
Introduction
Since we productionized distributed XGBoost on Apache Spark™ at Uber in 2017, XGBoost has powered a wide spectrum of machine learning (ML) use cases at Uber, spanning from optimizing marketplace dynamic pricing policies for Freight, improving times of arrival (ETA) estimation, fraud detection and prevention, to content discovery and recommendation for Uber Eats.
However, as Uber has scaled, we have started to run distributed training jobs with more data and workers, and more complex distributed training patterns have become increasingly common. As such, we have observed a number of challenges for doing distributed machine learning and deep learning at scale:
- Fault Tolerance and Elastic Training: As distributed XGBoost jobs use more data and workers, the probability of machine failures also increases. As most distributed execution engines including Spark are stateless, common fault-tolerance mechanisms using frequent checkpointing still require external orchestration and trigger data reloads on workers. This incurs significant per-worker data shuffling, serialization, and loading overheads.
- Distributed Hyperparameter Search and Complex Compute Patterns: Emergent training patterns are complex and require higher-level orchestration systems to schedule and coordinate the distributed execution of parallel, multi-node distributed training jobs with dynamic resource allocation requirements. This introduces significant resource and scheduling overhead on top of data loading and model checkpoint management costs.
- Need for a unified compute backend for end-to-end Machine Learning: Flexibility and maintainability of heterogeneous compute and bespoke systems across the lifecycle is becoming costly and prevents us from taking advantage of data locality, worker colocation, and the use of shared memory between them.
We recently released Elastic Horovod on Ray as a first step towards addressing some of these challenges for the end-to-end deep learning workflows at Uber. With similar motivations, we collaborated with the Ray team to co-develop distributed XGBoost on Ray.
In this blog, we discuss how moving to distributed XGBoost on Ray helps address these concerns and how finding the right abstractions allows us to seamlessly incorporate Ray and XGBoost Ray into Uber’s ML ecosystem. Finally, we cover how moving distributed XGBoost onto Ray, in parallel with efforts to move Elastic Horovod onto Ray, serves as a critical step towards a unified distributed compute backend for end-to-end machine learning workflows at Uber.
Fault Tolerance and Elastic Training
As we start to train distributed XGBoost jobs with more data and workers, the probability of machine failures also increases. Frequent checkpointing may help avoid having to restart the job completely from scratch, but since most distributed execution engines—including Spark—are stateless, resuming a run via checkpoints needs to be externally managed. Each worker often has to reload large datasets from distributed sources, incurring significant data shuffling, serialization, and loading overhead for each restart.
At Uber, we run the majority of our distributed training jobs on dedicated, on-premise instances, but this problem becomes particularly onerous when users want to leverage preemptible resources to take advantage of their cost savings and higher instance availability.
Ray Actor Framework
XGBoost on Ray is built on top of Ray’s stateful actor framework and provides fault-tolerance mechanisms out of the box that also minimize the aforementioned data-related overheads. Ray’s stateful API allows XGBoost on Ray to have very granular, actor-level failure handling and recovery. In the event of single or multi-node failures, XGBoost on Ray can retain loaded data in unaffected actors that are still alive, and only requires the re-scheduled actors to reload their respective data shards.
Stateful XGBoost Training on Ray
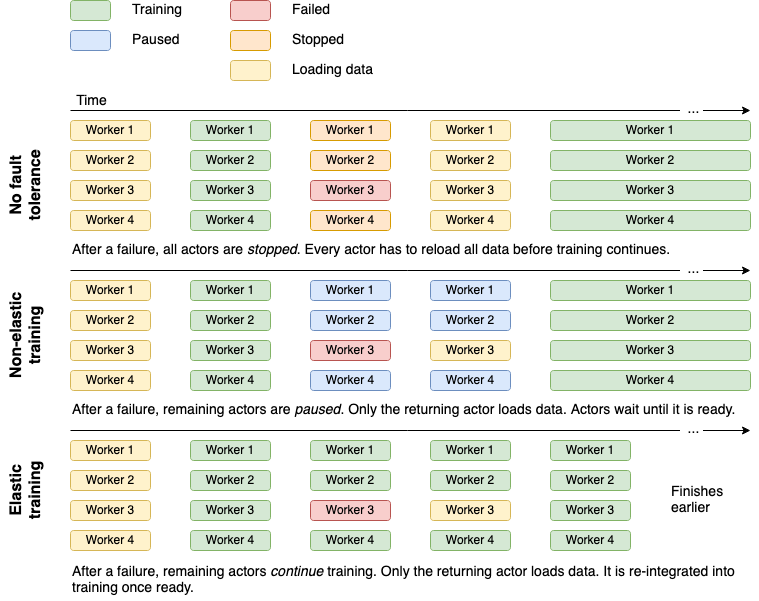
XGBoost on Ray currently comes with two modes for failure-handling:
- Non-elastic training (default): In the event of actor failures, XGBoost on Ray will wait for the failed actors to be rescheduled and continue training from the latest checkpoint. Alive actors will remain idle in the meantime, but maintain their state, thus bypassing the cost of data shuffling and loading again.
