Improving the User Experience with Uber’s Customer Obsession Ticket Routing Workflow and Orchestration Engine
March 28, 2019 / Global
Every day, Uber users around the world initiate customer support tickets through our Customer Obsession Platform. To ensure a seamless user experience, each of those tickets must be matched with an agent who speaks the user’s language and who has been trained to handle issues of that type and in that country, among other qualifications.
Routing tickets to an agent with the right skillset has become more complex as Uber grows. Today, we support many types of users across several different businesses, each with their own types of issues and unique requirements for how those tickets should be prioritized and routed. Our matching system evolved over several years to support those use cases (and others for simpler requests with natural language processing), but that resulted in a large, complex system that was hard to understand and harder to update without breaking other functionalities or introducing new bugs.
In early 2018, it was clear that we needed to replace our ticket routing system with something more flexible. We needed to develop a solution that would allow us to adapt to Uber’s changing needs more quickly and stably at scale.
In this article, we discuss our reasons for adopting workflow orchestration for ticket routing, the challenges we faced during our migration, and the solutions we developed on top of Cadence, Uber’s open source orchestration engine.
Early ticket routing at Uber
Support tickets at Uber have several attributes which are used in the routing process to direct their flow to specific support agents trained for handling particular customer support use cases. These attributes include user information such as language, country, and ticket “type”, for instance, “Driver-partner Questions about Payments” or “Lost Items.” Tickets may also be marked with a “user segment” if the user belongs to a population requiring specialized support, for example, “new driver-partners.” As tickets are created, they are categorized based on these attributes and queued until an appropriate agent is available to handle them.
Similarly, support agents have a set of skills which indicate the attributes they are trained to handle. For example, an agent who provides driver-partner support in India and is trained to provide additional help for new driver-partners may have the following skill set:
| Languages | Hindi, English |
| Countries | India |
| Ticket Types | Driver-Partner Account, Driver-Partner Payments, Driver-Partner Sign Up |
| User Segments | “New driver-partners” |
At it simplest, the ticket routing workflow must consider all of the combinations of attributes (categories) which an agent is trained to handle. From those categories, it should then assign the ticket which has been waiting the longest.
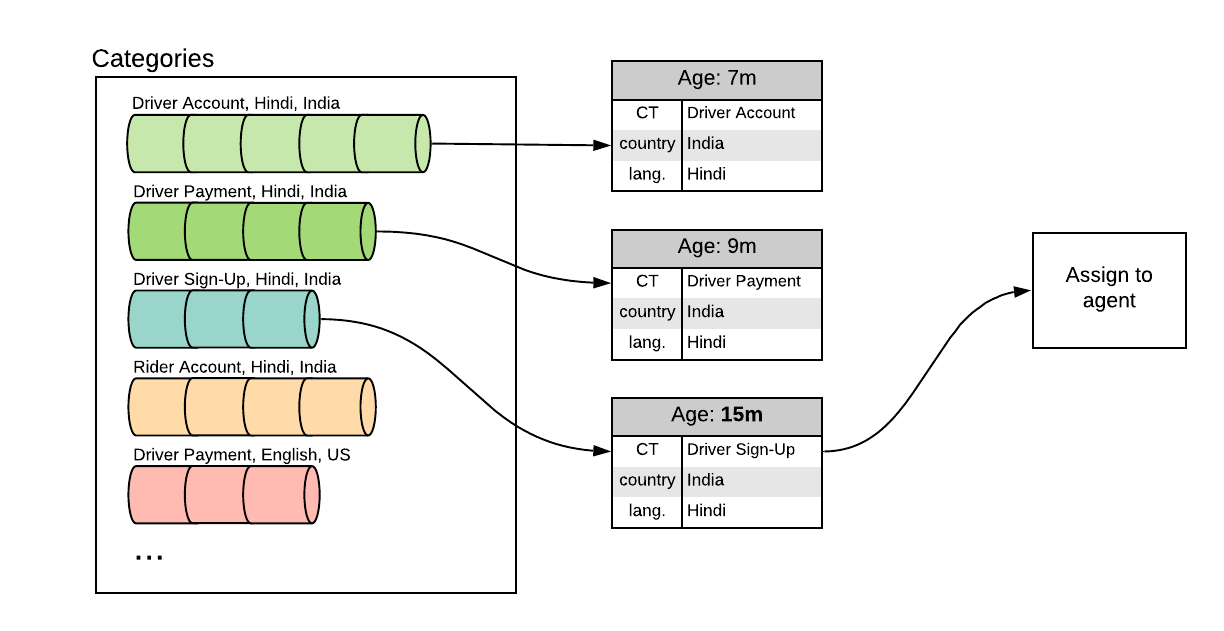
Additional prioritization rules complicate this routing. For example, many agents are trained to provide driver-partner support, but only a subset of those agents receive extra training to support new driver-partners. To maximize utilization, those agents should always be assigned tickets from new driver-partners when one is available. They may handle tickets from other driver-partners when no “new driver-partner” tickets are available, but “new driver-partner” tickets should be prioritized first.
