
At Uber, we apply neural networks to fundamentally improve how we understand the movement of people and things in cities. Among other use cases, we employ them to enable faster customer service response with natural language models and lower wait times via spatiotemporal prediction of demand across cities, and in the process have developed infrastructure to scale up training and support faster model development.
Though neural networks are powerful, widely used tools, many of their subtle properties are still poorly understood. As scientists around the world make strides towards illuminating fundamental network properties, much of our research at Uber AI aligns in this direction as well, including our work measuring intrinsic network complexity, finding more natural input spaces, and uncovering hidden flaws in popular models.
In our most recent paper aimed at demystifying neural networks, Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask, we build upon the fascinating Lottery Ticket Hypothesis developed by Frankle and Carbin. Their work surprised many researchers by showing that a very simple algorithm—delete small weights and retrain—can find sparse trainable subnetworks, or “lottery tickets”, within larger networks that perform as well as the full network. Although they clearly demonstrated lottery tickets to be effective, their work (as often occurs with great research) raised as many questions as it answered, and many of the underlying mechanics were not yet well understood. Our paper proposes explanations behind these mechanisms, uncovers curious quirks of these subnetworks, introduces competitive variants of the lottery ticket algorithm, and derives a surprising by-product: the Supermask.
The Lottery Ticket Hypothesis
We begin by briefly summarizing Frankle and Carbin’s paper, The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, which we abbreviated as “LT”. In this paper, the authors proposed a simple approach for producing sparse, performant networks: after training a network, set all weights smaller than some threshold to zero (prune them), rewind the rest of the weights to their initial configuration, and then retrain the network from this starting configuration keeping the pruned weights weights frozen (not trained). Using this approach, they obtained two intriguing results.
First, they showed that the pruned networks performed well. Aggressively pruned networks (with 85 percent to 95 percent of weights pruned) showed no drop in performance compared to the much larger, unpruned network. Moreover, networks only moderately pruned (with 50 percent to 90 percent of weights pruned) often outperformed their unpruned counterparts.
Second, as compelling as these results were, the characteristics of the remaining network structure and weights were just as interesting. Normally, if you take a trained network, re-initialize it with random weights, and then re-train it, its performance will be about the same as before. But with the skeletal Lottery Ticket (LT) networks, this property does not hold. The network trains well only if it is rewound to its initial state, including the specific initial weights that were used. Reinitializing it with new weights causes it to train poorly. As pointed out in Frankle and Carbin’s study, it would appear that the specific combination of pruning mask (a per-weight binary value indicating whether or not to delete the weight) and weights underlying the mask form a lucky sub-network found within the larger network, or, as named by the original study, a winning “Lottery Ticket.”
We found this demonstration intriguing because of all left untold. What about LT networks causes them to show better performance? Why are the pruning mask and the initial set of weight so tightly coupled, such that re-initializing the network makes it less trainable? Why does simply selecting large weights constitute an effective criterion for choosing a mask? Would other criteria for creating a mask work, too?
Curiously effective masks
We start our investigation with the observation of a curious phenomenon that demands explanation. While training LT networks, we observed that many of the rewound, masked networks had accuracy significantly better than chance at initialization. That is, an untrained network with a particular mask applied to it results in a partially working network.
