Uber’s Fulfillment Platform: Ground-up Re-architecture to Accelerate Uber’s Go/Get Strategy
July 27, 2021 / Global
Introduction to Fulfillment at Uber
Uber’s mission is to help our consumers effortlessly go anywhere and get anything in thousands of cities worldwide. At its core, we capture a consumer’s intent and fulfill it by matching it with the right set of providers.
Fulfillment is the “act or process of delivering a product or service to a customer.” The Fulfillment organization at Uber develops platforms to orchestrate and manage the lifecycle of ongoing orders and user sessions with millions of active participants.
Criticality and Scale
The Fulfillment Platform is a foundational Uber capability that enables the rapid scaling of new verticals.
- The platform handles more than a million concurrent users and billions of trips per year across over ten thousand cities
- The platform handles billions of database transactions a day
- Hundreds of Uber microservices rely on the platform as the source of truth for the accurate state of the trips and driver/delivery person sessions
- Events generated by the platform are used to build hundreds of offline datasets to make critical business decisions
- 500+ developers extend the platform using APIs, events, and code to build 120+ unique fulfillment flows
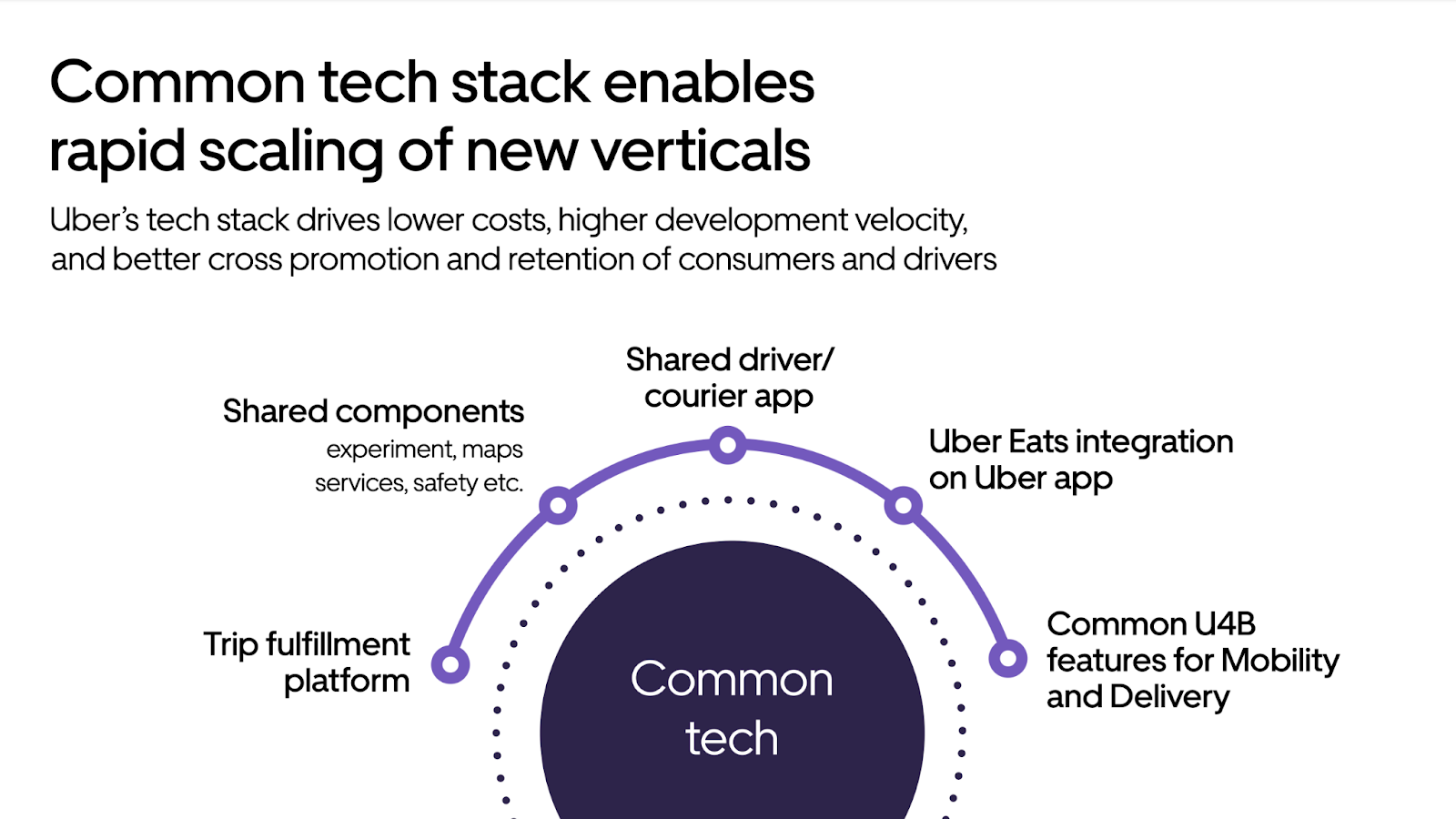
The last major rewrite of the Fulfillment Platform was in 2014 when Uber’s scale was much smaller and the fulfillment scenarios were simpler. Since then, Uber’s business has evolved to include many new verticals across Mobility and Delivery, handling a diverse set of fulfillment experiences. Some examples include reservation flows where a driver is confirmed upfront, batching flows with multiple trips offered simultaneously, virtual queue mechanisms at Airports, the three-sided marketplace for Uber Eats, delivering packages through Uber Direct, and more.