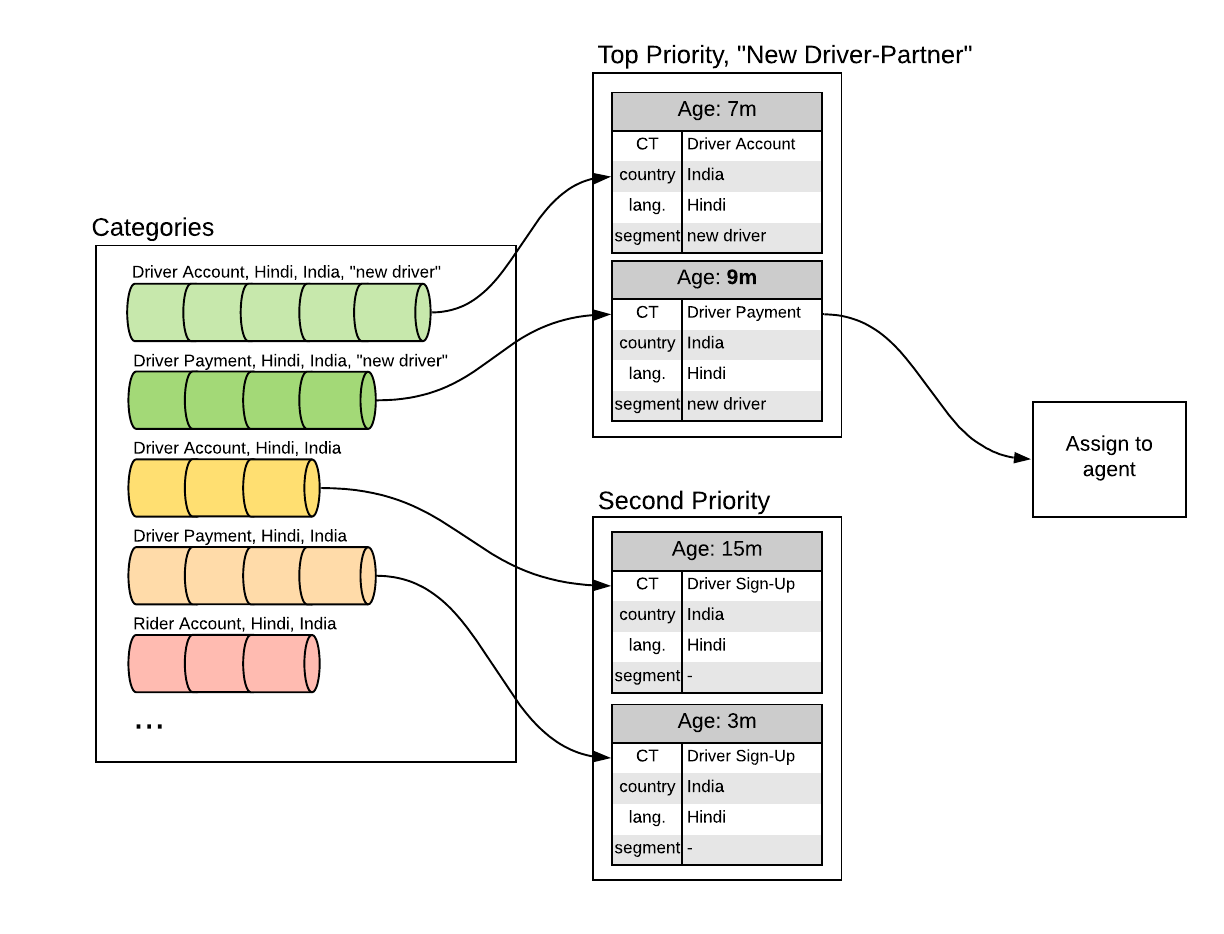
Challenges
Under the hood, Uber’s ticket routing system uses several attributes in addition to those listed above to match tickets with agents. It also has many prioritization rules for handling user segments, safety-related tickets, escalation of difficult tickets, and more.