This might come as a surprise, because if you use a randomly initialized and untrained network to, say, classify images of handwritten digits from the MNIST dataset, you would expect accuracy to be no better than chance (about 10%). But now imagine you multiply the network weights by a mask containing only zeros and ones. In this instance, weights are either unchanged or deleted entirely, but the resulting network now achieves nearly 40 percent accuracy at the task! This is strange, but it is exactly what happens when applying masks created using the procedure in the LT paper that selects weights with large final values (which we will call the “large final” mask criterion):
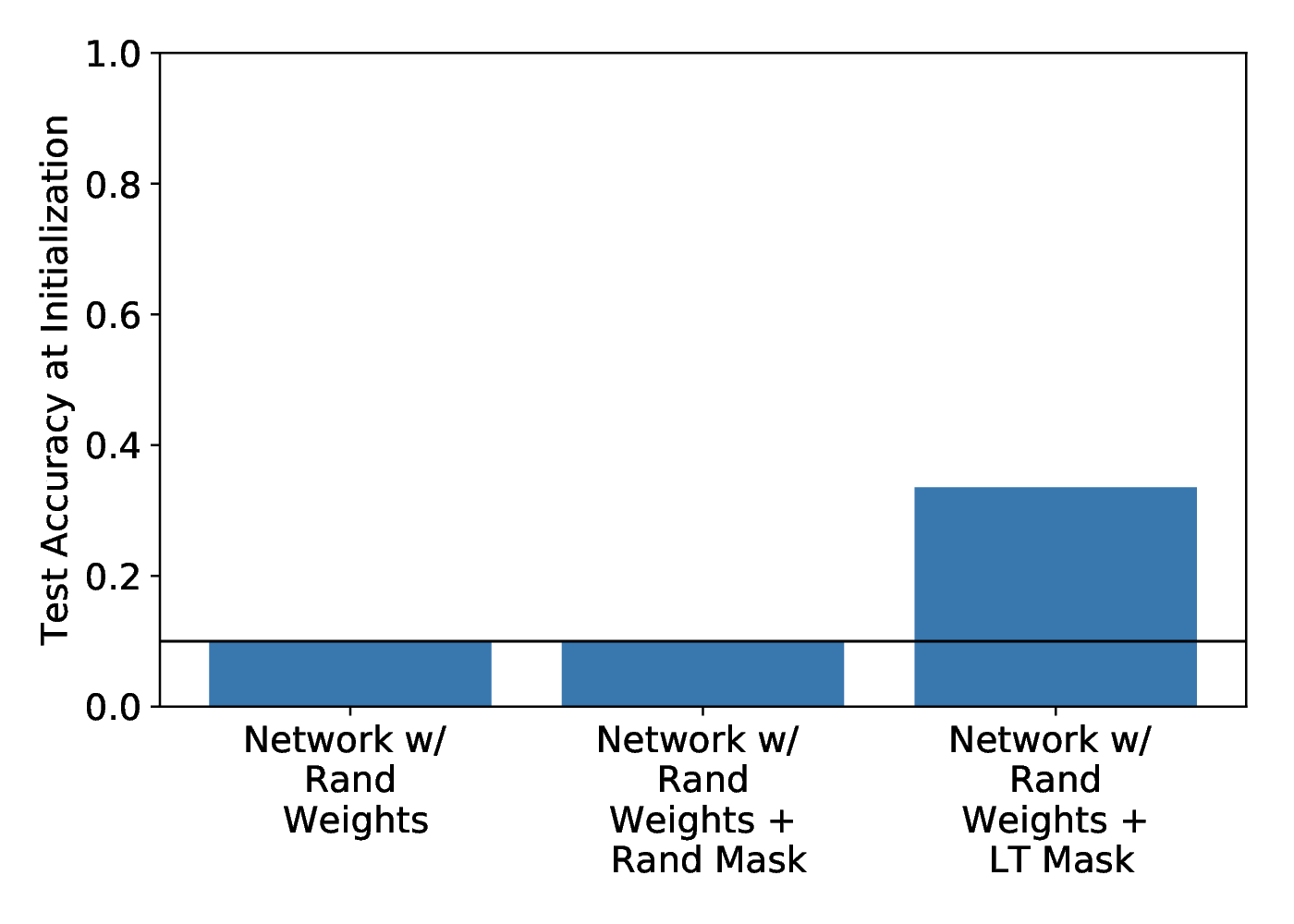
We call masks with the property that they immediately produce partially working networks without training of the underlying weights Supermasks.
