Architecting seamless and enjoyable experiences for our users drives our engineering vision at Uber. As part of this mission, our team constantly develops new ways to better recognize and celebrate drivers. One example is Driver Profiles, a platform designed to enhance the Uber experience by spotlighting driver stories and achievements in the app and creating meaningful connections with riders.
From a technical perspective, developing and shipping Driver Profiles seemed straightforward. The data–e.g., name, trip count, and driver-submitted information–that we needed was already stored by existing microservices. The difficulty lay in querying each microservice and aggregating their results in a scalable and reliable fashion for use by future iterations of not just the feature, but the rider app itself. In this article, we provide an overview of a new microservice that accomplishes each of these goals by showcasing the basic design requirements and technology choices we made to fulfill them.
Driver Profile design
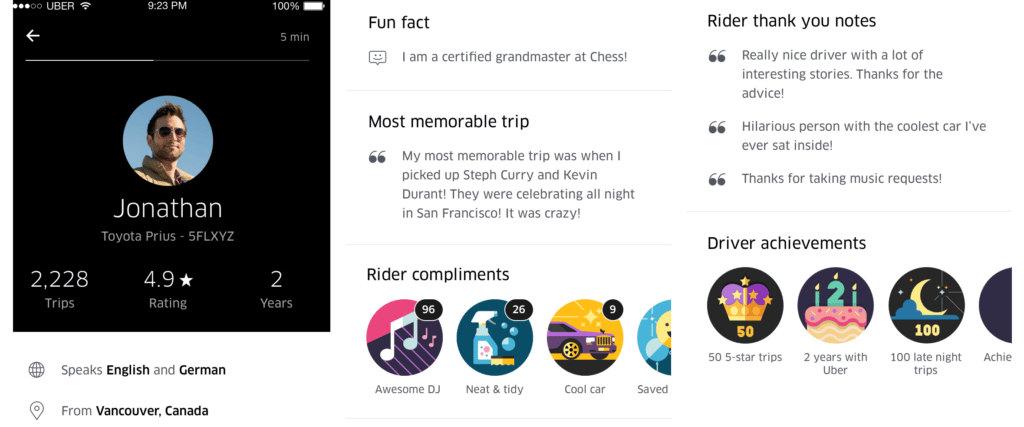
Driver Profiles are divided into independent sections, with each section displaying a different piece of information about the driver. For launch, we settled on five initial sections:
Core Stats

Core Stats shares information about the driver’s tenure with Uber (e.g. amount of completed trips, their rating, etc.)
Personal Information

The Personal Information section allows drivers to opt-in to sharing information about themselves with their riders, such as what languages they speak, where they are from, city recommendations (e.g., restaurants, coffee shops, cultural sites), their most memorable trip, and other fun facts.
Rider Compliments

The Rider Compliments section showcases compliments such as Awesome DJ, Excellent Service, and Saved the Day that the driver has received from past riders.
Rider Thank You Notes

With the driver’s permission, we share thank you notes that previous riders have given them in our Rider Thank You Notes section.
Driver Achievements

Last but not least, the Driver Achievements section spotlights special achievements the driver has garnered while on the Uber platform. Examples include a high number of 5-star trips or being on the platform for more than one year.
Microservice architecture
The first major decision we made for our microservice architecture was to use Go because it is simple to use and bodes well with Uber’s existing tech stack (much of which supports the language).
Our second key choice was to define the interface for interacting with our microservice using Thrift, which is also a popular technology at Uber.
The third significant design decision was to organize our code into a standard MVCS layout. Incoming requests are processed by handlers which forward them to controllers to be processed by business logic. Controllers in turn use gateways to access any external resources (like other microservices) needed to complete their tasks.
Each component of our microservice was abstracted behind an interface. By doing this, we were able to easily generate mocks with MockGen for each. This simplified testing and allowed us to achieve 100 percent test code coverage on all business logic. By always programming to an interface, we also ended up with highly decoupled code, making swapping out components of our microservice for new ones relatively painless. (Need to use a new datastore? No problem—just make sure your new code conforms to the existing database interface and the rest of the microservice will integrate seamlessly.)
Finally, the microservice as whole was deployed onto Docker containers into two data centers using our in-house deployment service, uDeploy.
With an overview of our microservice fresh in our minds, we next take a look at the Driver Profile data request flow.
Request flow