Two years ago, we made a bold bet and embarked on a journey to rewrite the Fulfillment Platform from the ground up, as the architecture built in 2014 would not scale for the next decade of Uber’s growth.
This is the first in a series of articles that describes the journey of re-architecting one of the foundational business platforms at Uber. We rebuilt the storage and application architectures, domain data modeling, APIs, and events, and successfully migrated every Uber product and city to the new stack, with support from 100+ engineers across 30+ teams.
Previous Fulfillment Architecture
This section describes the data models and architecture we used to implement a simple UberX flow in our previous fulfillment stack.
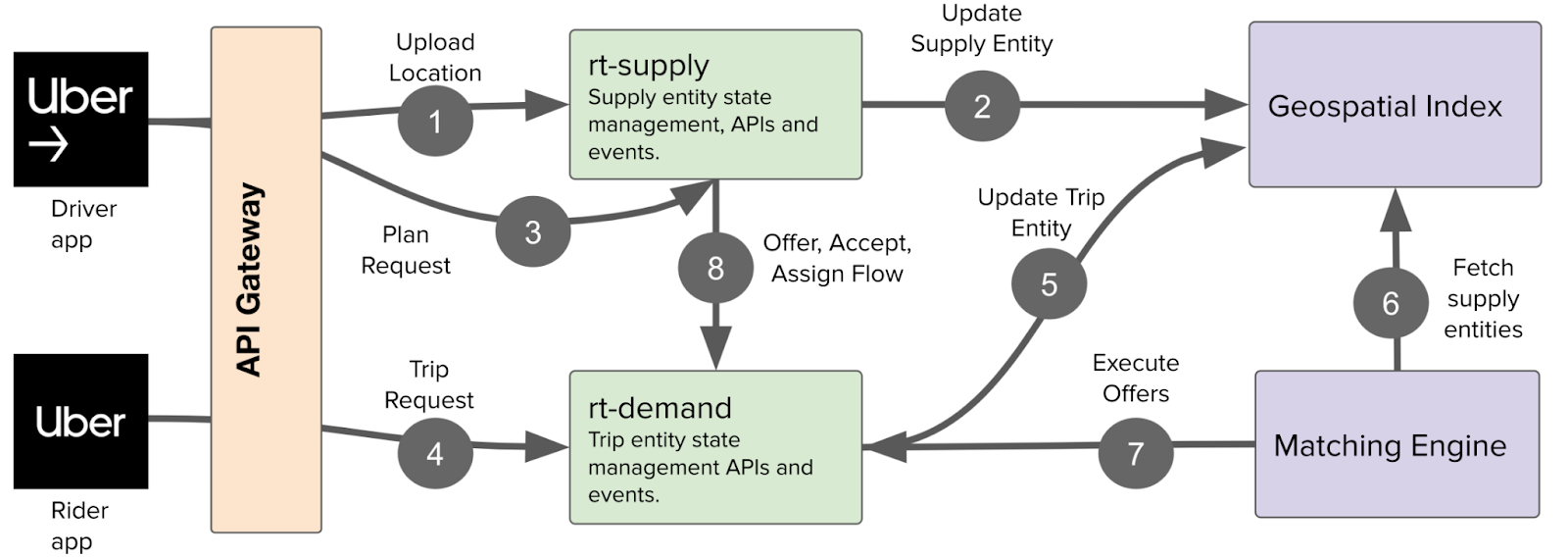
Domain Modeling
The entire fulfillment model revolved around 2 entities: Trip and Supply. The rt-demand service managed the Trip entity, and the rt-supply service managed the Supply entity. A Trip represented a unit of work (e.g. delivering a package from point A to B) while the Supply entity represented a real-world person capable of doing the unit of work.
Trip Entity
The Trip entity was composed of at least 2 waypoints. A waypoint represents a location and the set of tasks that can be performed at the location. A simple UberX trip typically has a pickup and dropoff waypoint, and a multi-destination trip has a pickup and dropoff waypoint with additional ‘via’ waypoints in between.