As depicted in Figure 1, in randomly-initialized networks and randomly-initialized networks with random masks, neither weights nor the mask contain any information about the labels, so accuracy cannot reliably be better than chance. In randomly-initialized networks with LT “large final” masks, it is not entirely implausible to have better-than-chance performance since the masks are indeed derived from the training process. But it was unexpected since the only transmission of information from the training back to the initial network is via a zero-one mask, and the criterion for masking simply selects weights with large final magnitudes.
Masking is training, or why zeros matter
So why do we see a large improvement in test accuracy from simply applying an LT mask?
The masking procedure as implemented in the LT paper performs two actions: it sets weights to zero, and it freezes them. By figuring out which of these two components leads to increased performance in trained networks, it turns out we’ll also uncover the principles underlying the peculiar performance of the untrained networks.
To separate the above two factors, we run a simple experiment: reproduce the LT iterative pruning experiments in which network weights are masked out in alternating train/mask/rewind cycles, but try an additional treatment: freeze zero-masked weights at their initial values instead of at zero. If zero isn’t special, both treatments should perform similarly. We follow Frankle and Carbin (2019) and train three convolutional neural networks (CNNs), Conv2, Conv4, and Conv6 (small CNNs with 2/4/6 convolutional layers, same as used in the LT paper), on CIFAR-10.
Results are shown in Figure 2, below, with pruning (or more correctly, “freezing at some value”) progressing from unpruned on the left to very pruned networks on the right. The horizontal black lines represent the performance of the original, unpruned networks, averaged over five runs. The uncertainty bands here and in other figures represent minimum and maximum values over five runs. Solid blue lines represent networks trained using the LT algorithm, which sets pruned weights to zero and freezes them. Dotted blue lines represent networks trained using the LT algorithm except that pruned weights are frozen at their initial values:
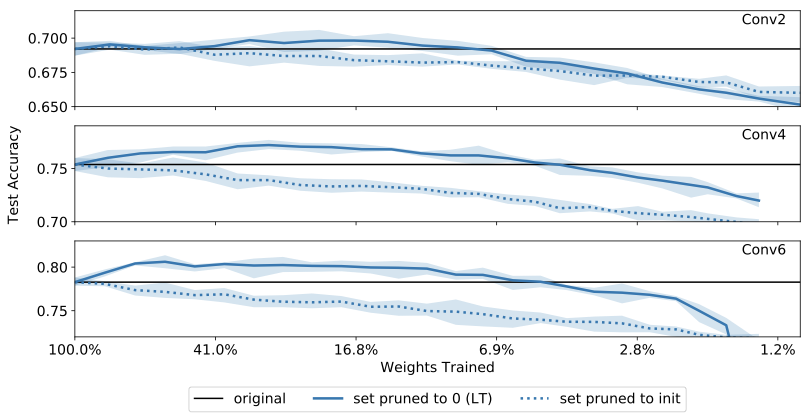
We see that networks perform better when weights are frozen specifically at zero rather than at random initial values. For these networks masked via the LT “large final” criterion, zero would seem to be a particularly good value to set weights to when they had small final values.
So why is zero an ideal value? One hypothesis is that the mask criterion we use tends to mask to zero those weights that were headed toward zero anyway. To test out this hypothesis, let’s consider a new approach to freezing. We run another experiment interpolated between the previous two: for any weight to be frozen, we freeze it to zero if it moved toward zero over the course of training, and we freeze it at its random initial value if it moved away from zero. Results are shown in Figure 3, below:
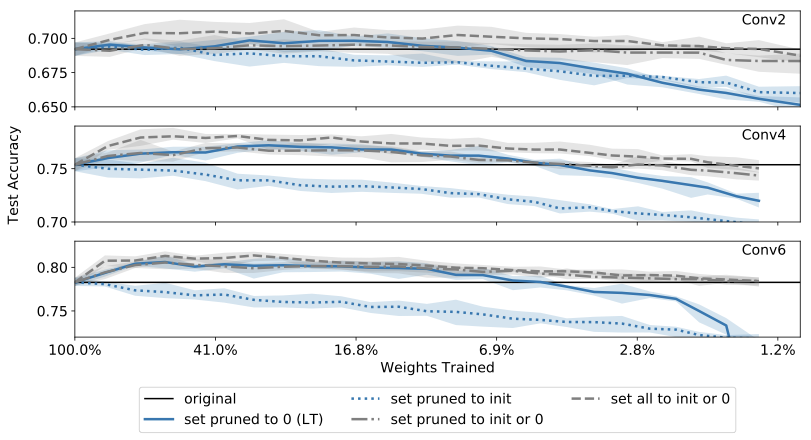
We see that this treatment performs just as well as the original LT networks, even though we did not freeze all the pruned weights to zero. In fact, if we apply this treatment to all weights, including weights we keep (that is, for all weights, initialize them at zero if they decreased in magnitude and keep their original initial values otherwise, then freeze pruned weights at their new initialization values), we get networks that perform even better than the LT networks!