This routing logic began with simple, straight-forward code, but it became more complex over time to satisfy new requirements and the original logic became obscured by that complexity. Years of growth resulted in fragmented logic spread across many classes and source files. The logic became hard to follow and harder to modify.
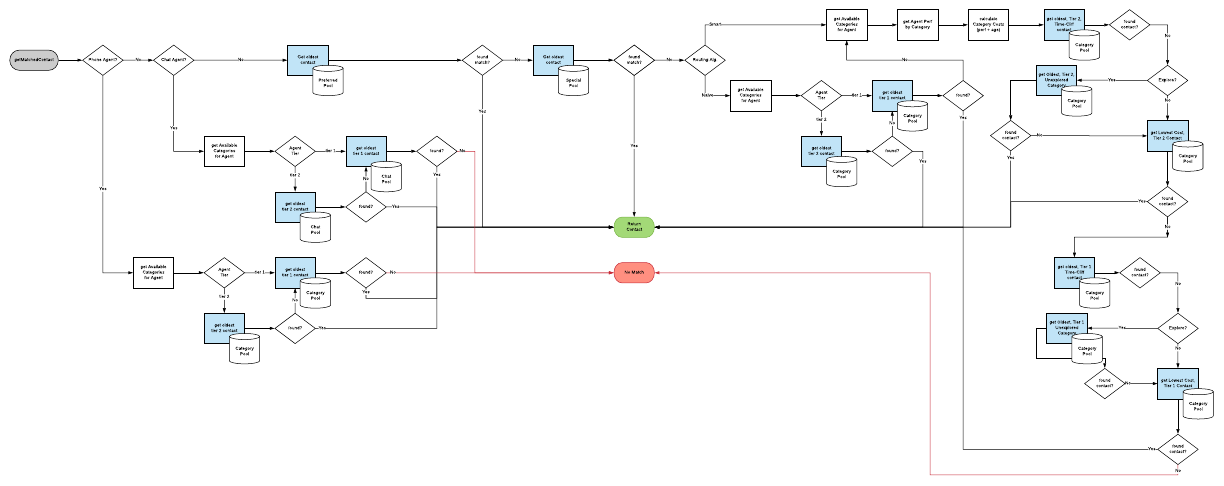
This fragmentation made our code less testable and more difficult to monitor. The core ticket routing logic was scattered between dozens of methods in several classes. Important steps within that process, such as identifying the categories an agent can handle, were also fragmented across multiple source files. When writing a new feature, this process fragmentation made it difficult to find and re-use existing code, resulting in code duplication.
Although we maintained high test coverage, our code was no longer structured in a way that allowed the control logic to be tested effectively. Our unit tests could not guarantee that all of the scattered pieces of logic were operating correctly or that bits of duplicated code behaved identically to each other. Moreover, this fragmentation led to less useful metrics around RPC endpoints and system performance, making it increasingly difficult to drill down and identify the source of bugs and other issues. These factors ultimately led to less reliable and consistent support experiences for our customers.
