aforementioned sharp boundary between Spark and Horovod workload. In practice, different frameworks are optimized for different workloads depending on data volume, compute intensity, and available cluster resources. Furthermore, some frameworks are easier to integrate into existing projects than others.
One such project we’re enhancing with these capabilities is Ludwig, an open source deep learning AutoML framework developed by Uber.
In the past, Ludwig has been limited to processing datasets that fit within the memory of a single machine, due to its reliance on the Pandas framework for data processing. Now in the upcoming Ludwig 0.4 release, we’re integrating Dask on Ray for distributed out-of-memory data preprocessing, Horovod on Ray for distributed training, and Ray Tune for hyperparameter optimization.
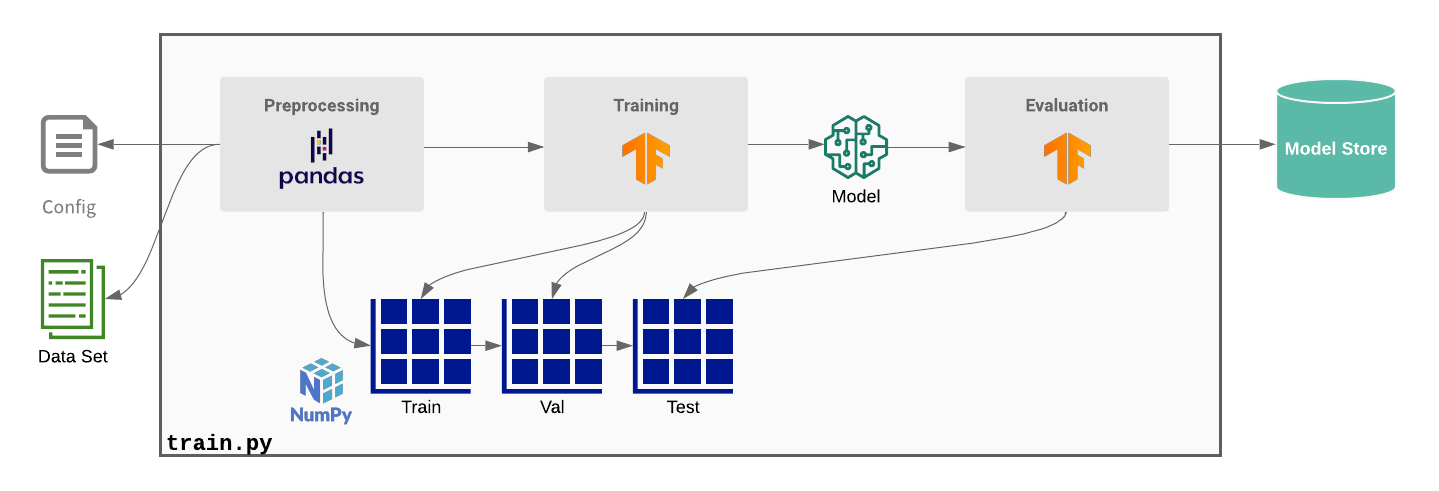
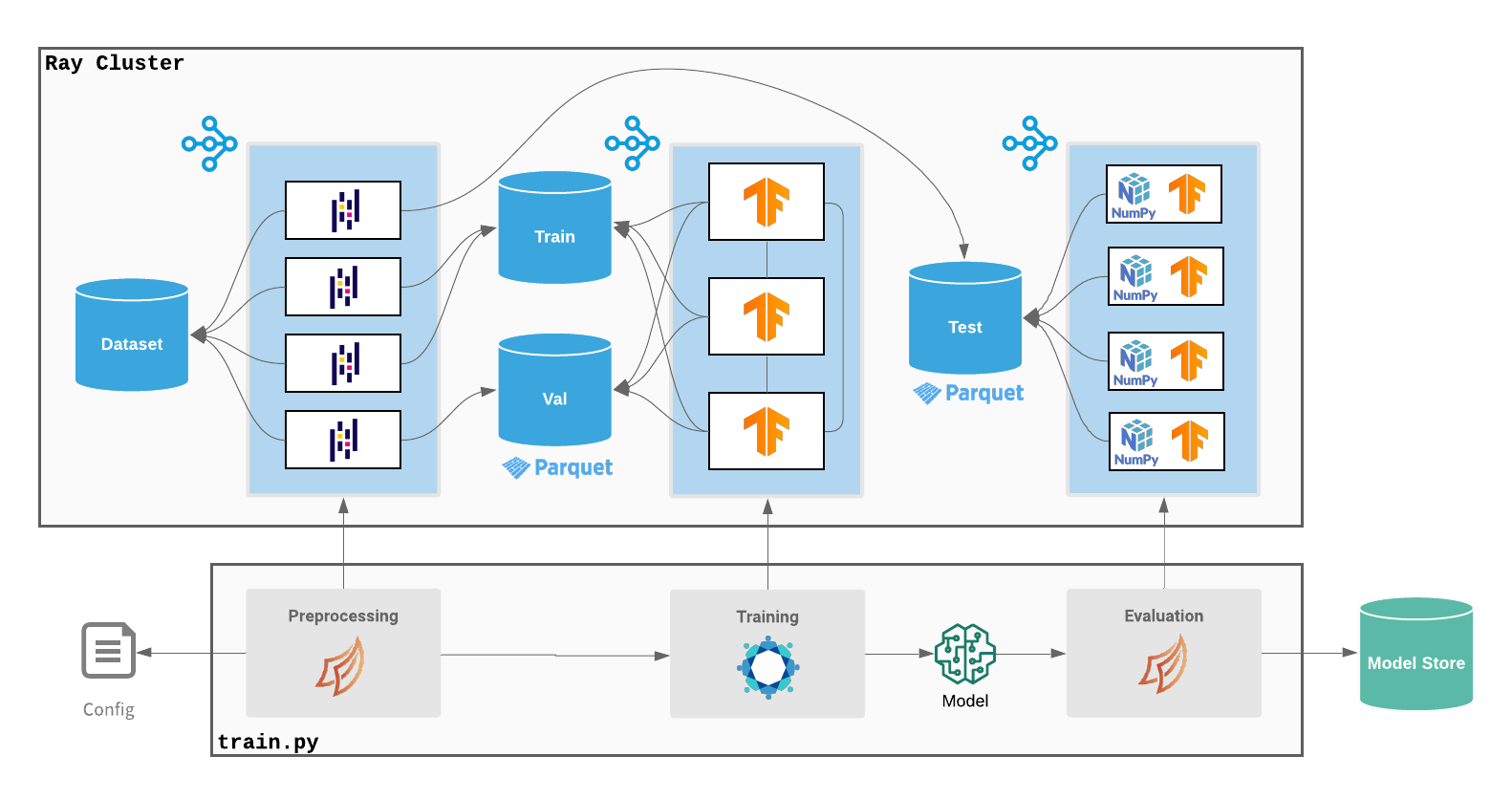
By leveraging Dask, Ludwig’s existing Pandas preprocessing can be scaled to handle large datasets with minimal code changes, and by leveraging Ray, we can combine the preprocessing, distributed training, and hyperparameter search all within a single job running a single training script.
For Ludwig users, these capabilities are provided with zero code changes or additional infrastructure provisioning beyond adding `ray submit` and `–backend ray` to the command line:

We believe that Ray will continue to play an increasingly important role in bringing much needed common infrastructure and standardization to the production machine learning ecosystem, both within Uber and the industry at large. In the months ahead, we’ll share more about our efforts to bring Ray’s capabilities to Uber’s deep learning platform. In the meantime, check out Elastic Horovod on Ray and feel free to reach out with any questions, comments, or contributions.
Acknowledgements
We’d like to acknowledge the work of the following individuals:
- Richard Liaw and the Anyscale team for their efforts on integrating Horovod with Ray, including Horovod in Ray Tune, and their continued support of integrating Ray at Uber
- Fardin Abdi and Qiyan Zhang for their work on integrating Elastic Horovod with Peloton
- Enrico Minack from G-Research for his work on Elastic Horovod and its integration with Horovod on Spark
- Yi Wang for his work on ElasticDL integrating and benchmarking Elastic Horovod
- The authors of https://github.com/kuangliu/pytorch-cifar for providing the PyTorch model definitions used to train the models
We would also like to thank all of our Horovod contributors without whom this work would not have been possible, the Linux Foundation for continuing to support the Horovod project, and AWS for providing credits to support our continuous integration system.

Travis Addair
Travis Addair is a software engineer at Uber AI leading the Deep Learning Training team as part of the Michelangelo AI platform. He leads the Horovod open source project and chairs its Technical Steering Committee within the Linux Foundation.

Xu Ning
Xu Ning is a Senior Engineering Manager in Uber’s Seattle Engineering office, currently leading multiple development teams in Uber’s Michelangelo Machine Learning Platform. He previously led Uber's Cherami distributed task queue, Hadoop observability, and Data security teams.

Richard Liaw
Richard Liaw is a Software Engineer at Anyscale, where he currently leads development efforts for distributed Machine Learning libraries on Ray. He is one of the maintainers of the open source Ray project and is on leave from the PhD program at UC Berkeley.
Posted by Travis Addair, Xu Ning, Richard Liaw
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global




Most popular
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Palette Meta Store Journey

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