This supports our hypothesis that the benefit derived from freezing values to zero comes from the fact that those values were moving toward zero anyway. For a deeper discussion of why the “large final” mask criterion biases toward selecting those weights heading toward zero, see our paper.
Thus we find for certain mask criteria, like “large final”, that masking is training: the masking operation tends to move weights in the direction they would have moved during training.
This simultaneously explains why Supermasks exist and hints that other mask criteria may produce better Supermasks if they preferentially mask to zero weights that training drives toward zero.
Alternate mask criteria
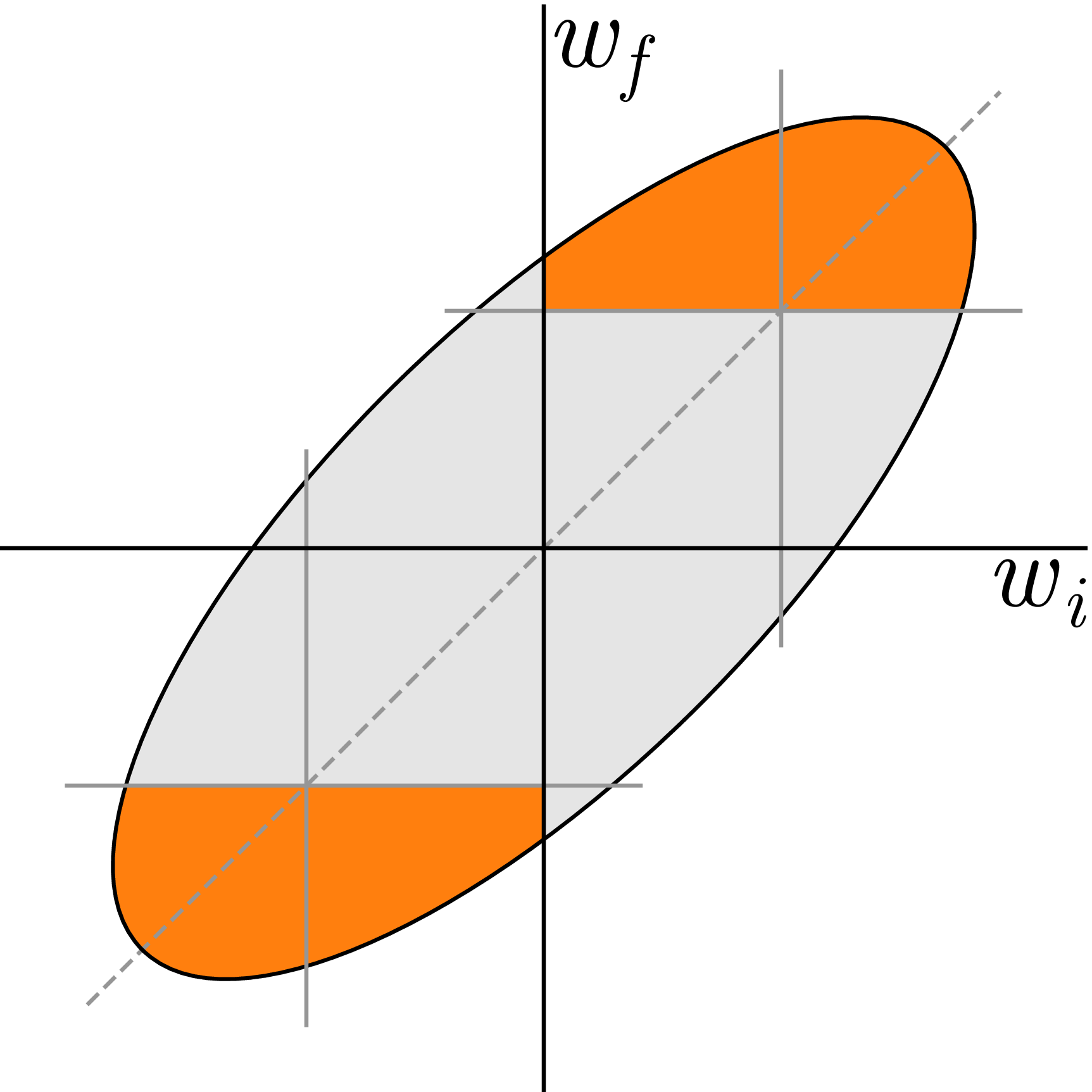
Now that we’ve explored why the original LT mask criterion, “large final,” works as well as it does, we can ask what other masking criteria would also perform well. The “large final” criterion keeps weights with large final magnitudes and sets the rest to zero. We can think of this pruning criterion and many others as a division of the 2D (wi = initial weight, wf = final weight) space into regions corresponding to weights that should be kept (mask-1) vs. pruned (mask-0), as shown in Figure 5, below:
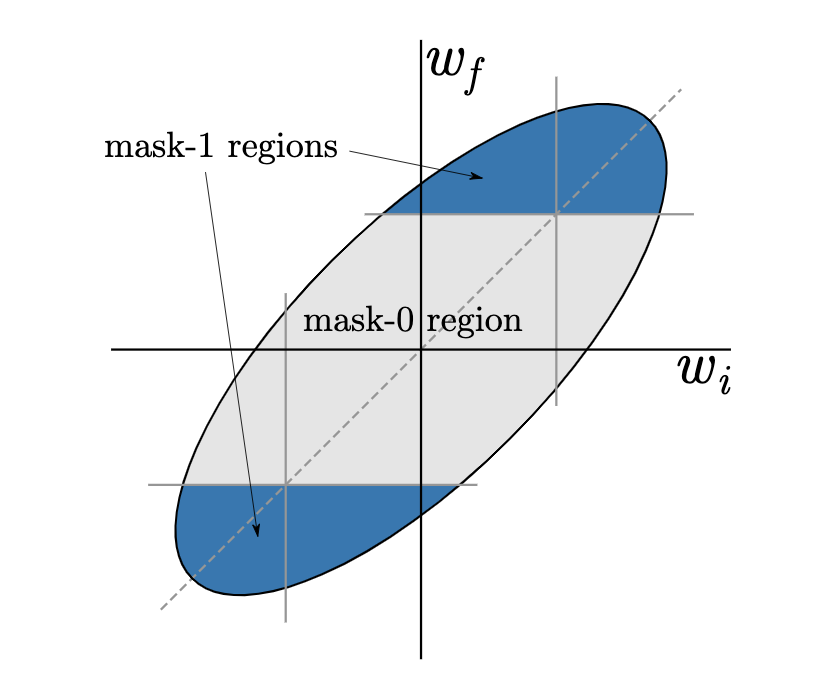
In the previous section, we showed some supporting evidence for the hypothesis that networks work well when those weights already moving toward zero are set to zero. This hypothesis suggests that other criteria may also work if they respect this basic rule. One such mask criterion is to preferentially keep those weights that move most away from zero, which we can write as the scoring function |wf| – |wi|. We call this criterion “magnitude increase” and depict it along with other criteria run as control cases in Figure 6, below:

This “magnitude increase” criterion turns out to work just as well as the “large final” criterion, and in some cases significantly better. Results of all criteria are shown in Figure 7, below, for the fully connected (FC) and Conv4 networks; see our paper for performance results on other networks. As a baseline, we also show results on a random pruning criterion that simply chooses a random mask with the desired pruning percentage. Note that the first six criteria out of the eight form three opposing pairs; in each case, we see when one member of the pair performs better than the random baseline, the opposing member performs worse than it.
