Uber Case Study: Choosing the Right HDFS File Format for Your Apache Spark Jobs
March 21, 2019 / Global
As part of our effort to create better user experiences on our platform, members of our Maps Data Collection team use a dedicated mobile application to collect imagery and its associated metadata to enhance our maps. For example, our team captures images of street signs to improve the efficiency and quality of our maps data in order to facilitate a more seamless trip experience for both riders and driver-partners, as well as take pictures of food items to be displayed within the Uber Eats app. We then processes imagery and metadata via a series of Apache Spark jobs and stores the results in our Hadoop Distributed File System (HDFS) instance.
One of the Maps Data Collection team’s largest projects required ingesting and processing over eight billion images. The images needed to be efficiently accessed by downstream Apache Spark jobs as well as randomly accessed by operators responsible for map edits. While the design choices we made for our Apache Spark architecture required us to handle billions of images, the resulting pattern has also been applied to projects with a significantly smaller scale of thousands of images.
Apache Spark supports a number of file formats that allow multiple records to be stored in a single file. Each file format has its own advantages and disadvantages.
In this article, we outline the file formats the Maps Data Collection team uses to process large volumes of imagery and metadata in order to optimize the experience for downstream consumers. We hope you find these takeaways useful for your own data analytics needs.
Using Apache Spark with HDFS
Imagery and metadata are collected with a dedicated mobile application developed by Uber. Once the data is captured, the mobile application uploads the data to cloud storage. The imagery and metadata is ingested from cloud storage into Uber data centers and then processed:
- Ingest: Stages the raw data into the data center so it can be processed in parallel.
- Process/transform: A series of steps that unpacks the raw data and performs processing to refine the data into useful information for downstream consumers.
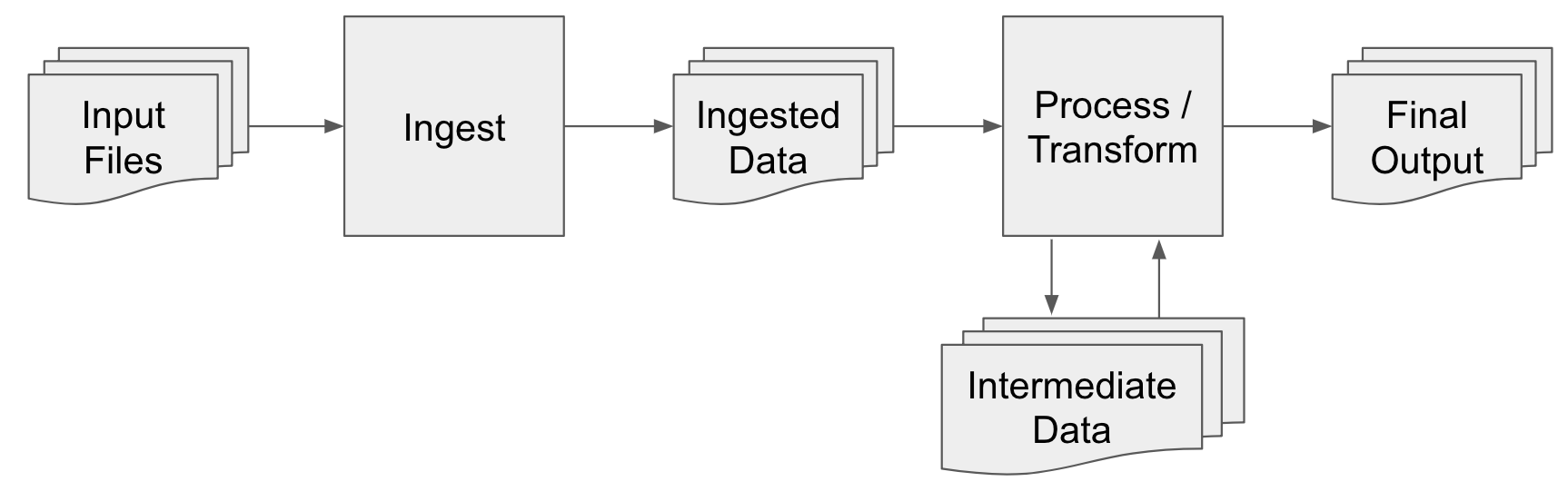
The following file formats are used for each output type.
- Ingested data: SequenceFiles provide efficient writes for blob data.
- Intermediate data: Avro offers rich schema support and more efficient writes than Parquet, especially for blob data.
- Final output: Combination of Parquet, Avro, and JSON files
- Imagery metadata: Parquet is optimized for efficient queries and filtering.
