Consistent Data Partitioning through Global Indexing for Large Apache Hadoop Tables at Uber
April 23, 2019 / Global
Data serves little purpose if we cannot find it. Looking up individual records in the 100-plus petabytes of data accumulated at Uber lets us perform updates and gather useful insights to help improve our services, such as delivering more accurate ETAs to riders and showing eaters their favorite food options. Querying data at this scale and delivering results in a timely fashion is no simple task, but it is essential so that teams at Uber can get the insights they need to deliver seamless and magical experiences to our customers.
To support these insights, we built Uber’s Big Data platform by decoupling storage and query layers so each could be scaled independently. We store analytical datasets on HDFS, register them as external tables, and serve them using query engines such as Apache Hive, Presto, and Apache Spark. This Big Data platform enables reliable and scalable analytics for the teams that oversee the accuracy and continuous improvement of our services.
Over the lifetime of a trip at Uber, new information gets updated to a trip datum during events such as trip creation, trip duration update, and rider review updates. Supporting an update requires looking up the location of data before modifying and persisting it. As the scale of these lookups increased to millions of operations per second, we found that open source key-value stores were unable to meet our scalability requirements out of the box–they either compromise on throughput or correctness.
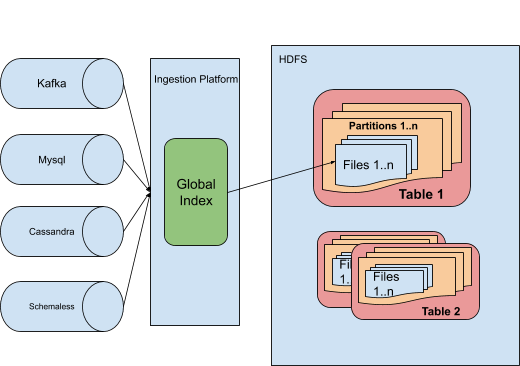
In order to reliably and consistently find the location of data, we developed a component called the Global Index. This component performs bookkeeping and lookup of the location of data in Hadoop tables. It provides high throughput, strong consistency and horizontal scalability, and facilitates our ability to update petabytes of data in Hadoop tables. In this article, we expand upon our existing Big Data series by explaining the challenges involved in solving this problem at a large scale and share how we leverage open source software in the process.
Ingestion workload types
Uber’s Hadoop data can be broadly classified into two types: append-only and append-plus-update. Append-only data represents immutable events. In Uber terms, immutable events might consist of a trip’s payment history. Append-plus-update data shows the latest state of an entity at any given point in time. For example, in the instance of the end time of a trip, where trip is the entity and the end time is an update to the entity, the end time is an estimation which can change until the trip is completed.
Ingestion of append-only data does not require context on any previous value since each event is independent. Ingesting append-plus-update data into datasets, however, is different. Although we receive updates only on part of the data that is actually modified, we still need to present the most recent and complete snapshot of the trip.
Append-plus-update workloads
Building datasets typically consists of two phases: bootstrap and incremental. During the bootstrap phase, large amounts of historical data from the upstream are ingested in a short period of time. This phase generally occurs when we first onboard a dataset or when a dataset needs to be re-onboarded for maintenance. The incremental phase involves consuming recent, incremental upstream changes and applying them to the dataset. This phase usually dominates the remaining life cycle of a dataset and ensures that the data is up-to-date as the upstream source evolves.
In its basic form, data ingestion is about organizing data to balance efficient reading and writing of newer data. Data organization for efficient reading involves factoring query patterns to partition data in such a way that minimal data is read. Since analytical datasets tend to be read multiple times, datasets are partitioned to avoid scanning the entire dataset. For efficient writing, the data layout is spread across multiple files within partitions to leverage high parallelism during writes, and in case of any future updates to data, limiting write footprints only to the files containing these updates.