These problems also affected our day-to-day development in many ways. New developers required more time to onboard to the project, and new features took longer to design and implement. Even minor changes could have unexpected side effects that broke the routing logic and, when bugs were introduced, they were difficult to identify and fix. Combined, these factors made it difficult to keep up with new business requirements and prioritizations.
These limitations also interfered with our long-term vision for Uber’s support systems. As Uber expanded into new businesses, it was vital that our support infrastructure be able to handle tickets for modalities beyond ridesharing and to provide support-as-a-service to all businesses as part of a centralized workflow.
To overcome these various challenges, we needed to provide a flexible but stable routing platform that would allow developers across Uber to build their own routing rules in our system to support new products and modalities.
Routing as a workflow
To address the myriad problems presented by our legacy ticket routing, we decided to design our system’s ticket routing logic as a workflow, using Cadence, our open source orchestration engine, as our workflow engine. Cadence would enable us to separate the control logic and modularize the business logic in order to make routing more flexible and easier-to-understand. On top of integrating with Cadence, modularizing our ticket routing workflow, creating better code structure, and deploying more flexible prioritization logic enabled us to redesign our routing system as a workflow.
Overall, these steps enabled us to turn our Customer Obsession ticket routing system into a workflow that allows for not only an improved developer experience and more flexible and durable system architecture, but also a better and more reliable customer experience.
Leveraging Cadence
Cadence is distributed, scalable, durable, and highly available, making it an ideal fit for our workflow orchestration engine. Cadence models business processes using two key concepts, workflows and activities. Workflows are the coordination logic, and are responsible solely for orchestrating the execution of activities. Activities are the implementation of individual tasks in the business logic.
Cadence activities and workflows are hosted on and executed by worker processes. Workers provide plenty of flexibility in how code is deployed. Each workflow and activity may be hosted on their own as a distinct worker, or a single worker may host multiple workflows and activities. This feature was important to our goal of creating a routing-as-a-platform orchestration engine, as this type of solution allows new activities to be developed, deployed, and plugged into the routing workflow without needing to redeploy the routing service.
Modularizing the ticket routing workflow
After performing a thorough review of our customer support platform’s existing routing code, we were able to reformulate the core routing logic as a series of discrete tasks. The logic to chain those tasks together became the new routing workflow, and each of those tasks was coded as a separate module, or “activity” in Cadence terms, to be executed by the workflow.
In this way, the complexity of our routing logic was reduced to a manageable control process and a handful of simple activities.
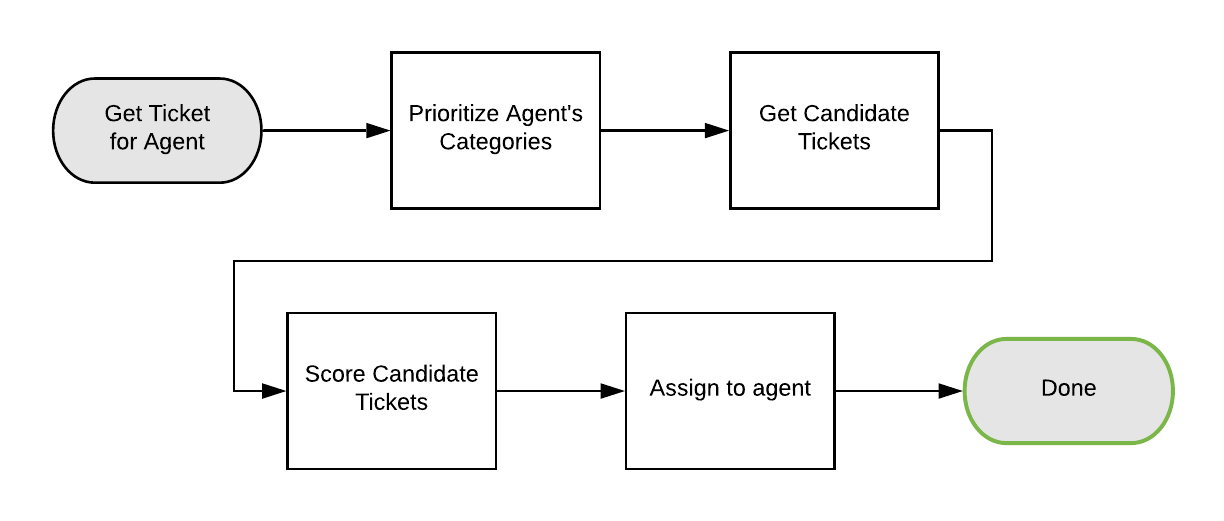
These steps are:
-
- Prioritize categories
- Group and sort the categories which an agent is trained to handle by priority.