- Elastic training: In the event of actor failures, training will continue on fewer actors (and on fewer data) until the failed actors are back again. When there are available resources, the failed actors are re-scheduled and data loading on each actor is triggered in the background. The active actors continue training and only re-integrate each restarted actor back into the training process once it has completed data loading.
For elastic training, this means that for some amount of time, training will continue on fewer data until the rescheduled actors rejoin the process. While this may come with slight decreases in training accuracy, we found that this impact is often negligible in practice, given the high number of actors and large enough, well-shuffled datasets. The impact is usually offset by the amount of time saved by immediately continuing to train. The benefits of elastic training often increase with dataset size when data reshuffling and loading can take up a large fraction of the total time.
Benchmark and Discussions
We ran a benchmark to compare how the different fault-tolerance modes perform in the event of multi-node and multi-actor failures.
| Condition | Impacted Workers | Validation Log Loss | Train Error | Train time (s) |
| Fewer workers | 0 | 0.405359 | 0.132591 | 1441.44 |
| Fewer workers | 1 | 0.406041 | 0.133103 | 1227.45 |
| Fewer workers | 2 | 0.405873 | 0.132885 | 1249.45 |
| Fewer workers | 3 | 0.405081 | 0.132205 | 1291.54 |
| Non-elastic | 1 | 0.405618 | 0.132754 | 2205.95 |
| Non-elastic | 2 | 0.405076 | 0.132403 | 2226.96 |
| Non-elastic | 3 | 0.405618 | 0.132754 | 2033.94 |
| Elastic | 1 | 0.40556 | 0.1327 | 1231.58 |
| Elastic | 2 | 0.405885 | 0.132655 | 1197.55 |
| Elastic | 3 | 0.405487 | 0.132481 | 1259.37 |
Fig 2. Elastic and non-elastic Training Benchmark. The evaluation dataset and training hyperparameters (30M rows, 500 features, 300 boosting rounds) are kept constant across all runs.
First, we establish a baseline by training on the full dataset without actor failures. We then remove up to three actors (Fewer workers) to see the accuracy impact when training on fewer data. As expected, we observed a small regression on the evaluation performance, but not by much.
Non-elastic Training achieved a slightly better evaluation performance than in the Fewer workers scenarios. This is expected as it waits for failed actors to get rescheduled and continues to train on the full dataset. The rest of the machines remain idle during that time. This results in longer training time, due to the rescheduling delays, and the data reshuffling and reloading overhead of the failed actors. Note that non-elastic training incurs these overheads only for failed actors while maintaining the state of the alive actors, which is often the majority. This is already a significant improvement over having bespoke failure-handling layers on top of stateless distributed execution.
For Elastic Training, training continues on fewer actors until the failed actors are reintegrated in the background. Overall, it achieved a slightly worse but comparable evaluation performance with respect to the baseline and the non-elastic case. This is expected since it is training on less data while waiting for the failed actors to be rescheduled. More importantly, elastic training was able to achieve comparable training time with respect to the baseline as if there are no failures!
In summary, XGBoost on Ray’s stateful training modes for failure-handling minimize data-related overheads by leveraging Ray’s stateful API to retain the states of the unaffected actors that are alive. Specifically, elastic training reduces training time with seemingly few drawbacks when training on large and properly shuffled datasets for a relatively large number of boosting rounds.
Hyperparameter Optimization and Complex Compute Patterns
Complex computational patterns are becoming increasingly relevant when doing distributed machine learning at scale. The latest distributed hyperparameter optimization techniques often go beyond the sequential execution patterns found in general Bayesian Optimization.