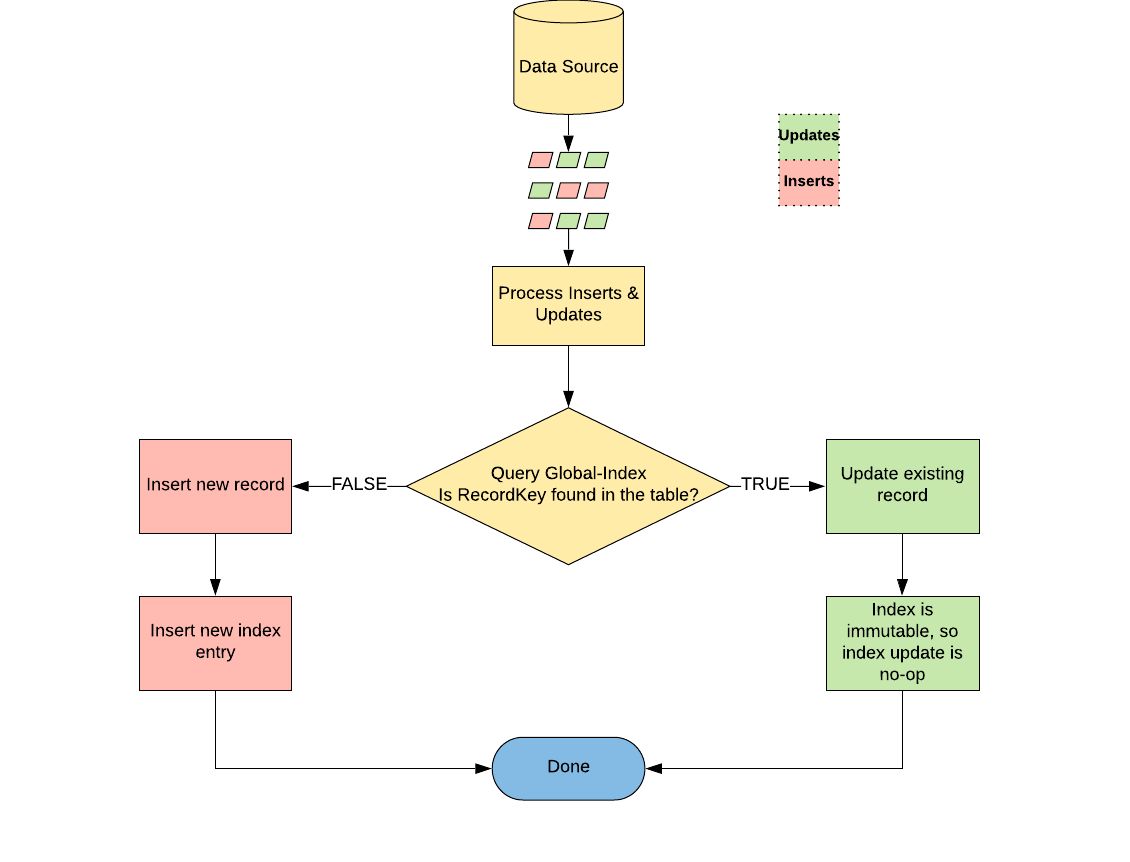
Another aspect of improving write efficiency with updates is to develop a component for the efficient lookup of the location of existing data within our Big Data ecosystem. Global index, an ingestion component, maintains bookkeeping information of the data layout. This component requires strong consistency to correctly categorize incoming data as inserts or updates. Upon categorization, inserts, such as our new trip, are grouped and written to new files, while updates, such as the end time for a trip, are written to the corresponding pre-existing files identified by the global index, as depicted in Figure 1, below:
Following is an architectural overview of how Global Index contributes to our ingestion system.
A straightforward solution for global indexing would be using a proven key-value store such as HBase or Cassandra. Such key-value stores can support hundreds of thousands of requests per second for strongly consistent read/writes.
For large datasets, throughput requirements are very high during the bootstrapping phase (on the order of millions of requests per second per dataset) since large amounts of data need to be ingested in a relatively short period of time. Throughput requirements during the bootstrap phase for a large dataset at Uber is on the order of millions of requests per second. During the incremental phase however, throughput requirements are much lower (on the order of thousands of requests per second per dataset), barring occasional peaks which can be controlled by request rate throttling.
High scale index read/writes, strong consistency, and reasonable index read/write amplifications are additional requirements of a global index. If we divide the problem by handling bootstrap phase and incremental phase indexing separately, we could use a key-value store that scales to address incremental phase indexing, but not necessarily for bootstrap phase indexing. To understand why this is, let’s consider how the incremental and bootstrap phases differ in terms of workloads.
Indexing during bootstrap ingestion
If during the bootstrap phase the source data was organized such that the input data was guaranteed to be all inserts (as depicted in Figure 1), there is no need for global indexing. In the incremental phase, however, we cannot ensure that incoming data is composed of only inserts, since we have to ingest data at regular intervals and updates to rows could arrive at any interval. Hence, a key-value store needs to be updated with indexes before we begin the incremental phase
We use this property to design our bootstrap ingestion. Due to the limited request throughput of key-value stores, we generate indexes from the dataset and bulk upload them to a key-value store without issuing individual write requests, thereby avoiding the typical write path.