- Retrieve candidate tickets
- Retrieve all of the tickets available to an agent from the queue of high priority tickets.
- If the high priority queue is empty, this step is repeated for the next highest priority group until a non-empty group is found.
- Score candidate tickets
- Assign a score to each of the candidate tickets. In our initial version of our orchestration workflow, this score is based solely on the age of the ticket.
- The workflow architecture allows for new scoring modules to be easily plugged into the ticket routing workflow. Those scoring modules can be chained together to support more complex logic.
- Assign top ticket
-
- The ticket with the highest score is assigned to the agent.
-
- Prioritize categories
Although this workflow supports all of the complexity of the original system, it is far easier to scan and understand because the control logic has been clearly separated and the business logic has been encapsulated into a handful of well-defined modules.
Rewriting the routing logic as a workflow helped us to improve the organization of the code, separate control logic, and properly encapsulate business logic. More importantly, adopting a workflow architecture will force us to maintain this organization as we continue enhancing ticket routing.
Better code structure
Improving the organization of our code also made the code more testable. The major steps in our routing workflow are now clearly delineated and have well-defined contracts, enforced with thorough unit tests. The control logic to orchestrate those tasks is encapsulated within a single, easy-to-test workflow function. The workflow engine we chose, Cadence, also provides an excellent test framework with support for mocking activities that make it easy to write comprehensive tests for the routing workflow. This enables us to make changes to the routing logic with the peace of mind that we are not breaking other use cases.
Activities within a workflow are a useful abstraction for collecting meaningful metrics, as well. Monitoring error rates and latencies from each activity enables us to identify the source of problems quickly.
As a result of these improvements, now we can make changes to the routing workflow more quickly than we could previously and with greater confidence that problems can be caught early on.
Flexible prioritization logic
When we rewrote the routing logic, we replaced the previously hard-coded prioritization logic with a ticket scoring step. This step actually comprises multiple activities, or scoring modules, executed in series. The workflow defines a simple contract for scoring modules. Each must take an agent description and a list of candidate tickets with scores and return a list of tickets with updated scores.
Scoring modules are intended to be small, single-responsibility, and composable activities. For example, the first scoring module that runs in our workflow assigns each ticket an initial score equal to its age in milliseconds. Additional scoring modules can influence routing priority, either by multiplying scores by a boost factor, or by adding a concrete score boost based on features of the candidate tickets and the agent. A chain of several scoring modules can support complex prioritization use cases without complicated code, while individual modules remain small and easy-to-understand.
This architecture does not require a workflow engine like Cadence, but it does necessitate adopting the workflow paradigm: the use of discrete tasks, orchestrated by a separate control process. Leveraging Cadence made it easier to implement scoring modules since the workflow engine could manage our orchestration needs. Additionally, the use of a workflow engine makes this architecture even more flexible. Scoring modules can be added, removed, or re-ordered easily now that the control plane is isolated from business logic. As a future enhancement, we plan to move the list of active scoring modules to configuration, allowing code-free updates. Once scoring modules have been incorporated into the workflow, they can also be updated and deployed in isolation, without requiring code changes or deploys to the routing service.
The workflow paradigm shift
As developers, we are used to breaking complex code into smaller pieces using functions and classes. It is easy to naively use this approach when writing workflows, pulling bits of logic out into activities or helper functions because they became too complex or were used more than once. While we experimented with this more traditional method early on in our development process, we found that approach was insufficient for our needs. Ultimately, migrating our Customer Obsession ticket routing logic into a workflow required a paradigm shift in the way we think about code.