Genetic algorithms like Population-based Training (PBT) search through hyperparameter schedules over the course of the training process via a series of hyperparameter mutations and resource re-allocations during the study. Parallel exploration and exploitation patterns are also becoming common, with each trial allocated a resource or time-constraint budget, and accelerated using dynamic resource allocation to prioritize more promising trials. In essence, we want to be able to easily fan out during the initial exploration phase, make decisions based on intermediate cross-trial evaluations, and then dynamically allocate more resources to the more promising trials in the exploitation phase.

From a computational pattern standpoint, many of these techniques require each trial to have granular control over when to start, pause, early stop, and restart at specific iterations, while being collectively coordinated within a master-worker architecture that centralizes decision making. This does not fit naturally with the stateless, bulk-synchronous nature of common distributed execution engines like Spark, and often requires a separate higher-level orchestration layer to schedule and coordinate the multiple parallel trials in a study (with each trial being a multi-node distributed training job). Issues related to fault tolerance, autoscaling, elastic training, and data-related overheads for a single distributed training job are further multiplied in this scenario, not to mention the other factors and hyperparameters that can affect training throughput, convergence, and cost in distributed deep learning scenarios on an auto-scaling cluster.
Distributed Coordination of Parallel XGBoost on Ray Jobs with Ray Tune
XGBoost on Ray integrates out of the box with hyperparameter optimization library Ray Tune. As Ray Tune is built on top of Ray, it inherits its set of general distributed computing primitives that provides fault-tolerance properties on top of tasks and stateful actors. This ensures that the impact of failing machines is limited to as few trials as possible. Ray Tune also leverages Ray’s native support for nested parallelism to allow scheduling multiple concurrently running jobs that are inherently distributed within the same cluster. This is crucial, as the scheduling costs of higher-level orchestration systems tend to increase with the complexity of the computational pattern.
Integration with Ray Tune automatically creates callbacks to report each trial’s intermediate training statuses and results back to Ray Tune, manages checkpoints and resources for each trial, and co-locate actors of different trials to minimize communication costs by utilizing Ray’s shared memory architecture across nodes and actors.
In essence, Ray Tune displaces the need for a separate orchestration layer, and fulfills its role for distributed coordination of parallel trials in a fault-tolerant and elastic manner, directly within the same Ray cluster.
Benchmark and Discussions
Using XGBoost Ray and Ray Tune, we ran a benchmark on 2 weeks of production XGBoost jobs at Uber to compare how different hyperparameter search techniques improve the overall efficiency of studies. and assess their effects on the accuracy of the best candidate found per study.
| Technique | Mean Efficiency Gain (%) per Study | Mean Accuracy Change (%) of Best Candidate per Study |
| Trial-level Early Stopping | 16.3 | +0.06 |
| Median Stopping Rule | 52.8 | -0.54 |
| Asynchronous Successive Halving Algorithm (ASHA) | 68.9 | -0.59 |
| Bayesian Optimization HyperBand (BOHB) | 69.9 | -0.78 |
Fig 4. Ray Tune Benchmark conducted on 2 weeks of production jobs showing the mean efficiency gains (%) and mean accuracy change (%) of best candidate per study for different distributed hyperparameter search schedulers relative to production Bayesian Optimization. Each study typically has 40-60 trials searching through a set of up to 12 hyperparameters for XGBoost. For some studies, early stopping helped reduce overfitting, thus leading to an improvement in mean accuracy.
For each study, we held the train and cross-validation datasets constant, and compared different techniques with our production Hyperparameter Search service (AutoTune), which employs a trust-region based Bayesian Optimization (TuRBO) as baseline. We wanted to determine the efficiency gain measured by the total number of boosting rounds pruned, and whether there is any performance impairment (on the test set) to the best candidate found for each study. As this does not account for reduction in scheduling and data-related overheads, the actual efficiency gain in terms of resources and total wall-clock time is even higher. We intend to discuss this further in a subsequent blog post.
Overall, Ray Tune enabled new distributed hyperparameter optimization techniques that can drastically improve training efficiency with some tradeoff for best candidate accuracy that can be adjusted by leveraging more conservative early stopping configurations.
Looking Ahead: Dynamic Resource Allocation with Parallel Explore and Exploit
There is ongoing work to implement the HyperSched scheduler on top of Ray Tune and Ray primitives, which allows us to dynamically allocate more resources to more promising trials to ensure we find the best candidate within a fixed amount of time and compute resources time limit.