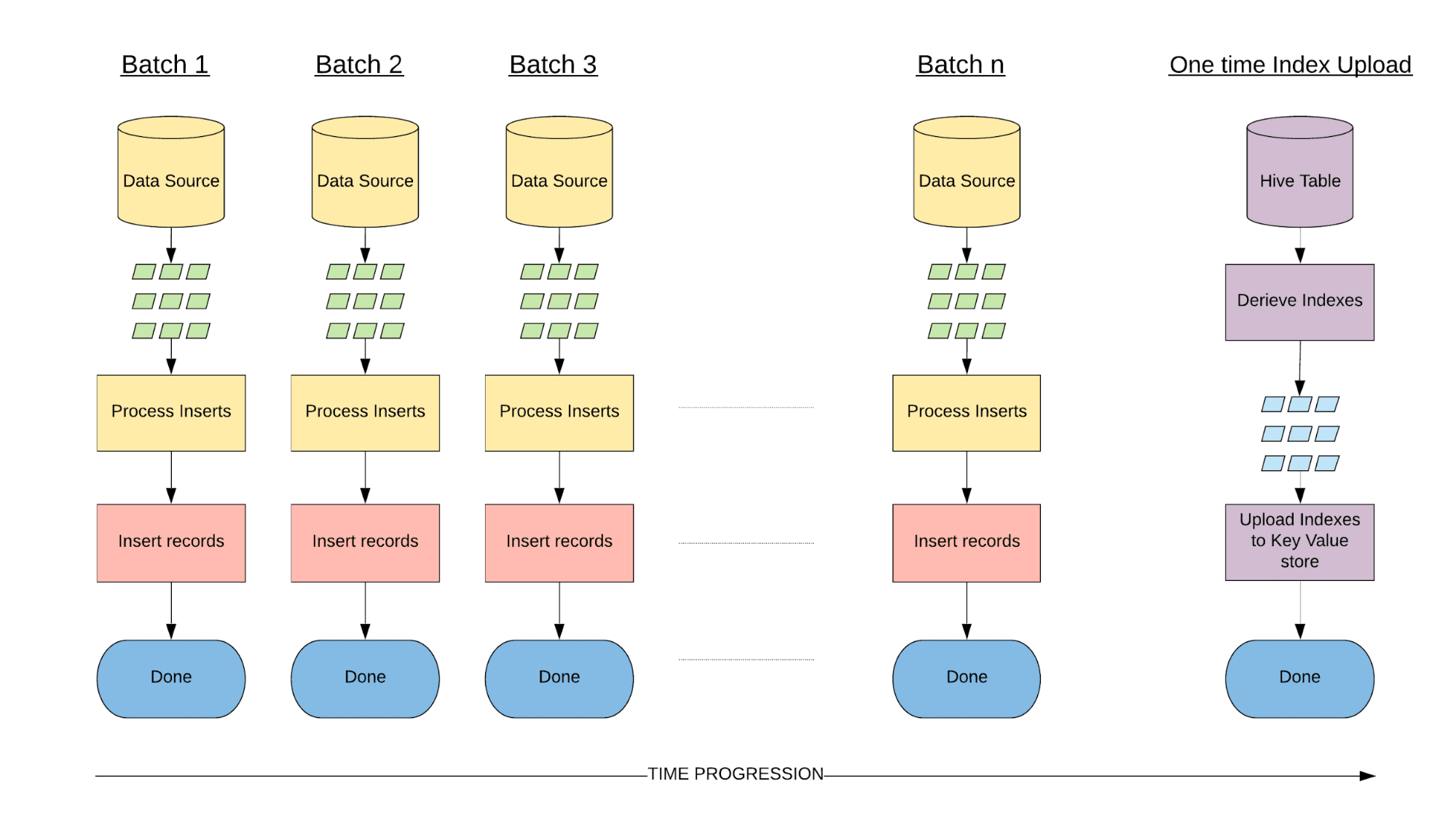
Choosing a suitable key-value store
Based on the above simplifications, the requirements of a key-value store for the purpose of indexing during the incremental phase are strongly consistent reads/writes, the ability to scale to thousands of requests per second per dataset, and a reliable way to bulk upload indexes (i.e., avoiding the limited throughput in the write path).
HBase and Cassandra are two key value stores widely used at Uber. For our global indexing solution, we chose to use HBase for the following reasons:
- Unlike Cassandra, HBase only permits consistent reads and writes, so there is no need to tweak consistency parameters.
- HBase provides automatic rebalancing of HBase tables within a cluster. The master-slave architecture enables getting a global view of the spread of a dataset across the cluster, which we utilize in customizing dataset specific throughputs to our HBase cluster.
Generating and uploading indexes with HFiles
We generate indexes in HBase’s internal storage file format, referred to as HFile, and upload them to our HBase cluster. HBase partitions data based on sorted, non-overlapping key ranges across regional servers in the HFile file format. Within each HFile, data is sorted based on the key value and the column name. To generate HFiles in the format expected by HBase, we use Apache Spark to execute large, distributed operations across a cluster of machines.