Supply Entity
The Supply entity modeled the state of an ongoing session for a driver/delivery person. A Supply entity could have one or more waypoints across one or more trips, to be completed in chronological order.
Read/Write Patterns
At a high level, services performed read-modify-writes based on the incoming requests, and there were three kinds of read/write patterns:
- Concurrent read-modify-writes to the same entity: For example, a driver trying to go offline and a matching system trying to link a new trip offer to the driver
- Writes involving multiple entities: If a driver accepts a trip offer, we have to modify the trip entity and the supply entity, and add waypoints of the trip in the supply entity’s plan
- Writes involving multiple instances of multiple entities: If a driver accepts a batch offer with multiple trips, all the related entities need to be updated in an all-or-nothing fashion
Application Architecture
The rt-demand and rt-supply services were shared-nothing microservices with the entities stored in Apache Cassandra® and Redis key-value tables. In the following section, we describe key components that made up the application and storage architecture. The previous architecture prioritized availability over consistency.
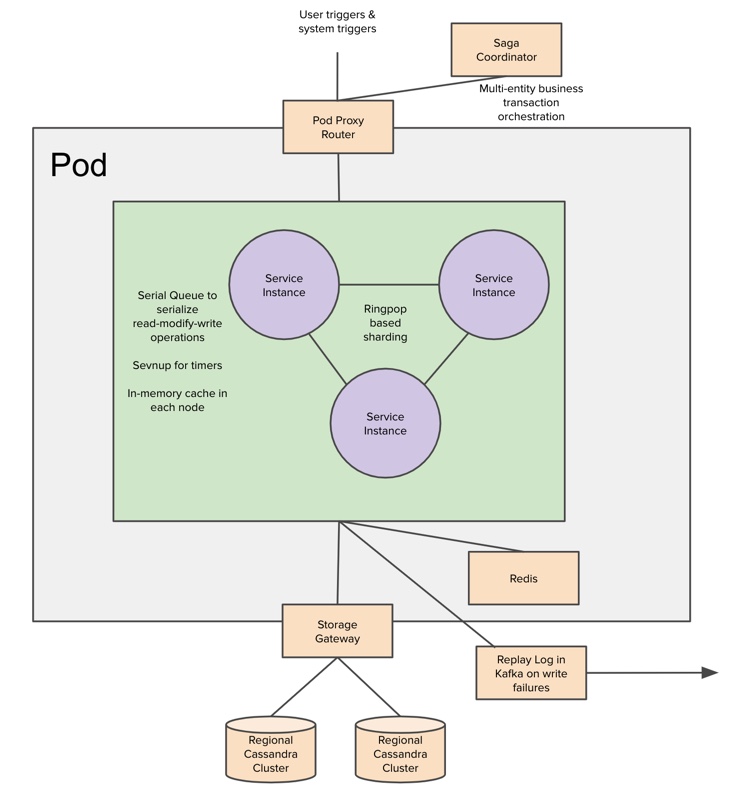
Failure Isolation Using Pods
While most of Uber’s architecture ran on 2 failure domains with 2 independent regions, in order to reduce the blast radius even further we created the concept of a pod, which contained some of the foundational services required to execute fulfillment flows. There were several pods in each region, with cities mapped onto pods based on a wide range of criteria.
Marketplace Storage Gateway
All the services inside the pod leveraged the KV store API provided by Marketplace Storage Gateway (MSG). MSG abstracted the underlying storage and leveraged Cassandra clusters. To achieve higher availability service-level objectives, MSG employed redundant storage clusters (i.e., a single application write resulted in Cassandra writes to 2 distinct clusters within the region). In each cluster, there were 3 replicas of the data. The region clusters had cross-region asynchronous replication enabled.
Application Layer Locking Using Ringpop and Serial Queue
Ringpop (archived project) is a library that brings cooperation and coordination to distributed applications. It maintains a consistent hash ring on top of a membership protocol and provides request forwarding as a routing convenience.
Ringpop enables application-level serialization for read-modify-write cycles, as each key has a unique owning worker. Ringpop forwards requests pertaining to a key to its owning worker with “best-effort” (availability over consistency). Each Ringpop-based service instance had a single-threaded execution environment (due to Node.js), a serial queue that orders incoming requests based on arrival order, and an in-memory lock on the object.
Caching Using Ringpop and Redis
There were 2 forms of cache: Redis fallback for MSG managed by the application and in-memory cache to reduce the load on the Cassandra cluster. Read operations were mainly served from an in-memory cache.
Post-Commit Operations and Timers
Most transactions required guaranteed execution of post-commit operations and scheduling timers that would be triggered at the right time (like offer expiration). This was implemented using the sevnup framework, which provides a way to hand off ownership of certain objects when a node in a hashring goes down, or another node takes ownership of the keyspace.