The key difference between traditional development and the workflow paradigm is that workflows emphasize the distinction between tasks and the control logic to coordinate those tasks. Before Cadence, our team rarely thought about code explicitly in those terms, and found that the distinction was not as straightforward as we expected. In order to draw a line between control logic and tasks, it was important to identify principles to guide our design.
Our primary guiding principle was to structure our code to enhance the clarity of the workflow. Since we wanted other teams to be able to build their own routing logic, our control logic would be public and it was important that developers outside the Customer Obsession team could easily scan the workflow and understand the ticket routing process. Logic that was necessary for that understanding should be expressed in the workflow. Complex details, on the other hand, could actually obscure the core logic. The workflow became more clear when it was properly encapsulated in activities. Below, we outline key lessons learned from our experience navigating this paradigm shift.
We didn’t make our logic too simple…
One of our early mistakes was attempting to oversimplify the control logic. Since we were unfamiliar with separating control logic from business logic, our initial design of the routing logic had an underdeveloped control flow and handled all prioritization through scoring modules. Our earlier example of an agent with special training to help new driver-partners would have been handled by a scoring module which guaranteed new driver-partner tickets would be scored higher than other tickets for that agent.
This approach had some problems. To preserve our existing logic, scoring modules like this would need to ensure that matching tickets remained at the top of the list, even when composed with additional scoring modules. We considered solving this by setting the score of non-matching tickets to zero. However, all scoring modules would need to understand and respect this convention. That complicated the scoring module contract and placed a burden on the developers who wrote scoring modules. A mistake in that logic could potentially mis-route tickets in ways that would affect our operational SLAs, not to mention cause sub-par user experiences
Rethinking this problem with the principle of clarity in mind, we realized that we were actually hiding an important step in the routing process. We had two types of prioritization: filtering rules that sorted categories into coarse-grained groups and scoring rules to prioritize the contacts within those groups. When we restructured our workflow to make the filtering step explicit, however, both the workflow and the scoring module interface became more clear.
… or too complex
Separating the filtering and scoring steps put us on the right path, but we were still figuring out the best way to separate control logic from business logic. In our second attempt, we overcorrected and put too much logic into the workflow. This time, we included inspecting properties of the current agent and deciding which priority groups should be searched as part of the control logic.
This approach worked, and when we had six total priority groups, the control logic was still relatively easy to understand. Soon, however, we began implementing a feature that required two new priority groups with unique logic. Adding this directly to the control logic made the workflow difficult to read.
The details of how categories were grouped by priority was a complex detail that obscured the important logic of the workflow. Cadence supports many options for managing complexity in your workflows, including full support for OO programming within workflow code. For our use case, we pulled the priority group logic out of the workflow and created a new activity to perform that computation. The intent of our workflow became easier to understand when we encapsulated that logic in a clearly-named activity. Additionally, we gained the benefits of Cadence’s durability and at-most-once execution guarantees around that computation.
Overall, we found that the division of logic between the workflow and its activities required a balancing act. Put too much logic into activities, and the workflow becomes too simple. It is difficult to understand what the workflow does because so much of the logic is hidden away within complicated activities. On the other hand, when too much logic is put in the workflow, the real control logic can become obscured by unnecessary complexity. Finding the right balance made our workflow easy to read and maintain.
Supporting low latencies in workflows
The ticket routing process is a low-latency, synchronous process which executes in response to an agent becoming available and requesting a new ticket. Modeling the process as a workflow created some unique challenges since workflow orchestration is typically used to asynchronously execute long-running, latency-tolerant processes.
Cadence passes execution between workflows and activities using a work queue called a task list. Work is queued in a task list once a workflow starts and every time execution passes from the workflow to an activity or vice versa. This design supports durable, highly available, and distributed workflow execution, but it also introduces activity-to-activity latencies on the order of 100 milliseconds. For typical, asynchronous workflows, this is perfectly acceptable, but we needed faster performance from the routing workflow since it handles real-time requests from users. We were able to achieve this using Cadence’s local activity functionality.