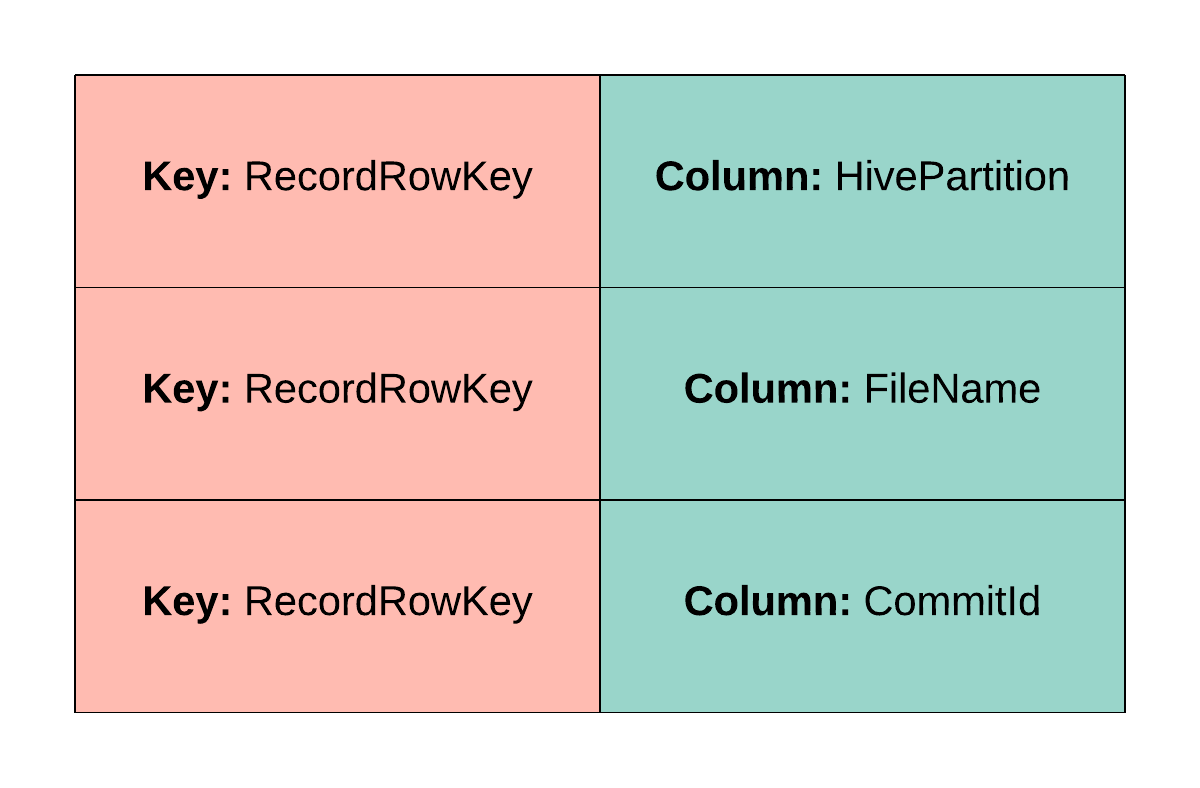
Index information is first extracted as a resilient distributed dataset (RDD), shown in Figure 4, below, from the bootstrapped dataset and then globally sorted based on the value of the key using RDD.sort().

We layout the RDD in such a way that each Apache Spark partition is responsible for writing out one HFile independently. Within each HFile, HBase expects the contents to be laid out as shown in Figure 5, below, such that they are sorted based on a key value and column name.
RDD.flatMapToPair() transformation is then applied to the RDD to organize data in the layout shown in Figure 5. This transformation, however, does not preserve the ordering of entries in the RDD, so we perform a partition-isolated sort using RDD.repartitionAndSortWithinPartitions() without any change to partitioning. It is important to not change the partitioning since each partition has been chosen to represent the contents of an HFile. The resulting RDD is then saved using HFileOutputFormat2. Using this approach, HFile generation for some of our largest datasets, with index sizes in the tens of terabytes, takes less than two hours.
