
Introduction
Uber relies on a containerized microservice architecture. Our need for computational resources has grown significantly over the years, as a consequence of business’ growth. It is an important goal now to increase the efficiency of our computing resources. Broadly speaking, the efficiency efforts in compute cluster management involve scheduling more workloads on the same number of machines. This approach is based on the observation that the average CPU utilization of a typical cluster is far lower than the CPU resources that have been allocated to it. The approach we have adopted is to overcommit CPU resources, without compromising the reliability of the platform, which is achieved by maintaining a safe headroom at all times. Another possible and complementary approach is to reduce the allocations of services that are overprovisioned, which we also do. The benefit of overcommitment is that we are able to free up machines that can be used to run non-critical, preemptible workloads, without purchasing extra machines.
In order to achieve this, we need a system that provides a real-time view of the CPU utilization for all hosts and all containers across all clusters. This system runs in production across all of our clusters, and is internally referred to as cQoS (Container Quality of Service). cQoS enables the scheduler to perform telemetry-aware scheduling decisions, such as load-aware placement of tasks, proactive elimination of hotspots in the cluster, and load-aware scaling of the cluster size. In addition to helping with efficient resource utilization, such a system also helps with container performance analysis. The per-container metrics help with identifying performance issues related to uneven load balancing and container right-sizing.
System Requirements
A set of common requirements emerges for the scheduling use cases described above:
- The need to accurately detect hosts that have high CPU utilization and contention in a timely manner—we refer to these as hot hosts
- From the hot hosts, identify containers that have the highest recent levels of CPU utilization and are experiencing the most contention, such containers are likely to either themselves suffer from performance degradation or cause other containers to suffer when there are load spikes; the scheduler can then re-schedule them in a service tier- and SLA-aware manner
- The above tasks need to be performed accurately while minimizing false positives and by smoothing out temporary spikes—sustained resource contention is what needs to be mitigated
- The need for a mechanism to easily tweak and tune the metrics, thresholds, and sustained durations, based on operational experience
- The solution needs to work with various flavors of container orchestration systems such as Kubernetes. The methods and techniques used are Linux and container runtime specific, and do not depend on any specific orchestration system.
- For real-time decisions, the cluster-wide state (resource utilization snapshots of host and container usage) needs to be refreshed every 10 seconds—our production clusters are very large and the container density per host is very high
Architecture and Design
To address the above requirements, we have built the following system:
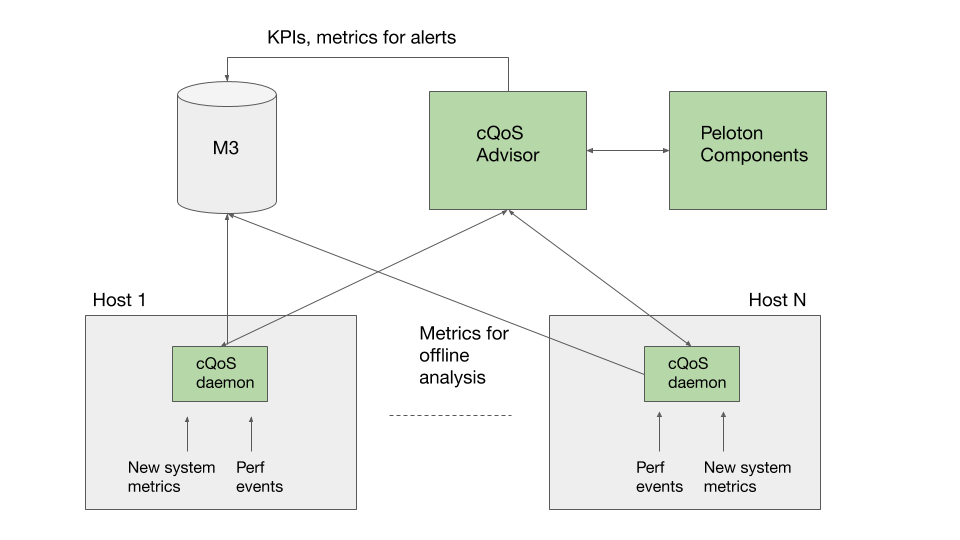
The cQoS system comprises 2 main components:
- cQoS daemon
The cQoS daemon runs on every single host. Its functions are as follows:
- Collect raw system metrics for the host (e.g., run queue length, available memory, etc.) and running containers (e.g., cpu time, cpu throttled time, cycles, instructions, etc.)
- Maintain recent history of the raw metrics (30 second sliding window) and perform local aggregations
- Sync the aggregated local state with the cQoS advisor every 10 seconds (tunable) over gRPC
- cQoS advisor
The cQoS advisor has a cluster wide view of all hosts and running containers:
- Ingest data every 10 seconds from all cQoS daemons in the cluster
- Maintain cluster-wide summary state of all hosts
- Rank all hosts in order of load, using host metrics provided by cQoS daemons
- For hosts that are running hot (based on a tunable knob for thresholds), compute recent usage and rankings of containers running on those hosts
- Provide actionable information to the scheduler about containers running hot
- The scheduler interface to the advisor is over gRPC as well
cQoS uses M3 as the time-series persistence backend for alerts as well as offline analysis, which helps guide the tuning of thresholds and various system parameters.
Use Cases and Results
Efficiency: Improved Load Balancing Across Clusters
Before the cQoS system was deployed, there was a wide variance in the CPU utilization across hosts in a cluster. Even though the cluster-wide average was low, we would see that a non-trivial fraction of hosts had high CPU utilization compared to the mean, while a similarly large proportion of hosts were heavily underutilized, as shown in the Before figure below.
