Horovod Adds Support for PySpark and Apache MXNet and Additional Features for Faster Training
February 21, 2019 / Global
This article was originally published on The LF Deep Learning Foundation Blog.
Horovod, a distributed deep learning framework created by Uber, makes distributed deep learning fast and easy-to-use. Horovod improves the speed, scale, and resource allocation for training machine learning (ML) models with TensorFlow, Keras, PyTorch, and Apache MXNet. LF Deep Learning, a Linux Foundation project which supports and sustains open source innovation in artificial intelligence and machine learning, accepted Horovod as one of its hosted projects in December 2018. Since the project was accepted as a hosted, additional contributions and collaboration beyond Uber immediately occurred due to LF Deep Learning’s neutral environment, open governance and set of enablers that the foundation offered the project.
The updates in this latest release improve Horovod in three key ways: adding support and integration for more frameworks, improving existing features, and preparing the framework for changes coming with TensorFlow 2.0. Combined, these new functionalities and capabilities make Horovod easier, faster, and more versatile for its growing base of users, including NVIDIA and the Oak Ridge National Laboratory. Horovod has also been integrated with various deep learning ecosystems, including AWS, Google, Azure, and IBM Watson.
With this release, a number of new use cases for Horovod have been added with the purpose of making the framework a more versatile tool for training deep learning models. As the list of integrations and supported frameworks grows, users can leverage Horovod to accelerate a larger number of open source models, and use the same techniques across multiple frameworks.
PySpark and Petastorm support
Capable of handling a massive volume of data, Apache Spark is used across many machine learning environments. The ease-of-use, in-memory processing capabilities, near real-time analytics, and rich set of integration options, like Spark MLlib and Spark SQL, has made Spark a popular choice.
Given its scalability and ease-of-use, Horovod has received interest from broader, Python-based machine learning communities, including Apache Spark. With the release of PySpark support and integration, Horovod becomes useful to a wider set of users.
A typical workflow for PySpark before Horovod was to do data preparation in PySpark, save the results in the intermediate storage, run a different deep learning training job using a different cluster solution, export the trained model, and run evaluation in PySpark. Horovod’s integration with PySpark allows performing all these steps in the same environment.