This is particularly useful at Uber where we run most of our distributed training jobs on dedicated, on-premise instances. We are looking to explore this capability using XGBoost and Horovod on Ray with Ray Tune in the near future.
Bringing Ray and XGBoost Ray into Uber: Finding the Right Abstractions
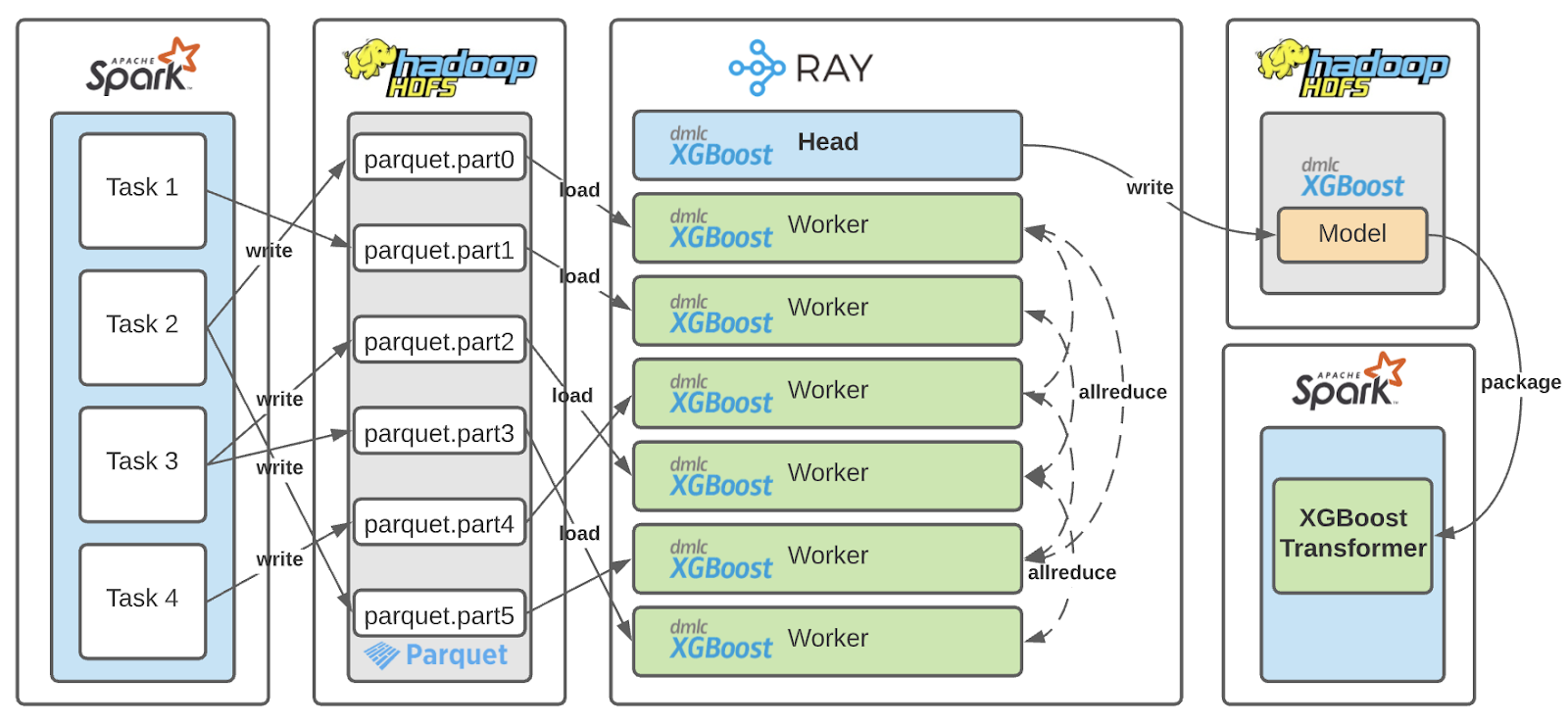
Michelangelo adopts Spark ML’s Pipeline abstractions to encapsulate the stages within its training and serving pipelines. A trained, servable model on Michelangelo is essentially a PipelineModel with a sequence of serialized Spark Transformers. We extended the Spark ML abstractions to generalize its mechanism for model persistence and online serving in order to achieve extensibility and interoperability without compromising on scalability. The PipelineModel interface also allows us to enforce a contract between training and serving in order to guarantee training-serving and online-offline performance consistency. Our existing distributed XGBoost training in production leverages our in-house fork of open-source XGBoost Spark which provides Estimator and Transformer APIs that fit naturally with our PipelineModel interface.