The local activity allows short-lived tasks to be scheduled and run in the workflow’s worker process instead of queueing the work in a task list. The tradeoff is that local activities must be hosted in the same process as the workflow, so we lose the freedom to deploy them independently.
Our main motivation for adopting a workflow architecture was to improve code clarity and flexibility, not necessarily distributed execution. The workflow design called for public extensibility via scoring modules. We needed the flexibility of distributed hosting for those activities, but for everything else, using Local activity was acceptable. By using Local activity for all of the core steps in our workflow, we were able to virtually eliminate activity-to-activity latencies. Today, our routing workflow’s average performance is comparable to the original routing code and its p99 performance is actually improved by more than 33 percent, leading to improved user experiences for both customer support agents and customers alike.
We incur a small latency cost for initiating a workflow via Cadence. This process also queues work in a task list for asynchronous distribution to workflow workers. We measured end-to-end latency in the process which triggers the routing workflow, and again in the worker which executes the workflow. We found that triggering the workflow adds about 20 milliseconds of latency on average, but has a p99 cost of around 160 milliseconds. This latency balances out the performance gains we saw in the workflow. After factoring that in, the microservices which depend on the ticket routing system see similar latencies from the routing workflow and the old routing code.
The future of our routing workflow
Now that we have migrated our routing logic to a workflow, we plan to use that workflow as a foundation for future enhancements.
Customizable Routing Logic
We designed the routing workflow to be easy to extend. New prioritization rules can be added by writing a new scoring module. Moving forward, we plan to build on this by allowing other teams within Uber to submit new scoring modules with their own routing logic.
Modifying functionality with pluggable modules is not a novel idea and can be accomplished without a workflow architecture. However, adopting workflow orchestration with Cadence makes this much easier to implement. Other teams can code scoring modules in their own code base and host activity workers within their services or even on a serverless architecture like Uber’s Catalyst.
Cadence’s model allows us to reference remote activities by name from our routing workflow and provides strong reliability guarantees around activity execution. This makes it easy for the routing workflow to support a list of scoring module names which can be dynamically updated to plug in new routing logic. Using this, we envision the routing workflow as an extensible platform providing customizable routing to satisfy Uber’s diverse needs.
Business Workflow Description Language: a workflow DSL
The Customer Obsession team has partnered with the Automation Platform team to develop a workflow DSL called the Business Workflow Description Language (BWDL). Whereas typical Cadence workflows are authored as code, the BWDL project will support JSON-based workflow definitions. A BWDL interpreter will convert those JSON workflow definitions into Cadence workflows dynamically.
The aim of this project is to support workflows as configuration rather than code. BWDL will make it possible to create, update, and deploy entire workflows without code changes or service deployments.
As a complement to BWDL, the Customer Obsession team is also developing an orchestration service to handle the management of BWDL workflows. It will provide storage, versioning, and execution of workflows for customer care processes such as ticket routing, freeing developers to focus on feature development.
Workflow Management UI
BWDL will allow rapid iteration on workflows, but only for technical users who are comfortable working with a JSON DSL. Once that has launched, we have plans to deliver a workflow authoring and management UI through continued partnership with the Automation Platform team. BWDL will serve as the foundation, as JSON DSLs are easy to programmatically parse and generate.
This UI will allow non-technical users to create and modify workflows by arranging components (activities) with a drag-and-drop UI, and connecting them to each other using a set of simple conditions.
Through these updates and others, we hope to deliver a routing platform with which our Customer Obsession agents can dynamically update and configure their routing logic on-demand, leading to improved experiences across the customer support experience.
Interested in designing orchestration workflows at scale or contributing to Cadence and other Uber Open Source technologies? Apply for a role on our team.

Ken Buckner
Ken Buckner is a senior software engineer on Uber's Customer Obsession Engineering team.
Posted by Ken Buckner
Related articles



How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

A beginner’s guide to Uber vouchers for transit agency riders

Uber Earner x Miami HEAT Ticket Sweepstakes OFFICIAL RULES

Case study: Tri-Rail’s role in paving the way for effortless commuting

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