Multi-Entity Transactions Using Saga
Saga provides a pattern for implementing business transactions across multiple services. We leveraged this pattern for transactions across multiple-trip entities and supply entities. It provided application-layer transaction semantics to enable multi-datastore, multi-service operations. The Saga coordinator would first trigger a propose operation on all the participating entities, and if they all succeed, it would commit; otherwise, it would trigger the cancel operation for executing compensating action.
Secondary Indexes Using Separate Cassandra Tables
To find the trips for a given rider, rt-demand maintained a separate table that mapped the rider to the list of trip identifiers. Since rt-demand was sharded using identifiers, all the requests for a given trip identifier would go to the owning worker for that trip, and all the requests for a given rider identifier would go to the owning worker for that rider. When the trip was created, the trip was first saved to the rider index table, then saved to the trip table, and a best-effort request was sent to the rider owning worker to invalidate the cache.
Problems with the Previous Architecture
Infrastructure Problems
Consistency Issues
The entire architecture was built on the premise that we should trade off consistency for availability and latency, so consistency was only achieved via a best-effort mechanism. The lack of atomicity meant that we had to reconcile when the second operation failed. In the case of split-brain situations (happening during deploys, region failovers) inconsistencies could occur due to concurrent writes, which could end up overwriting each other, since Cassandra exhibited a last-write-wins semantic.
Multi-Entity Writes
If an operation required writes across multiple entities, then the application layer handled this coordination in an arbitrary RPC-based mechanism and constantly verified the expected and current state to fix any mismatches. Between the operations that formed a logical transaction, the system was in an internally inconsistent state. As we built more complex write flows using the Saga pattern, debugging issues across multiple entities and services became even harder.
Scalability Concerns
Cities were sharded among one of the available pods, and the size of the pod was dependent on the maximum ring size of a Ringpop cluster. Ringpop suffered from physical limits given the peer-to-peer nature of the protocol. This meant that there was a vertical limit for scaling the pod if any of the cities crossed a threshold of concurrent trips.
Application Problems
Deprecated Language and Frameworks
In 2018, Node.js and the HTTP/JSON framework were no longer recommended at Uber. New engineers were forced to understand the legacy application frameworks, a different programming language, and a snowflake HTTP/JSON protocol in order to make changes in the stack, dramatically increasing onboarding costs.
Data Incoherence
The previous architecture took a tiered approach to data storage. The sharded in-memory cache buffer offered the first tier, followed by Redis and MSG (with its mirrored Cassandra clusters) as the second tier. The tiered approach was performant and redundant at the cost of maintaining cache coherence. Buffering data changes in the local cache further complicated cache incoherence when it occurred.
No Clear Extensibility Patterns
Over 400 engineers modified the core Fulfillment Platform in the last few years. Without any clear extension model and developer patterns, it became really difficult for new engineers to reason about the entire flow and make changes with confidence and safety.
New Fulfillment Architecture
We spent 6 months carefully auditing every product in the stack, gathering 200+ pages of requirements from stakeholder teams, extensively debating architectural options with tens of evaluation criteria, benchmarking database choices, and prototyping application frameworks options. After several critical decisions, we came up with the overall architecture to suit our needs for the new decade. This section gives a high-level overview of the new architecture.
Requirements for the New Architecture
- Availability: Ensure that any single region, zonal, or intermittent infrastructure failure has minimal impact on application availability, while guaranteeing at least 99.99% adherence to SLA
- Consistency: Strong consistency for single-row, multi-row, and multi-row multi-table transactions across regions
- Extensibility: Provide a framework with clean abstractions and simple programming of new product features
- Data loss: Single-region, zonal, or intermittent infrastructure failures should not cause data loss
- DB Requirements: Support for secondary indices, change data capture, and ACID compliance for transactions
- Latency: Provide better or the same latency for all fulfillment operations
- Efficiency: Provide the capability to track service efficiency through normalized business and application metrics
- Elasticity: Horizontal scalability across the entire stack to autoscale based on business growth without any scalability bottlenecks
- Low Operational Overhead: Minimal operational overhead for adding new entities/cities/regions, no downtime schema upgrades, and automated shard management.