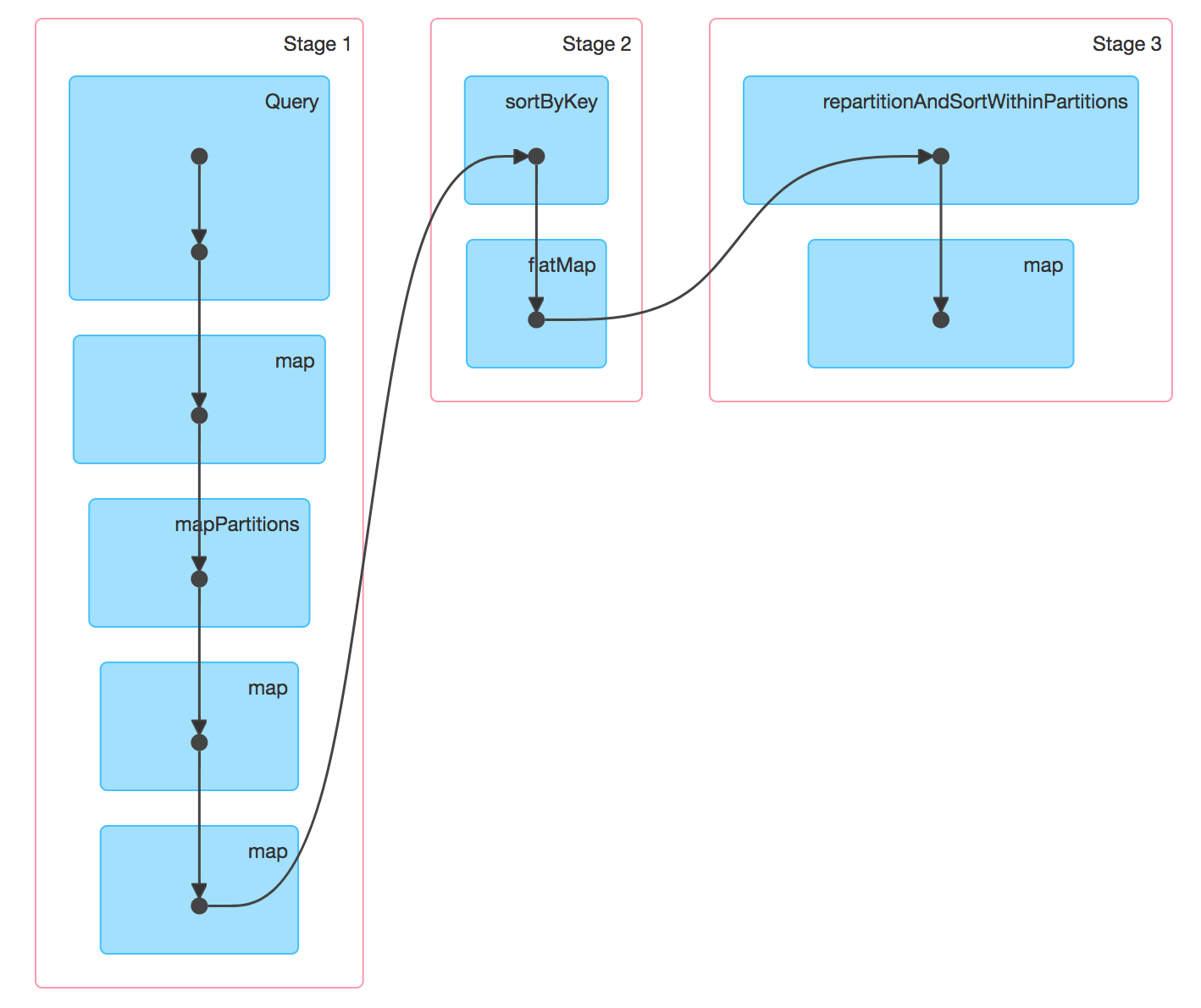
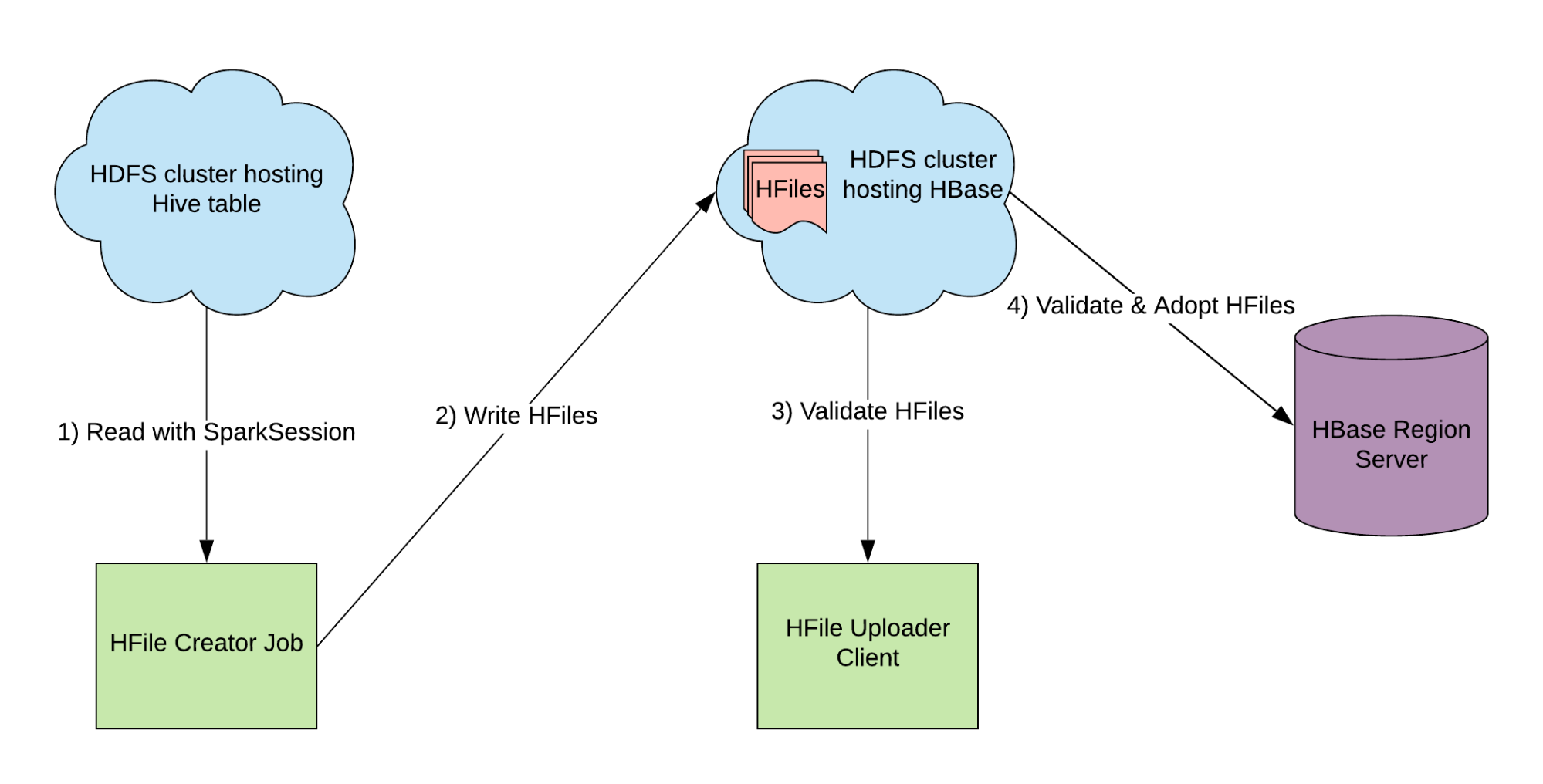
HFiles are now uploaded to HBase using a utility called LoadIncrementalHFiles. A process called HFile-splitting is triggered during upload by HBase if there is no pre-existing region that completely contains the key range in an HFile, or if the HFile size is bigger than a set threshold.
HFile upload latency can be severely affected by splitting, since this process requires rewriting the entire HFile. We avoid HFile splitting by reading HFile key ranges and pre-splitting the HBase table into as many regions as there are HFiles, so that each HFile can fit into a region. Reading just the HFile key range is cheaper by orders of magnitude than rewriting the whole file since HFile key ranges are stored within header blocks. For some of our largest datasets, with index size in the tens of terabytes, HFile upload takes less than an hour.
Indexing during incremental ingestion
Once an index is generated, the mapping between each row key and file ID does not change. Instead of writing the index for all records in our ingestion batch, we write the index only for inserts. This helps us keep the write requests to HBase within limits and meet our required throughput.
Throttling HBase access