To incorporate Ray and XGBoost Ray, similar to our motivations for Horovod on Spark, we needed to decouple the tight model lifecycle design loop in Spark and provide an interface compatible with our Pipeline abstractions that hides the complexity of gluing Spark DataFrames to a distributed training environment outside of Spark. It must also have the flexibility to still allow for model evaluation and inference on Spark if needed.
Furthermore, we wanted to leverage Ray’s resource-aware scheduling and load-based auto scaling features that are necessary for doing more complex, stateful training patterns on top of XGBoost Ray (e.g. distributed hyperparameter optimization). The interface needs to be flexible enough to abstract away the process of going between heterogeneous compute (e.g., Spark and Ray), and extensible enough to easily enable other patterns of distributed executions and coordination. This is feasible because Ray and libraries built on top of Ray already provide good abstractions around its general set of distributed primitives.
Ray Estimators
We defined a Ray Estimator API that respects the Spark DataFrame API while abstracting away the process of moving between the Spark and Ray environments from users. This hides away any Ray-related complexity—including cluster setup, scheduling, and initialization—and frees up users to interact only with the model code. Since the Ray Estimator API extends Spark Estimators, it is compatible by default with our PipelineModel abstractions and its contract between training and serving.
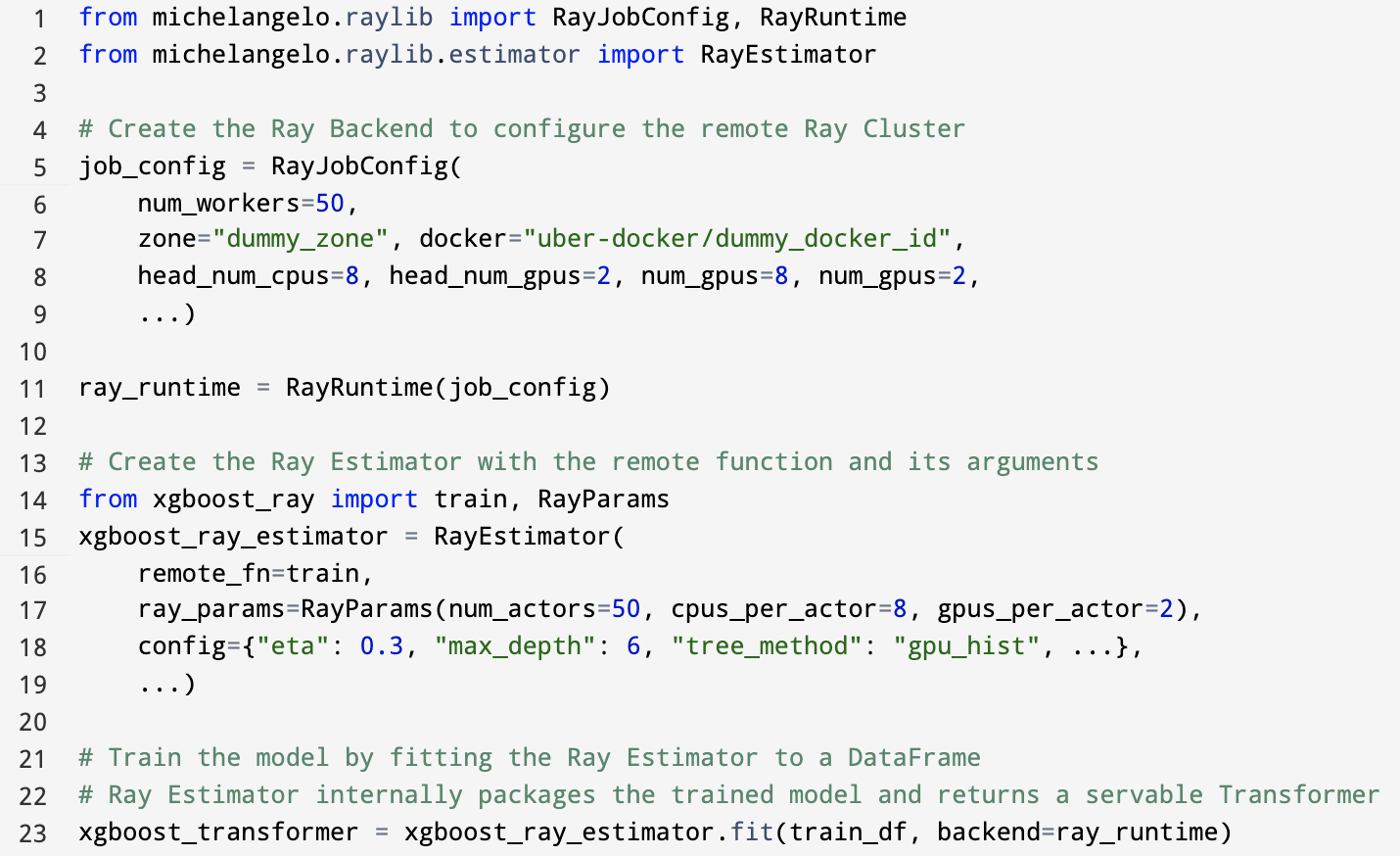
Before we initialized the Ray Estimator, we first created a Ray backend that creates and enables interactions with a remote training job on the Ray cluster given a set of configurations. Since Ray has resource-aware scheduling supported by default, it allows us to launch training on workers with CPUs or GPUs.
The Ray Estimator takes in the Ray backend, any arbitrary serializable function and its respective arguments, and utilizes the Ray Client to remotely execute it on the Ray cluster. To run XGBoost Ray, we simply pass in XGBoost Ray’s train function to the Ray Estimator. This can also be easily extended to other complex training patterns that we want to execute remotely on the Ray Cluster (e.g., distributed hyperparameter search that fanout to multiple parallel trials).