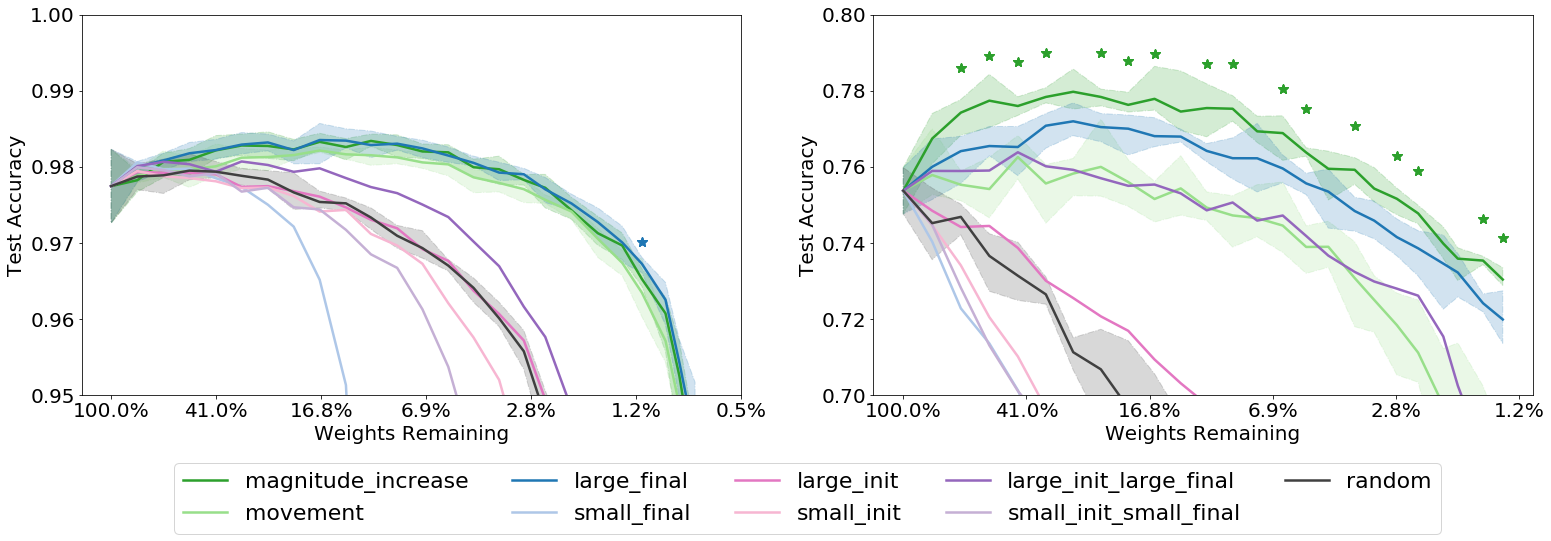
In general, we observe that those methods that bias towards keeping weights with large final magnitude are able to uncover performant subnetworks.
Show me a sign
We have explored various ways of choosing which weights to prune and what values to set pruned weights to. We will now consider what values to set kept weights to. In particular, we want to explore an interesting observation in Frankle and Carbin (2019) which showed that the pruned, skeletal LT networks train well when you rewind to its original initialization, but degrades in performance when you randomly reinitialize the network.
Why does reinitialization cause LT networks to train poorly? Which components of the initialization are important?
We evaluate a number of variants of reinitialization to find out the answer.