In order to smooth out data transfer between PySpark and Horovod in Spark clusters, Horovod relies on Petastorm, an open source data access library for deep learning developed by Uber Advanced Technologies Group (ATG). Petastorm, open sourced in September 2018, enables single machine or distributed training and evaluation of deep learning models directly from multi-terabyte datasets.
A typical Petastorm use case entails preprocessing the data in PySpark, writing it out to storage in Apache Parquet, a highly efficient columnar storage format, and reading the data in TensorFlow or PyTorch using Petastorm.
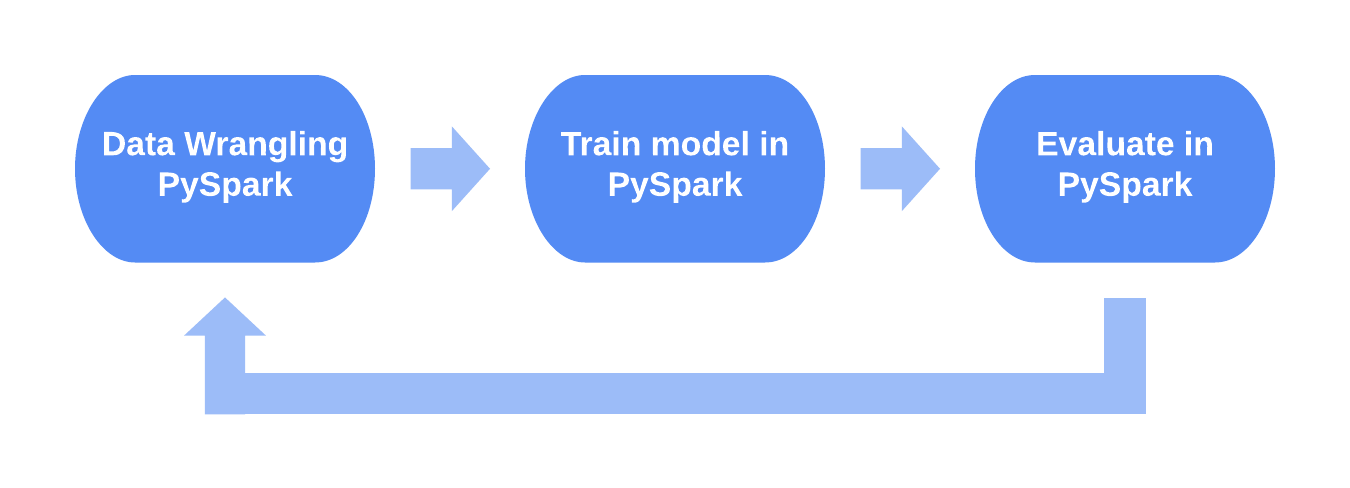
Both Apache Spark and Petastorm are also used in some applications internally at Uber, so extending Horovod’s support to include PySpark and Petastorm has been a natural step in the process of making Horovod a more versatile tool.
Apache MXNet support
Apache MXNet (incubating) is an open source deep learning framework that facilitates more flexible and efficient neural network training. Amazon is a large contributor to both Horovod and MXNet, and natively supports both frameworks on Amazon EC2 P3 instances and Amazon SageMaker.
Like its recent support of PySpark, Horovod’s integration with MXNet is part of a larger effort to make Horovod available to a broader community, further expanding access to faster and easier model training.
Autotuning
The third update in this latest release is Horovod’s introduction of an alpha version of autotuning. In this release, autotuning is optional, but it will be turned on as default in future releases.
Horovod supports a number of internal parameters that can be adjusted to improve performance for variations in hardware and model architecture. Such parameters include the fusion buffer threshold for determining how many tensors can be batched together into a single allreduce, cycle time for controlling the frequency of allreduce batches, and hierarchical allreduce as an alternative to single-ring allreduce when the number of hosts becomes very large.
Finding the right values for these parameters can yield performance improvements as much as 30 percent. However, trying different parameters by hand is a time-consuming exercise in trial-and-error.
Horovod’s autotuning system removes the guesswork by dynamically exploring and selecting the best internal parameter values using Bayesian optimization.
Autotuning automates the otherwise manual process of trying different options and parameter values to identify the best configuration, which must be repeated if there are changes in hardware, scale, or models. Courtesy of automation, autotuning makes parameter optimization more efficient for faster model training.
Embedding improvements
Embedding is commonly used in machine learning use cases involving natural language processing (NLP) and learning from tabular data. At Uber’s datastore, Uber trips data is stored as tabular data which have some categorical bounds. In a use case like Uber’s, the number of embeddings and the size of embeddings will scale. With this latest release, Horovod has enhanced its capability of scaling deep learning models that make heavy use of embeddings, such as Transformer and BERT.
In addition, these embedding improvements facilitate large embedding gradients faster as well as the fusion of small embedding gradients, allowing for a larger number of embeddings to process operations faster.
Eager execution support in TensorFlow
Eager execution will be the default mode in TensorFlow 2.0. Eager execution allows developers to create models in an imperative programming environment, where operations are evaluated immediately, and the result is returned as real values. Eager execution eliminates the need to create sessions and work with graphs.
With eager execution’s support for dynamic models, model evaluation and debugging is made easier and faster. Eager execution also makes working with TensorFlow more intuitive for less experienced developers.
In the past, running Horovod with eager execution meant calculating each tensor gradient across all workers sequentially, without any tensor batching or parallelism. With the latest release, eager execution is fully supported. Tensor batching with eager execution improved performance by over 6x in our experiments. Additionally, users can now make use of a distributed implementation of TensorFlow’s GradientTape to record operations for automatic differentiation.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Using precision lower than FP32 reduces memory requirements by using smaller tensors, allowing deployment of larger networks. In addition, data transfers take less time, and compute performance increases dramatically. GPUs with Tensor Cores support mixed precision and enable users to capitalize on the benefits of lower memory usage and faster data transfers.
Mixed precision training of deep neural networks achieves two main objectives:
- Decreases the required amount of memory, enabling training of larger models or training with larger mini-batches
- Shortens the training or inference time by reducing the required resources by using lower-precision arithmetic.
In the past, mixed precision training used to break Horovod’s fusion logic, since the sequence of FP16 tensors would be frequently broken by FP32 tensors, and tensors of different precisions could not participate in a single fusion transaction.
With the latest release, NVIDIA contributed an improvement to tensor fusion logic that allows FP16 and FP32 tensor sequences to be processed independently via a look-ahead mechanism. We have seen up to 26 percent performance improvement with this change.
Curious about how Horovod can make your model training faster and more scalable? Check out these new updates and try out the framework for yourself, and be sure to join the Deep Learning Foundation’s Horovod announcement and technical discussion mailing lists.

Carsten Jacobsen
Carsten Jacobsen is an open source developer advocate at Uber.
Posted by Carsten Jacobsen
Related articles





Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