- Imagery: Avro is better optimized for binary data than Parquet and supports random access for efficient joins.
- Aggregated metadata: JSON is efficient for small record counts distributed across a large number of files and is easier to debug than binary file formats.
Each file format has pros and cons and each output type needs to support a unique set of use-cases. For each output type, we chose the file format that maximizes the pros and minimizes the cons. In the following sections, we explain why each file format was chosen for each format type.
Ingested data
Ingestion is the process by which the data recorded by an Uber-developed mobile phone app is efficiently moved into the data center for further processing. Ingest reads from an external source and writes the data to HDFS so that the files can be efficiently processed via Spark jobs. Storage of a small number of large files is preferred over a large number of small files in HDFS as it consumes less memory resources on the NameNodes and improves the efficiency of the Spark jobs responsible for processing the files. (If you are interested in learning more about this topic, we recommend checking out this article on the Cloudera Engineering Blog).
During ingestion, the contents of the files are unaltered so that additional processing and transformations may be done in parallel via Spark. The Spark jobs, which are responsible for processing and transformations, read the data in its entirety and do little to no filtering. Therefore, a simple file format is used that provides optimal write performance and does not have the overhead of schema-centric file formats such as Apache Avro and Apache Parquet.
Each instance of ingest writes the files into a single HDFS SequenceFile, resulting in a few large files which is optimal for HDFS. A SequenceFile is a flat file that consists of binary key/value pairs. The API allows the data to be stored in either a binary key or another data type such as string or integer. In the case of ingest, the key is a string that contains the full path to the file and the value is a binary array that contains the contents of the ingested file.
Intermediate data
Once the data is ingested, a series of Spark jobs transforms and performs additional processing on the data. Each Spark job within the series writes intermediate data. Intermediate data generated by a previous task is most often read in its entirety and is filtered by neither columns nor rows. For this type of intermediate data, we generally use the Avro file format.
Spark’s default file format is Parquet. Parquet has a number of advantages that improves the performance of querying and filtering the data. However, these advantages come with an upfront cost when the files are written. Parquet is a columnar-based file format, which means that all the values for a given column across all rows stored in a physical file (otherwise known as a block) are grouped together before they are written to disk. Thus, all the records need to be stored and rearranged in memory before the block is written. In contrast, an Avro file is a record based file format which enables records to be more efficiently streamed to disk. (The Parquet web site has a series of recorded presentations that provide more comprehensive explanations of columnar-based file formats.)
Due to the lower write overhead, Avro files are generally used to store intermediate data when:
- The data is written once and read once.
- The reader does not filter the data.
- The reader reads the data sequentially.
Final output
The final output is the processed data and is accessed by multiple downstream consumers. Each consumer has unique requirements that are often addressed by querying and filtering the data. For example, a consumer may perform a geospatial query on imagery of a particular type. The final output falls into three categories:
- Imagery metadata: Data about the imagery such as the location from which it was taken.
- Imagery: The images captured by the sensor.
- Aggregated data: High-level data about a set of imagery such as the version of the software used to process the imagery or aggregate metrics about the output data.
Imagery metadata
Unlike intermediate data, imagery metadata is read multiple times and often filtered and queried. The data is stored in Parquet because the benefits significantly outweigh the additional write overhead. Below are the results of two performance tests that queried approximately five million records.
The first query is a simple bounding box query on the latitude and longitude of the imagery that returns approximately 250,000 records. From the perspective of the downstream consumer, the Parquet query is almost three times faster to execute. However the real impact is on the underlying infrastructure.
The largest improvement is the I/O required for the queries where Parquet consumes 7.5 percent of the I/O required by the Avro query. The Parquet file format stores statistics that significantly reduce the amount of data read.
| Resource | Avro | Parquet | Improvement |
| Wall Time (sec) | 20.76 | 7.17 | 290% |
| Core Time (min) | 24.80 | 1.28 | 1,938% |
| Reads (MB) | 24,678.4 | 1,848.5 | 1,335% |
The second query is a string comparison that returns approximately 40,000 records. Once again, the query against Parquet files performed significantly better than against Avro files. The Parquet query executes two times faster and requires 1.5 percent of the I/O versus the equivalent Avro query.
| Resource | Avro | Parquet | Improvement |
| Wall Time (sec) | 18.48 | 6.0 | 308% |
| Core Time (min) | 1670.00 | 50.76 | 3,289% |
| Reads (MB) | 24,678.4 | 376.6 | 6,552% |
Imagery
Parquet is not optimal for storing large binary data such as imagery as it is a resource-intensive process to arrange large binary data in a columnar format. On the other hand, Avro works quite well for storing imagery. As discussed in the previous section, however, Avro is not optimal for queries.