- “Reinit” experiments: reinitialize kept weights based on the original initialization distribution
- “Reshuffle” experiments: reinitializing while respecting the original distribution of remaining weights in that layer, which is achieved by reshuffling the kept weights’ initial values
- “Constant” experiments: reinitializing by setting remaining weights values to a positive or negative constant, with the constant set to be the standard deviation of each layer’s original initialization
All of the reinitialization experiments are based on the same original networks and use the “large final” mask criterion with iterative pruning. We include the original LT network (rewind, large final) and the randomly pruned network (random) as baselines for comparison.
We find that none of these three variants alone are able to train as well as the original LT network, as shown in dashed lines in Figure 8 below:
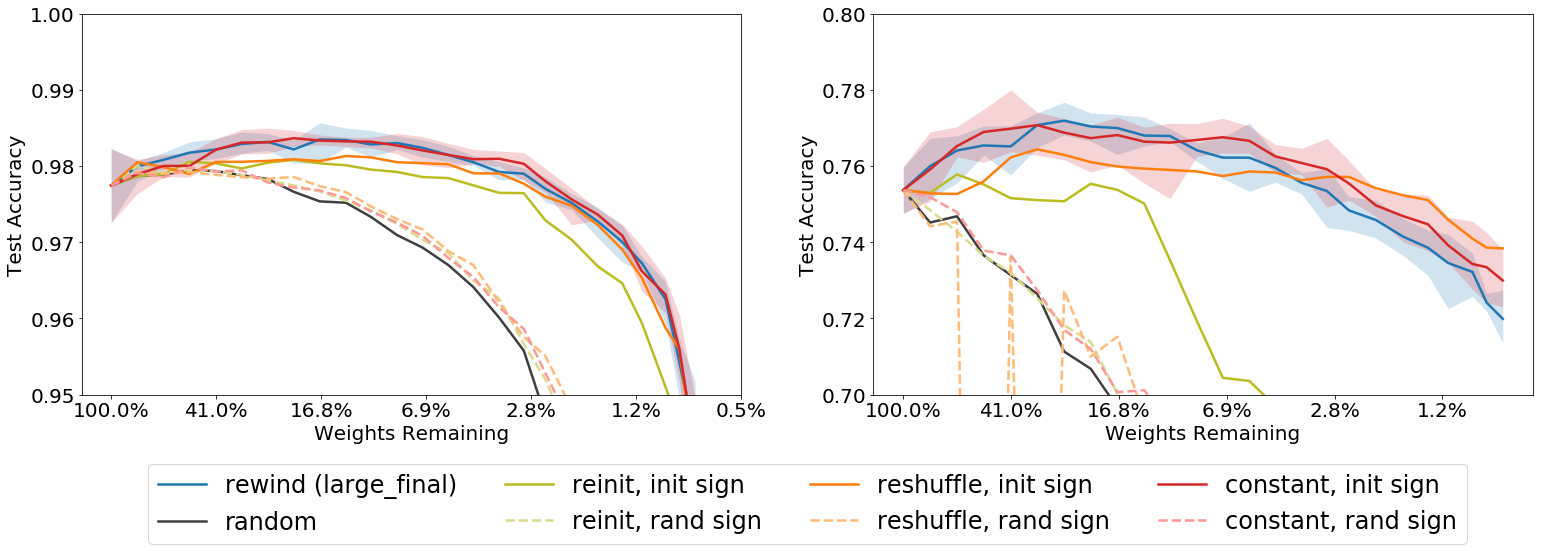
However, all three variants work better when we control the consistency of sign by ensuring that the reassigned values of the kept weights are of the same sign as their original initial values. These are shown as solid color lines in Figure 8. Clearly, the common factor in all the variants that perform better than chance, including the original “rewind”, is the sign. This suggests that reinitialization is not the deal breaker as long as you keep the sign. In fact, as long as we respect the original sign, even as simple as setting all kept weights to a constant value consistently performs well!
Better Supermasks
At the beginning of the article we introduced the idea of Supermasks, which are binary masks that when applied to a randomly initialized network, produce better-than-chance accuracy without additional training. We now turn our attention to finding methods that would produce the best Supermasks.