In this example, the XGBoost Ray Estimator will create 50 GPU workers that form the Ray Cluster, each participating in data-parallel XGBoost training and synchronization. As XGBoost-Ray supports NCCL2 implementation out of the box, the GPU workers can also immediately leverage its efficient, multi-node, cross-GPU allreduce communication primitives, improving training efficiency.
Complexities Under the Hood
When we call Estimator.fit() on a Spark DataFrame, the Ray Estimator hides the following complexities:
- Materializes the Spark DataFrame to storage (if it is already cached, fetch its backing files via the DataFrame metadata)
- Manages any Ray Cluster set up, initialization, and necessary toolings
- Serializes and remotely executes the training function on the Ray Cluster
- Packages the trained binaries and artifacts into servable Transformers
The packaged model returned by the Ray Estimator is itself a Spark Transformer that can be directly inserted into an inference pipeline or used for batch prediction. As inference generally can be embarrassingly parallel, idempotent, and does not require coordination between workers, we can fall back to the Spark’s programming model without the need to execute it on a separate backend like on Ray.

By leveraging the Spark ML Pipeline abstractions, we are also able to leverage its native MLReader and MLWriter classes for transformer and parameter serialization across the network and for persistence. If we ever want to use the Ray Estimator to execute other functions with non-standard parameters (e.g., model or architecture definitions) that are not directly serializable into a JSON dictionary, we can also easily extend the MLReader and MLWriter classes to support custom serialization.
Unified Estimator API for Distributed Hyperparameter Optimization
A core design requirement for the Ray Estimator API is to be extensible enough to execute complex distributed training patterns that may have previously required bespoke orchestration layers. Distributed hyperparameter optimization patterns can still leverage Spark as the data-preprocessing engine, but its requirements for managing the distributed execution of parallel trials and load-based auto scaling during exploration/exploitation with fault-tolerance is well suited for Ray.

The Ray Estimator interface has cleanly decoupled the role of cluster setup and management from the remote execution of serializable functions. To go from running a single distributed XGBoost Ray job to running distributed hyperparameter search using the Ray Estimator, we can simply pass in Ray Tune’s tune.run() with XGBoost Ray’s train() as serializable functions to be remotely executed on the Ray cluster.