Transitioning from NoSQL to NewSQL
Our solution for storage abstraction focused on 3 methodologies:
- Incrementally update the existing NoSQL-based architecture
- Leverage Apache Helix and Apache Zookeeper for centralized shard management instead of decentralized peer-to-peer shard management in Ringpop
- Use Serial Queue to make sure only one transaction executes at any point in time, or leverage an in-house centralized locking solution to hold a lock on an entity while a transaction is in progress
- Continue using the Saga-based pattern for any multi-entity cross-shard transactions
- Switch to using in-house MySQL based storage
- Build a mechanism to shard all fulfillment data across multiple MySQL clusters
- Build a solution for consistent schema upgrades, cross-region replication, and easily promoting secondaries to primaries
- Build a solution to handle downtime between region failovers and ensure there is no lack of consistency
- Explore a completely new NewSQL-based storage
- Leverage a NewSQL database to provide transactional primitives while maintaining horizontal scalability
- Evaluate an on-prem based solution (like CockroachDB or FoundationDB) or a managed solution (like Google Cloud Spanner)
To satisfy the requirements of transactional consistency, horizontal scalability, and low operational overhead, we decided to leverage a NewSQL architecture. Prior to this project, there was no precedent at Uber for leveraging NewSQL-based storage. After thorough benchmarking and careful evaluation with dimensions like availability SLA, operational overhead, transactional capabilities, schema management, shard management, auto-scaling, and horizontal scalability, we decided to use Google Cloud Spanner as the primary storage engine.
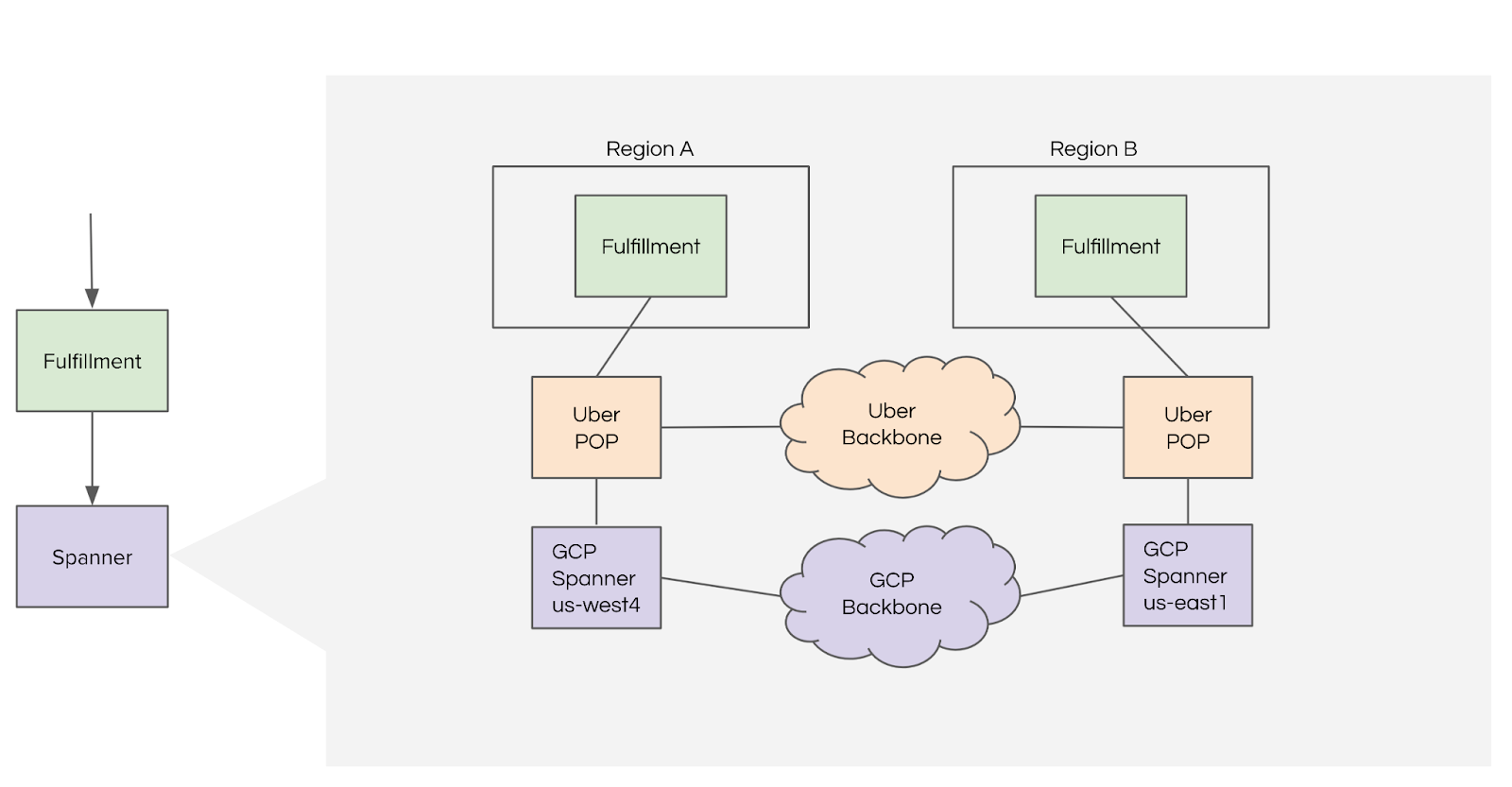
Spanner as a Transactional DB
We leverage Spanner’s North America multi-region configuration—nam3—as the storage engine for fulfillment entities. The Fulfillment service runs in Uber’s operational regions in North America and makes a sequence of network calls across to Spanner deployed in Google Cloud for every transaction.