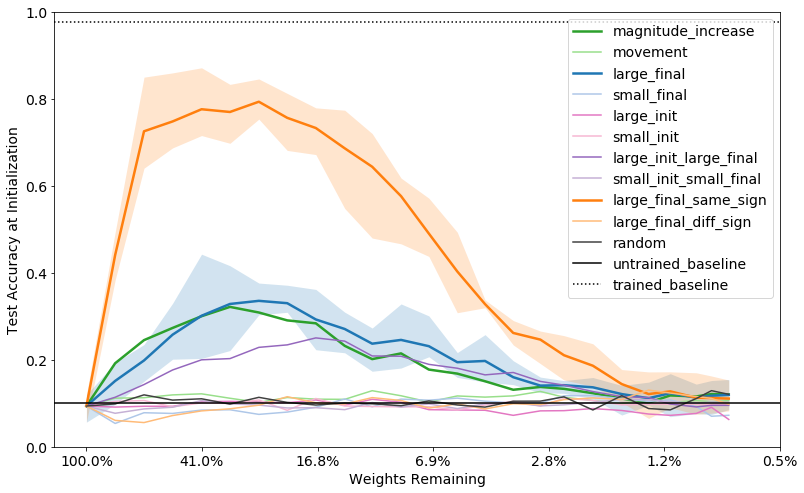
We can evaluate the same pruning methods and pruning percentages seen in Figure 7 for their potential as Supermasks. For simplicity, we evaluate Supermasks based on one-shot pruning rather than iterative pruning. We can also consider additional mask criteria optimized for generating Supermasks. Based on the insight about the importance of the initial sign of LT weights and the idea of having weights close to their final values, we introduce a new mask criterion that selects for weights with large final magnitudes that also maintained the same sign at the end of training. This method is referred to as “large final, same sign”, and we depict it in Figure 9, below. We also add “large final, diff sign” as a control case, which looks for weights that changed sign at the end of training.
By using a simple mask criterion of “large final same sign”, we can create networks that obtain a remarkable 80 percent test accuracy on MNIST and 24 percent on CIFAR-10 without training. Another curious observation is that if we apply the mask to a signed constant (as described in the previous section) rather than the actual initial weights, we can produce even higher test accuracy of up to 86 percent on MNIST and 41 percent on CIFAR-10.
We find it fascinating that these Supermasks exist and can be found via such simple criteria. Besides being a scientific curiosity, they could have implications for transfer learning and meta-learning — networks to approximately solve, say, any permutation of MNIST input pixels and permutation of output classes are all in there, just with different masks. They also present us with a method for network compression, since we only need to save a binary mask and a single random seed to reconstruct the full weights of the network.
If you’re curious how far we can push the performance of these Supermasks, check out our paper where we try training for them directly. If you’d like to run experiments similar to this paper, check out our code and let us know what you find!
If working with neural networks interests you, consider applying for a machine learning role at Uber.
The authors would like to acknowledge Jonathan Frankle, Joel Lehman, and Sam Greydanus for combinations of helpful discussion and comments on early drafts of this work.

Hattie Zhou
Hattie Zhou is a data scientist with Uber's Marketing Analytics team.

Janice Lan
Janice Lan is a research scientist with Uber AI.

Rosanne Liu
Rosanne is a senior research scientist and a founding member of Uber AI. She obtained her PhD in Computer Science at Northwestern University, where she used neural networks to help discover novel materials. She is currently working on the multiple fronts where machine learning and neural networks are mysterious. She attempts to write in her spare time.

Jason Yosinski
Jason Yosinski is a former founding member of Uber AI Labs and formerly lead the Deep Collective research group.
Posted by Hattie Zhou, Janice Lan, Rosanne Liu, Jason Yosinski
Related articles





Most popular

Building Scalable, Real-Time Chat to Improve Customer Experience

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program
Products
Company