In order to be able to safely overcommit the CPU on all hosts in a cluster, the utilization of all hosts must be contained within a somewhat narrow band around the mean, as a prerequisite. Doing so reduces the probability of workload performance degradation on outlier hosts that would face increased CPU contention. A combination of load-aware placement and proactive elimination of local hot spots helped us get to that state, as can be seen in the After figure.
Before After
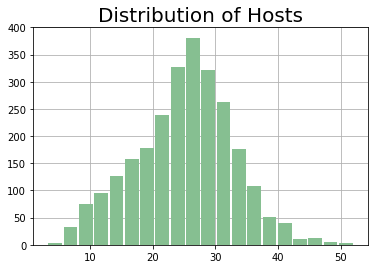
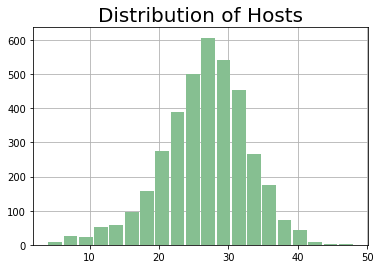
Workload Performance: Actionable Insights
The same telemetry that enabled efficient and reliable cluster operations also helps with the identification of performance bottlenecks, such as the following examples:
Uneven Load Balancing
Stateless microservices are designed to be horizontally scalable. In an ideal situation, all instances of a service would share the incoming load (requests per second) equally. However, in practice, another consideration for load balancing is subsetting, where we limit the pool of service instances with which a client container may connect, as most of the connections are long-lived. This may result in uneven load sharing across the instances of a service, as can be seen in a few examples shown below:
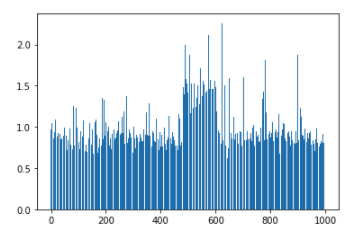
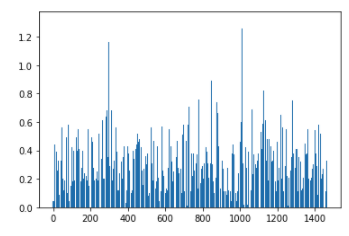
The above figures show the distribution of cores used by the instances of two different microservices, where the x-axis represents the instance identifier, and the y-axis shows the number of CPU cores used. Based on this data, service developers or SREs can tweak the subsetting configuration and achieve better load distribution, thereby reducing the tail latencies.
Container Right-Sizing
Selecting the vertical (number of CPU cores) and horizontal (number of instances) size of a service could be the topic of a detailed post by itself. That sizing needs to be adjusted and kept current with the realities of the production environment. Under-sized containers can lead to performance degradation that manifests in unexpected ways. The following graph shows the error rate of an example service over a time window. We see that once the container’s CPU quota was increased, the error rate became negligible. The reason was that when the container was under-sized, it was excessively throttled and unable to serve incoming requests in a bounded time window. The cQoS system has a cluster-wide view of all hosts and containers, and was able to quickly identify services that were excessively throttled.
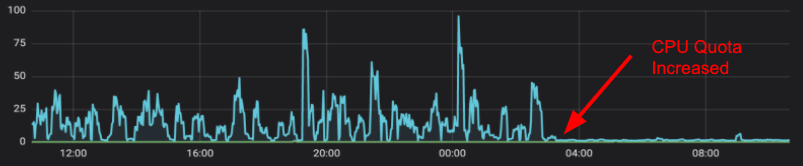
After the root cause was understood, the fix was a simple configuration change, resulting in a significant reduction to the on-call burden for the maintainers of that service.
Key Takeaways
There are several challenges to running microservices in production at large scale, and this post just scratches the surface. One of the biggest challenges at scale is to manage the cost of infrastructure on an ongoing basis. We presented a system that provides cluster-wide snapshots of resource utilization across hosts and containers. These snapshots allow the scheduler to make intelligent decisions and help achieve better utilization of the compute resources, while not compromising on the overall reliability of the platform. The solution is agnostic to whether the workloads run on the cloud or on-prem data centers. It is also agnostic to the workload orchestration system. Moreover, the same system that helps achieve infrastructure efficiency also helps with workload performance analysis.
We learned many lessons along the way. The right choice of metrics, thresholds, and sustained durations matter significantly—being too sensitive would cause the system to react too aggressively, while excessive smoothening can cause resource spikes to go undetected. Before rolling out in production, we collected and analyzed a lot of data, across several clusters and over a considerable time period. It is also important to note that in a large engineering organization with many services and teams operating independently, there are plenty of upgrades and deployments happening throughout the day. Any platform-level container-rebalancing scheme must honor the SLAs of the services. Having well-defined service tiers based on business criticality helped guide our design. The service tiers allow us to select rebalancing candidates in an order that prefers the least critical containers first. The containers belonging to the most critical services are excluded from any preemption.

Gautam Kulkarni
Gautam Kulkarni is currently a technical lead for the Shopping area in Uber Eats with a focus on funnel health improvement and the next generation shopping platform architecture. Prior to that he was the technical lead for the Container Runtime and Efficiency initiatives in the Compute platform within the Infrastructure organization at Uber.
Posted by Gautam Kulkarni
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