Fulfillment relies on some of the core capabilities exposed by Spanner such as:
- External Consistency: Spanner provides external consistency, which is the strictest concurrency-control guarantee for transactions
- Server-side transaction buffering: We leverage Spanner DML-based transactions so that individual modules can update their corresponding tables and dependent modules can read the updated version within the scope of the ongoing transaction
- Horizontal Scalability: Spanner shards data to physical servers by primary key ranges, which provides horizontal scalability, assuming there are no hotspots
- SQL Support: Reads, inserts, or updates to rows are done through a Data Manipulation Language
- Cross Table, Cross Shard transactions: Spanner supports transactions that span multiple rows, tables, and indexes
- Contention and Deadlock detection: Spanner keeps track of locks across rows and issues transaction aborts when there is contention between transactions and avoids potential deadlock scenarios
- Stale reads: Support for point-in-time reads (exact-staleness) and bounded-staleness reads
Post-Commit Operations
The public version of Spanner doesn’t currently support change data capture out of the box. To provide the at-least-once guarantee for post-commit operations, we built a component called Latent Asynchronous Task Execution (LATE). All post-commit operations and timers are committed along with the read-write transaction to a separate LATE action table that indicates all the post-commit operations to be executed. LATE application workers scan and pick up rows from this table and guarantee at-least-once execution.
We will cover how we chose the right storage, evaluated requirements, and operationalized Spanner within Uber in the second article in this series.
Programming Model
As Uber engineering scales and our product flows grow, the Fulfillment Platform’s programming model must provide simplicity, modularity, extensibility, consistency, and correctness to ensure that 100+ engineers can build upon this platform safely.
At a high level, there are 3 parts of the new programming model:
- Statecharts for modeling fulfillment entities to ensure consistent and modular behavior modeling
- Business Transaction Coordinator for handling writes across multiple entities so that each entity can be modular and leveraged in different product flows
- ORM Layer for providing database abstractions, simplicity, and correctness so engineers don’t need to worry about knowing how to work with ACID databases
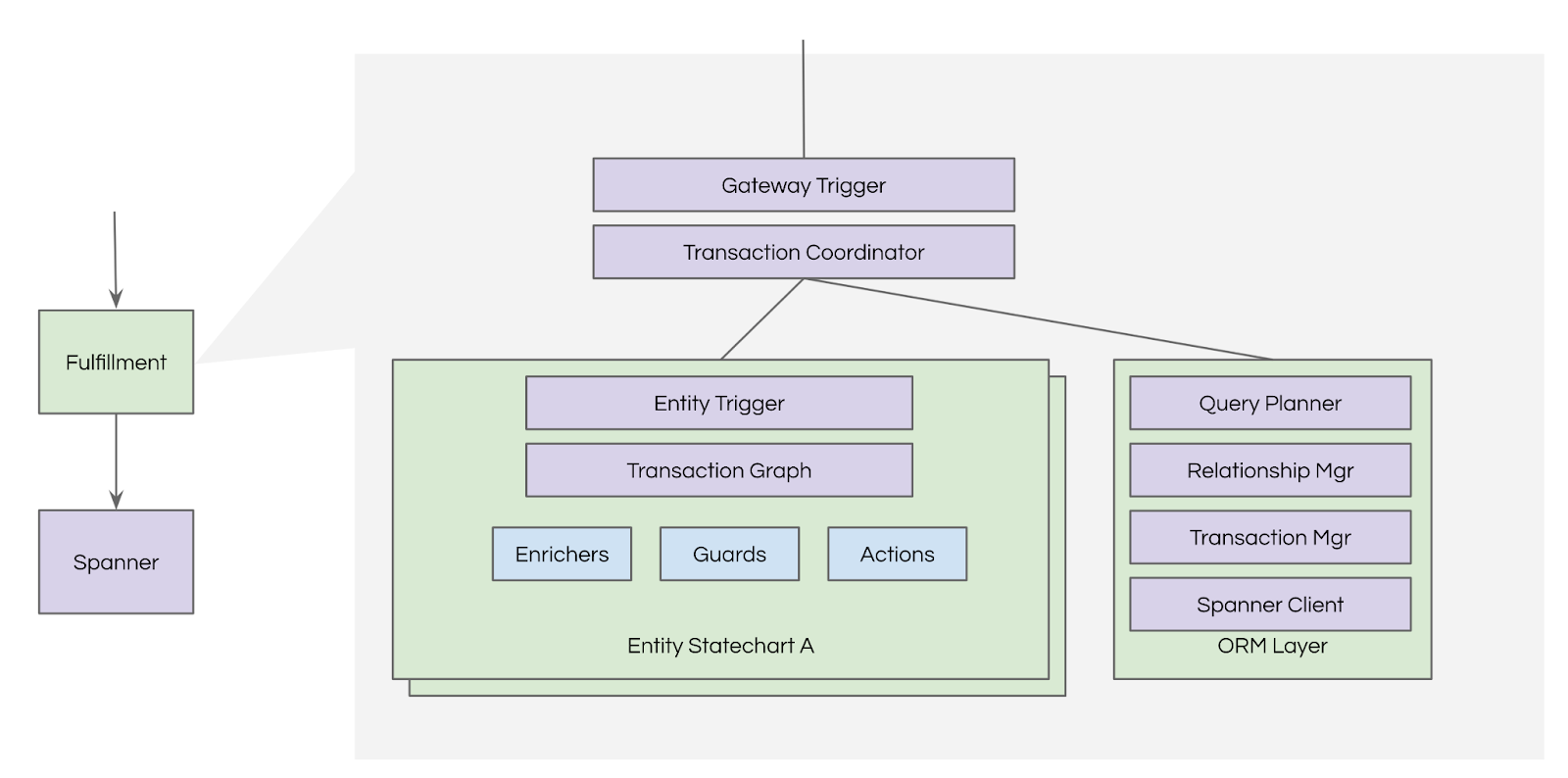
Statecharts
We leverage Statecharts to represent the entity lifecycle as a hierarchical state machine. We formalized and documented the principles of modeling a fulfillment entity by leveraging a consistent data modeling approach with Protobufs and building a generic Java framework for implementing statecharts.
What is a Statechart?
A statechart is a finite-state machine where each state may define its own subordinate state machines, called substates. Those states can again define substates. Nested states allow for levels of abstraction and provide hierarchical levels for zooming into specific functional capabilities within the system.
A statechart is composed of 3 primary components:
- States: A state describes a particular behavior of the state machine. Each state can specify the number of triggers that it understands, and for each trigger, any number of transitions that could be taken if that trigger happens. A state also describes a set of actions to execute when the state is entered or exited.
- Transitions: A transition models how the state machine transitions from one state to another.
- Triggers: A trigger is either a user signal that represents a user intent or a system event that something has happened.
When a trigger happens, the statechart gets notified, and then the statechart notifies the currently active state about the trigger. If there is a corresponding transition registered to the state for that trigger, then the transition executes, resulting in the statechart transitioning from the current state to the target state.
How Do We Build a Fulfillment Entity as a Statechart?
A fulfillment entity refers to a business object that models a physical (e.g., a delivery person, or their vehicle) or digital abstraction (e.g., the work required to transport a package), in order to model a consumer (or interactions between multiple consumers) using a finite-state machine model.
Each fulfillment entity is defined statically through a statechart configuration with states, transitions between states, and triggers registered on each state. These modeling components (statecharts, transitions, triggers) are materialized in the application layer through explicitly defined code components (Java classes). These code components constitute the functional business logic associated with the modeling components. In addition to that, triggers are exposed as RPC to allow external systems (user applications, periodic events, event pipelines, and other systems) to invoke the trigger through the RPC interface.
Transaction Coordinator
A single business flow can involve one or more fulfillment entity triggers when interacting with consumer apps and other internal systems. For example, when capturing the user’s intent of delivering food from a restaurant, we create an order entity to capture the user’s intent, a job entity for food preparation, and another job entity to deliver the food from the restaurant to the user’s location. This results in coordinating multiple entity transitions within the scope of a single transaction in order to provide a consistent view to the consumer of every fulfillment entity that participates in the business flow. The successful completion of a business flow might also result in side effects (e.g., non-transactional updates to other systems, writing to Apache Kafka, sending notifications) that require at-least-once execution semantics following completion of the business flow.
To achieve transactionally consistent coordination across one or more entities, we provide higher-level APIs through a gateway. The APIs can be triggers or queries. A trigger allows for transactional updates of one or more entities, whereas a query allows the caller to read the state of one or more entities.
The gateway leverages 2 primary components to implement triggers and APIs: a business transaction coordinator and a query planner. The business transaction coordinator takes a directed acyclic graph of entity triggers as input and orchestrates through the nodes, representing single-entity triggers, in the graph within the scope of a single read-write transaction. A query planner is responsible for providing read-access with variable levels of consistency across entities and their relations.