Authorization

When a request comes into our microservice, the first order of business is to determine whether or not we should even respond. A driver’s profile contains a lot of information and we only want it to be available to riders who are actually on a trip with the driver or have taken a trip with the driver in the past. A request for access to a Driver Profile contains a UUID for the driver whose profile we want to pull, as well as an authenticated UUID corresponding to the rider requesting the profile. These two UUIDs are used to determine if the request itself is actually valid (meaning: if the verified rider has access to the profile).
Section calculation

Once we have determined that the request for a profile is valid, we now have to decide what information we actually want to fetch. We mentioned earlier that our code needs to be as scalable and future-proof as possible, which includes supporting new profile types beyond drivers. In our microservice, the request for a profile actually includes what profile type the user would like to fetch. Since the type of the profile is part of the request, adding new profile types in the future will not require any API adjustments.
In our configuration files, we specify a list of sections that comprise each supported profile type. For the Driver Profile, this means that our configuration specifies that each of the five sections listed above are associated with it. When a request for a Driver Profile is received, we examine our configuration and determine that we need to fetch each of the five specified sections. Adding a new section for a given profile type in the future is simply a matter of adding a new section for that profile type in our configuration and adding the corresponding code for fetching that section.
Section aggregation

After determining which sections we need to fetch, we initiate a parallel fan-out to each of the downstream microservices containing the necessary information for each section. In this step, we leverage Go’s concurrency patterns to kickoff a goroutine to fetch each section. This allows us to fetch the entire profile faster since we do not have to wait for each section to be retrieved before retrieving the next one.
In addition, we enforce a timeout on each section fetch. If a single section fetch fails to load in the given amount of time, we consider the section a “failure to fetch” and move on. This allows us to guarantee that the entire profile is returned to the user in a certain amount of time. In the instance of a failure to fetch, we return the sections that we did successfully fetch. This is critical as it ensures that one bad downstream dependency does not take down our entire microservice. It is not uncommon for downstream dependencies to crash; due to this enforced timeout, our service can keep trucking along, returning what it can for each profile fetch.
Once all of the profile sections are fetched (or not), it is simply a matter of bundling the results into a single response and returning them to the user. As a finishing touch, we employ a little extra business logic to make sure the sections are ordered correctly before returning them.
Architecture testing
Before deploying our new microservice, we wanted to make sure Driver Profiles be able to handle the the high volume of of queries per second (QPS) it might encounter in production. Leveraging our load and integration test platform, Hailstorm, we threw about 3,000 QPS at the six Docker instances (500 QPS each) we allocated for our service, and were able to handle the load seamlessly and with minimal friction.
Since those initial Hailstorm tests, we have scaled much, much further. Currently, we are serving just over 100K QPS, and due in large part to our forward-looking architecture, we have only had to add a handful of new machines to support the microservice.

Beyond Driver Profiles
The design and architecture decisions we made while building Driver Profiles have facilitated a fun and engaging social platform for our users. On the technical side, we are eager to continue to enhance trip experiences by building more features on top of the microservice.
Celebrate drivers by checking out Driver Profiles on your next trip!
Kurtis Nusbaum is a software engineer on Uber’s Driver Signups team, working primarily on back-end systems and Android. In his spare time, he serves as CTO for Dev/Mission and enjoys long distance running.

Kurtis Nusbaum
Kurtis Nusbaum is a Senior Staff Engineer on the Uber Infrastructure team in Seattle. He works on highly-reliable distributed systems for managing Uber’s server fleet.
Posted by Kurtis Nusbaum
Related articles





Most popular

How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache

Ensuring Precision and Integrity: A Deep Dive into Uber’s Accounting Data Testing Strategies

Building Scalable, Real-Time Chat to Improve Customer Experience

DragonCrawl: Generative AI for High-Quality Mobile Testing
Products
Company