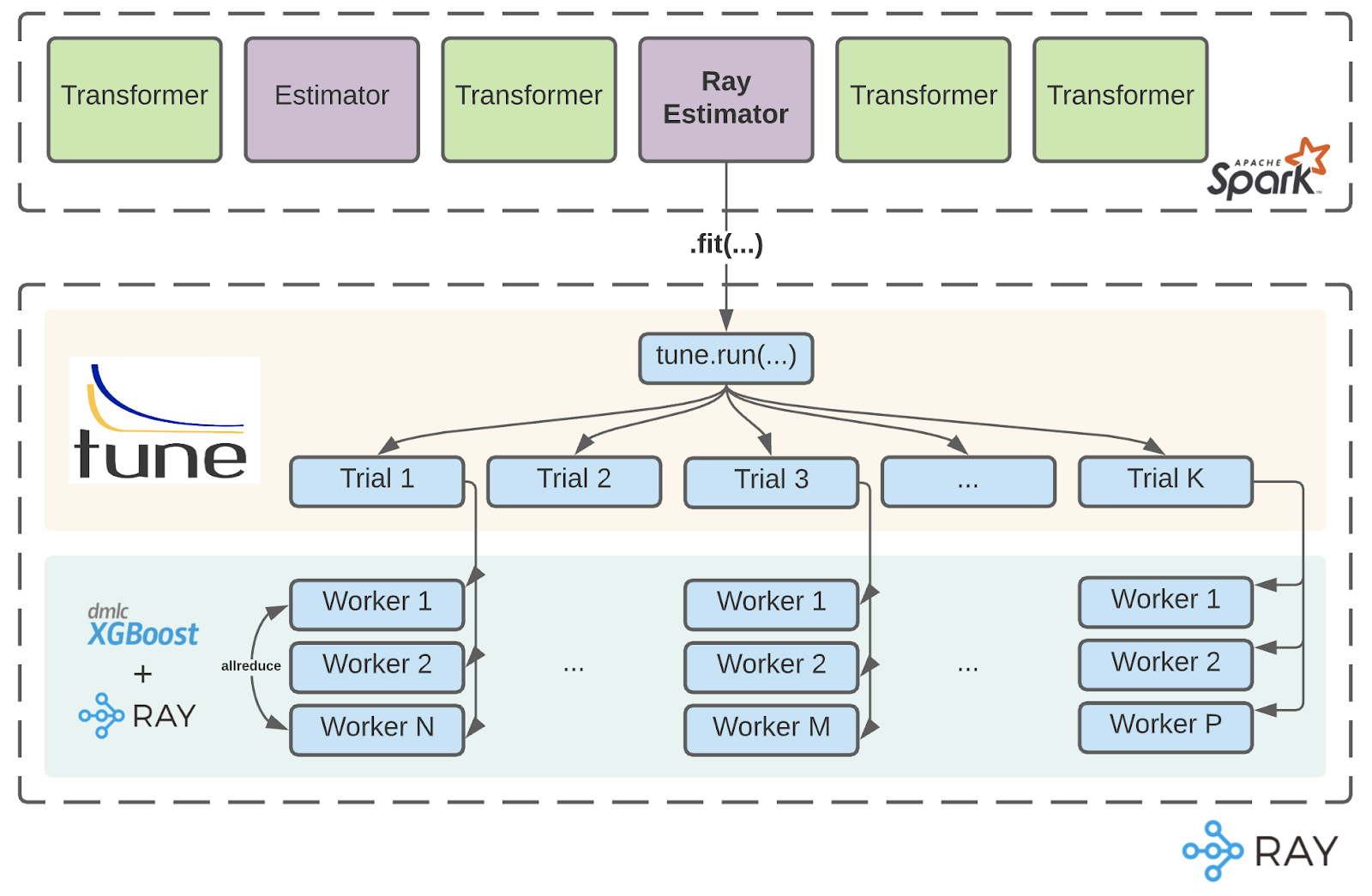
The Ray Estimator abstracts away the boundary between heterogeneous compute environments and the overhead of cluster management, while libraries such as XGBoost on Ray and Ray Tune are themselves clean abstractions around Ray’s distributed primitives. Complex distributed training patterns that previously required heterogeneous compute environments and additional orchestration layers to execute in a fault-tolerant and elastic way, can now be cleanly captured within the same PipelineModel abstractions.