ORM Layer
The ORM layer provides a layer of abstraction over the database constructs for transaction management, entity access, and entity-entity relationship management.
The third article in this series will describe these components in detail that make up the application framework and how it enabled 100+ engineers to build product flows on the new architecture.
Challenges and Learnings
- Technical decision-making: We had to take hundreds of decisions of varying complexity and impact. It’s important to set up the right decision framework, the decision-maker, dimensions of evaluation, and strategies for risks and mitigation.
- Communication: The overall project spanned ~2 years involving 30+ teams and hundreds of developers. It was important to devise communication strategies with stakeholders to keep the momentum going. The leads synced every day to handle escalations, blockers, and prioritization decisions. The entire team met every week to share updates, demos, and deep dives to stay motivated.
- Working as one team: In a stable period, each team would have their own projects, but through this project, we had Fulfillment teams deprioritize many projects and work together as one big virtual team. As the needs of the project changed, we created several virtual team structures with different goals and priorities. This nimbleness and alignment helped us stay on course.
- Migration and compatibility design upfront: Greenfield platforms don’t have the burden of migrating existing API callers, offline event consumers, and live data. The fulfillment domain has hundreds of API callers, thousands of offline data consumers, and over a million online consumers at any point in time with ongoing trips and sessions. It was extremely challenging to design a migration strategy, including forward or backward compatibility, architecture and tooling, shadow testing, and load testing. We will describe how we did a live migration of our real-time traffic in the fourth article in this series.
- Testing and mitigating unknown unknowns: We built new, end-to-end integration tests for 200+ product flows and back-tested them on the existing stack to validate the correctness of the new stack relative to the old stack. We built a sophisticated, session-based shadow framework to compare the requests and responses between the old and new stacks. We created test cities that matched configurations of production cities to smoke test during development. All of these strategies ensured that we caught as many issues as possible and minimized the unknown unknowns.
Closing
After 2 years of marathon execution, we built a strong foundation for modeling various types of physical fulfillment categories in the new platform and migrated all existing transportation use cases. In our next chapter, we’re working on supporting Uber’s new and existing verticals of physical fulfillment flows, strengthening the platform, and building adjacent capabilities to unlock even more value for the product teams we serve. We are truly on day one of this journey and hope you’ll join us.
Apache®, Apache Cassandra®, Apache Helix, Apache Zookeeper, Apache Kafka, Helix, Zookeeper, and Cassandra® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.

Ashwin Neerabail
Ashwin Neerabail is a Staff Engineer at Uber. He is a Software Engineer/Architect with experience in designing and developing large-scale, mission-critical platform and infrastructure services. Since joining Uber, in the last 2 years, he has led the development of the next generation Fulfillment platform that powers Uber's Mobility and Delivery products.

Ankit Srivastava
Ankit Srivastava is a Principal Engineer at Uber. He has led and contributed to building software that scales to millions of users of Uber across the world. During the past 2 years, he led the ground-up redesign of Uber's Fulfillment Platform that powers the logistics of physical fulfillment for all Uber verticals. His interests include building distributed systems and extensible frameworks and formulating testing strategies for complex business workflows.

Kamran Massoudi
Kamran Massoudi is a Staff Engineer at Uber. During his tenure at Uber, he has contributed to creating the technical vision for the Fulfillment Platform and has led various projects. He led the effort to create the platform that is responsible for providing unified, coherent, and prioritized off-trip content for drivers/delivery people. He was also one of the tech leads that initiated and led the re-architecture of the Fulfillment Platform in the last 2 years and is currently working on the next generation of Uber's Product Configuration management.

Madan Thangavelu
Madan Thangavelu is a Director of Engineering at Uber. Over the last 7 years, he has witnessed and contributed to the exciting hyper-growth phase of Uber. He spent 4 years leading the API gateway and streaming platform teams at Uber. He is currently the engineering lead for Uber's Fulfillment Platform that powers real-time global scale shopping and logistics systems.

Uday Kiran Medisetty
Uday Kiran Medisetty is a Principal Engineer at Uber. He has led, bootstrapped, and scaled major real-time platform initiatives in his tenure at Uber. He worked on revamping the overall Mobile API architecture from a monolithic polling-based flow to a bidirectional streaming-based flow. In the last 2 years, he led the re-write of the Fulfillment architecture that powers mission-critical business flows for all Uber verticals applications in the company. In the last couple of years, he led the re-architecture of Uber’s core fulfillment platform.
Posted by Ashwin Neerabail, Ankit Srivastava, Kamran Massoudi, Madan Thangavelu, Uday Kiran Medisetty
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ

Uber Health and Findhelp support patients beyond the four walls of a medical office
Products
Company