In order to support queries, two columns are added to the imagery metadata Parquet files to serve as a foreign key to the imagery. This allows clients to query the imagery via the metadata.
Two key details need to be covered to understand how the cross-reference is implemented:
- Part File: Spark subdivides data into partitions and when the data is written to Avro each partition is written to a separate part file.
- Record Offset: The Avro API supports the ability to obtain the offset into a file where a specific record is stored. Given an offset, the Avro API can efficiently seek to the file location and read the record. This functionality is available via the native Avro API and not via the Spark wrapper API for Avro.
The two columns appended to the imagery metadata used as the cross-reference to the imagery are the name of the part file in which the image record is stored and the file offset of the record within the part file. Since the Spark wrapper API for Avro files does not expose the record offset, the native Avro API must be used to write the imagery.
Imagery is written within a Spark map. The implementation will vary depending on the version of Spark and whether the DataFrame or Resilient Distributed Dataset APIs are used, but the concept is the same. Execute a method on each partition via a Spark map call and use the native Avro API to write an individual part file that contains all imagery contained within the partition. The general steps are as follows:
- Read the ingest SequenceFile.
- Map each partition of the ingest SequenceFile and pass the partition id to the map function. For an RDD, call rdd.mapPartitionsWithIndex(). For a DataFrame, you can obtain the partition id via spark_partition_id(), group by partition id via df.groupByKey(), and then call df.flatMapGroups().
- Within the map function do the following:
- Create a standard Avro Writer (not Spark) and include the partition id within the file name.
- Iterate through each record of the ingest SequenceFile and write records to the Avro file.
- Call DataFileWriter.sync() within the Avro API. This will flush the record to disk and return the offset of the record.
- Pass both the file name and record offset via the return value of the map function along with any additional metadata you would like to extract from the imagery.
- Save the resulting DataFrame or RDD to Parquet format.
The results are an Avro and a companion Parquet file. The Avro file contains the imagery and the companion Parquet file contains the Avro file path and record offset to efficiently perform a seek on the Avro file for a given image record. The general pattern for querying and then reading the imagery records is to:
- Query the Parquet files.
- Include the file path and offset in the results.
- Optionally repartition the results to tune the degree of parallelism for reading the image records.
- Map each partition of the query results.
- Within the map function do the following:
- Create a standard Avro reader for the Avro part file that contains the image record.
- Call DataFileReader.seek(long) to read the image record at the specified offset.
Aggregated data
In addition to metadata for a given image, it is useful for us to store aggregated metadata about the entire set of imagery stored in a given Avro and Parquet file pair. For Uber’s use case, examples of aggregated metadata include both:
- The version of the pipeline used to process a given set of imagery. If a bug is found in the pipeline, this data is used to efficiently identify the imagery that needs to be reprocessed.
- The geographic area in which the imagery was collected. This allows clients to identify which Avro and Parquet file pairs to include in geospatial searches.
Aggregated data is stored in JSON files for the following reasons:
- Debuggability: Since the JSON files are formatted text and typically contain a small number of records, they can be easily displayed without code or special tooling.
- “Efficient Enough” Reads: In many cases, the JSON file will contain a single record for a given Avro and Parquet pair. Both Parquet and Avro have overhead because both file formats contain header information. JSON does not have this overhead because of the formats’ lack of header information.
- Referential Integrity: An alternative would be to store the aggregated records in a database. However if the JSON, Avro, and Parquet files for a given set of imagery are stored in a single parent directory, then the imagery, imagery metadata, and aggregated metadata can be archived by moving the parent directory with a single atomic HDFS operation.
Key takeaways
The default file format for Spark is Parquet, but as we discussed above, there are use cases where other formats are better suited, including:
- SequenceFiles: Binary key/value pair that is a good choice for blob storage when the overhead of rich schema support is not required
- Parquet: Supports efficient queries, strongly typed schemas, and has a number of other benefits not covered in this article
- Avro: Ideal for large binary data or when downstream consumers read records in their entirety and also supports random seek access to records. Provides the ability to define a strongly typed schema.
- JSON: Ideal when records are stored across a number of small files
By choosing the optimal HDFS file format for your Spark jobs, you can ensure they will efficiently utilize data center resources and best meet the needs of downstream consumers.
If working on large-scale data processing challenges or computer vision technologies interests you, consider applying for a role on our Boulder, CO-based engineering team!

Scott Short
Scott Short is a senior software engineer on Uber's Maps Engineering team, based in Boulder, CO.
Posted by Scott Short
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