Next Steps: Towards a Unified Distributed Compute Backend for End-to-end Machine Learning
Early results from integrating XGBoost and Elastic Horovod with Ray and Ray Tune at Uber have demonstrated the flexibility and versatility of Ray to connect complex distributed compute systems together into a unified workflow:
- Unified backend for distributed training: XGBoost or Horovod on Ray
- Unified backend for distributed hyperparameter optimization: XGBoost or Horovod on Ray + Ray Tune
Complex distributed training patterns that previously required bespoke distributed systems and additional orchestration layers at Uber to execute in a fault-tolerant and elastic way, can now be cleanly captured using Ray’s distributed compute primitives unified under the PipelineModel abstractions. Other complex training patterns common at Uber (e.g., automatic model explorations and model partitioning) should also readily fit within these abstractions, further simplifying the architecture and removing the need to maintain separate workflows for each complex training pattern.
As Ray continues to grow its ecosystem of distributed data processing frameworks such as Dask and Spark on Ray, we are actively exploring options to consolidate more of the stack onto Ray, including distributed data processing. By removing the sharp boundaries within heterogeneous compute environments, it effectively minimizes the materialization of intermediate artifacts and datasets when data is moving through the workflow, and allows us to better take advantage of the data locality, the actor colocation, and the shared memory architecture.
A relevant problem we are currently looking to solve using Ray is the inefficient and expensive per-epoch random shuffling of distributed datasets from storage (e.g., HDFS) into a pool of distributed training workers. This is critical for deep learning training to improve generalization, but for large datasets, data can only be shuffled one portion at a time while being consumed. Inefficient and mistimed random shuffling and data loading can easily stall distributed deep learning training, especially for synchronous Stochastic Gradient Descent (SGD). Ray’s distributed in-memory object store that can automatically cache intermediate and shuffled results with transparent data movement between the network and the GPUs, along with its ability to fuse different distributed compute tasks into a single job, provides immediate advantages for building a Ray-based distributed per-epoch shuffle data loader.
We will continue to explore Ray as part of our story towards a unified distributed compute backend for end-to-end machine learning and deep learning workflows at Uber. We will be sharing our learnings in the months to come, so stay tuned!
If you find the idea of building large-scale distributed ML systems exciting, consider applying for a role at Uber AI!
Acknowledgements
We would like to acknowledge the work and help from the following individuals:
- Kai Fricke, Amog Kamsetty, Richard Liaw, Zhe Zhang, and the Anyscale team for their efforts on developing XGBoost on Ray, and their continued support for integrating Ray into Uber’s ecosystem.
- Di Yu and Rich Porter for their efforts on setting up the Ray Runtime Environment leveraged by the Ray Estimator for cluster set up, initialization, and remote execution.
- Travis Addair for his efforts on developing Elastic Horovod on Ray, and discussions on paths towards a unified compute backend for end-to-end Deep Learning workflows.
- Anne Holler, Chi Su, and Viman Deb for their efforts and discussions on improving end-to-end Machine Learning efficiency.
We would also like to thank the entire Michelangelo team for its continued support and technical discussions.
Apache®, Apache Spark™ and Spark™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.

Michael Mui
Michael Mui is a Staff Software Engineer on Uber AI's Machine Learning Platform team. He works on the distributed training infrastructure, hyperparameter optimization, model representation, and evaluation. He also co-leads Uber’s internal ML Education initiatives.

Xu Ning
Xu Ning is a Senior Engineering Manager in Uber’s Seattle Engineering office, currently leading multiple development teams in Uber’s Michelangelo Machine Learning Platform. He previously led Uber's Cherami distributed task queue, Hadoop observability, and Data security teams.

Kai Fricke
Kai Fricke is a Software Engineer at Anyscale, the company behind the distributed computing platform Ray. He mostly works on developing Machine Learning libraries on top of Ray, like Ray Tune, or RaySGD.

Amog Kamsetty
Amog Kamsetty is a Software Engineer at Anyscale where he works on building distributed training libraries and integrations on top of Ray. He previously completed his MS degree at UC Berkeley working with Ion Stoica on Machine Learning for database systems.

Richard Liaw
Richard Liaw is a Software Engineer at Anyscale, where he currently leads development efforts for distributed Machine Learning libraries on Ray. He is one of the maintainers of the open source Ray project and is on leave from the PhD program at UC Berkeley.
Posted by Michael Mui, Xu Ning, Kai Fricke, Amog Kamsetty, Richard Liaw
Related articles





Most popular

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ
Products
Company