As discussed earlier, HBase does not scale beyond a certain load. During the incremental phase, there are occasional load peaks, so we need to throttle access to HBase. Figure 8, below, shows how HBase is concurrently accessed by multiple independent ingestion jobs:
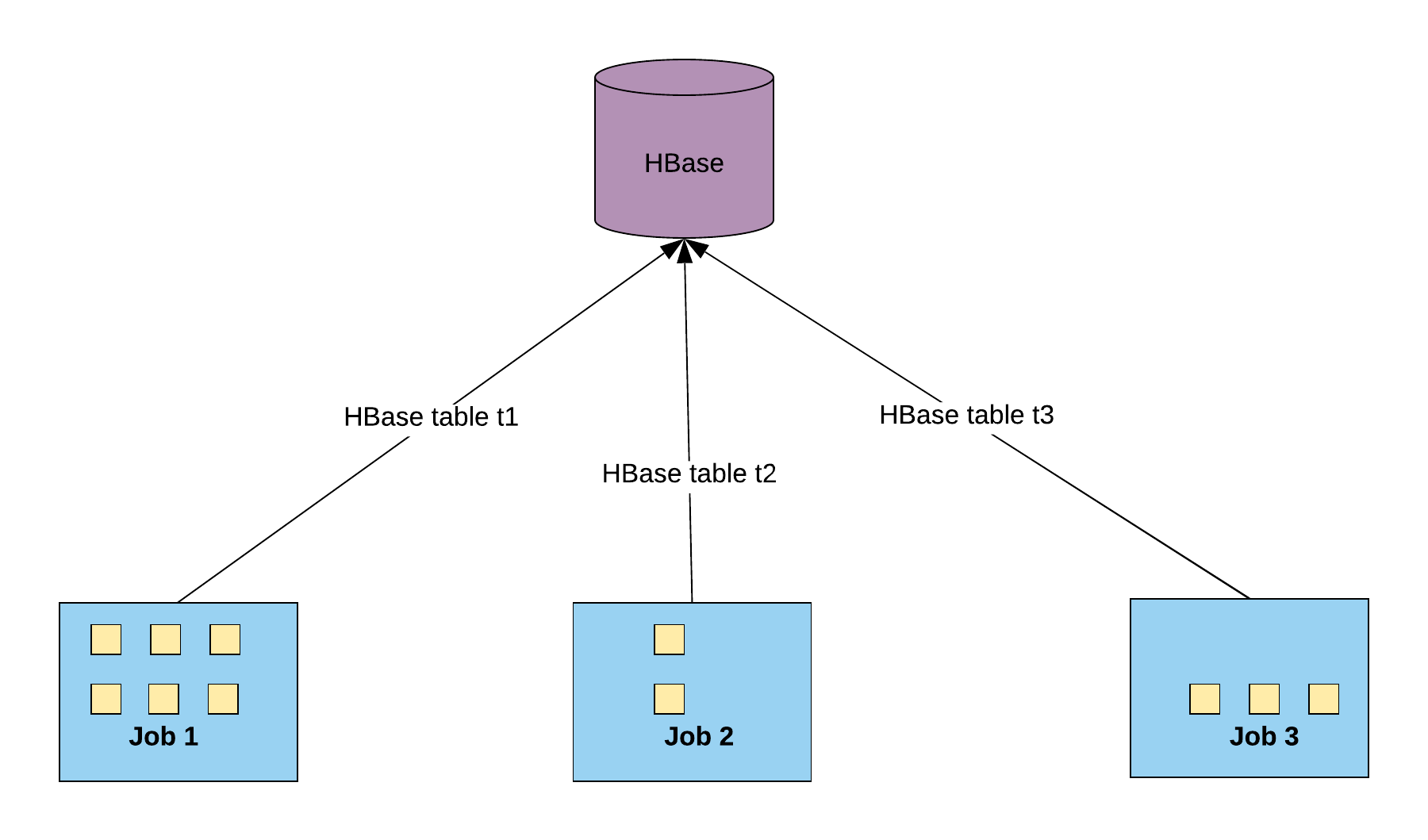
We control cumulative writes per second to a regional server from independent Apache Spark jobs based on a few factors that affect the number of requests to Hbase:
- Job parallelism: The number of parallel requests to HBase within a job.
- Number of regional servers: The number of servers hosting the particular HBase index table.
- Input QPSFraction: The fraction of cumulative QPS across datasets. Typically this number is a weighted average of number of rows in a dataset to ensure fair share of QPS across datasets.
- Internal benchmarked QPS: The QPS that a regional server can handle.
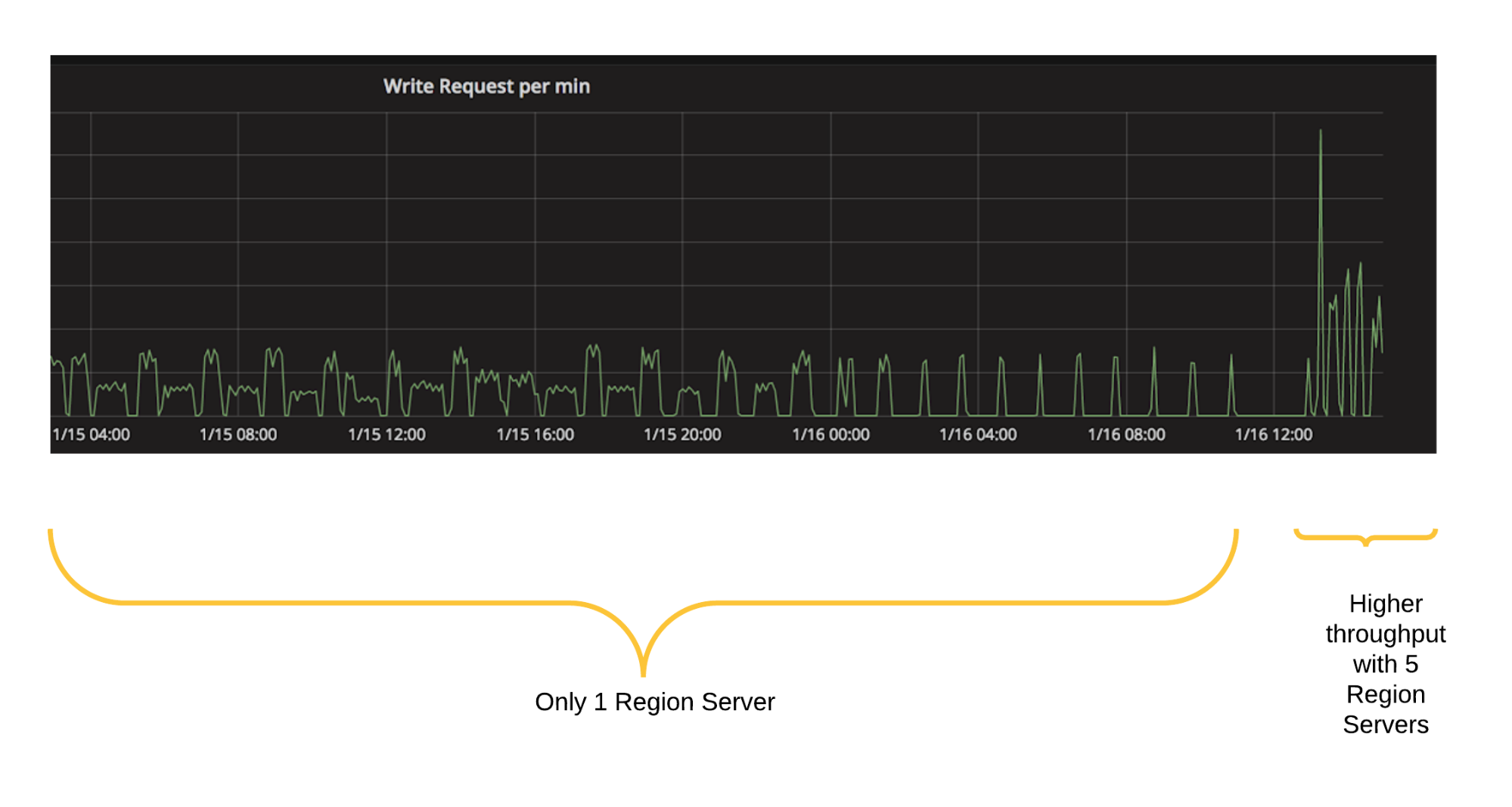
Figure 9, below, shows an experiment on how the throttling algorithm adjusts to handle more queries as HBase region servers are added to the HBase cluster.
System limitations
Although our global indexing system has facilitated greater data reliability and consistency, there are a few limitations of our system, as described below:
- Referring to the CAP theorem, HBase provides consistency and partition-tolerance, but does not offer 100 percent availability. Since ingestion jobs are not extremely time sensitive, we can have a more relaxed service level agreement in the rare event of HBase down time.
- The throttling process assumes that the index table is uniformly distributed across all regional servers. This may not be true for datasets that contain a small number of indexes. As such, they end up getting smaller share of QPS, which we compensate by bumping their QPSFraction.
- Requires a disaster recovery mechanism if indexes in HBase are corrupted or if the table becomes unavailable due to a disaster. Our current strategy is to reuse the same process discussed earlier in generating indexes from a dataset and uploading to a new HBase cluster.
Next steps
Our global indexing solution keeps up with petabytes of data running through Uber’s Big Data platform, meeting our SLAs and requirements. However, there are a few improvements we are considering:
- For instance, we simplified the problem of global indexing during the bootstrap ingestion phase by ensuring ingested data is append-only, but this may not work for all datasets. Hence, we need a solution that addresses this at scale.
- We would like to explore an indexing solution that would eliminate the need for an external dependency such as a key-value store, like HBase.
Please email your resume to hadoop-platform-jobs@uber.com if you are interested in working with us!

Nishith Agarwal
Nishith Agarwal currently leads the Hudi project at Uber and works largely on data ingestion. His interests lie in large scale distributed systems. Nishith is one of the initial engineers of Uber’s data team and helped scale Uber's data platform to over 100 petabytes while reducing data latency from hours to minutes.

Kaushik Devarajaiah
Kaushik Devarajaiah is the Tech Lead for LedgerStore at Uber. His primary focus is building distributed gateways and databases that scale with Uber's hyper-growth. Previously, he worked on scaling Uber's Data Infrastructure to handle over 100 petabytes of data. Kaushik holds a master's degree in Computer Science from SUNY Stony Brook University.
Posted by Nishith Agarwal, Kaushik Devarajaiah
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global




Most popular

A beginner’s guide to Uber vouchers for transit agency riders

Uber Earner x Miami HEAT Ticket Sweepstakes OFFICIAL RULES

Case study: Tri-Rail’s role in paving the way for effortless commuting

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
