Automating Merchant Live Monitoring with Real-Time Analytics: Charon
April 29, 2021 / Global
At Uber, live monitoring and automation of Ops is critical to preserve marketplace health, maintain reliability, and gain efficiency in markets. By the virtue of the word “live”, this monitoring needs to show what is happening now, with prompt access to fresh data, and the ability to recommend appropriate actions based on that data. Uber’s data platform provides the self-serve tools which empower the Ops teams to build their own live monitoring tools, and support their regional teams by building rich solutions.
For this project, the requirement was to provide merchant level monitoring and handle the edge cases which remain unaddressed by the sophisticated internal marketplace management tools. We used a variety of Uber’s real-time data platform components to build a tool called Charon to reduce impact of poor marketplace reliability on the merchants.
Launched in early 2020, Charon ended up being extremely effective when it enabled delivery-only opening of restaurants and other merchants which were closed during the COVID-19 lockdowns. In this article, we take the Charon COVID-19 use case to demonstrate how Uber’s data platform empowered the team to build and adapt faster.
Motivation for Charon
Charon is a framework for controlling the demand at the merchant level through the enforcement of real-time rules. We originally built Charon because we noticed that certain merchants were suffering more than others from poor marketplace reliability. We have some great internal tools for marketplace balance management at Uber, but they aggregate the metrics and take action at the city or geofence level – we wanted to be more granular.
To address marketplace reliability, we leveraged Uber’s Realtime Analytics platform to define an indicator of poor reliability: the metric called “Long Request” (LR). This is the count of live orders that have been prepared by a restaurant, but have not yet been successfully assigned to a courier for at least 10 minutes. Most orders are assigned to a courier almost instantaneously, while LR orders are very likely to never find a courier, and cause extremely bad experiences for both restaurants and eaters.
After having defined LR, we set relative thresholds. We then built a rule that would automatically close a merchant if the LR count exceeds the relative threshold. In this way, couriers in the area can be utilised to absorb the current “queue” of LR orders, without adding more orders to the queue that may not be fulfilled. Through this rule, we were able to considerably limit these suboptimal edge-cases and limit the bad experiences that eaters and merchants could face. The trade-off from this rule is that by closing certain merchants we offer less choice to eaters, but we made this almost negligible through merchant-level actions and fine-tuned thresholds.
As we started testing this rule in a subset of markets, COVID-19 hit some of the biggest markets in our region. Many countries went into lockdown mode and, for many restaurants, food delivery was the only option to continue running their business. Even if they wanted to do so, they had to comply with new local regulations to try and slow down the spread of the virus.
The first problem we had to solve was to make sure that our platform wouldn’t create large crowds of couriers waiting outside top-selling restaurants and other merchants. We saw that during dinner peak restaurants could have a few dozens couriers all picking up orders simultaneously. The second issue we had to solve was that restaurant staff had to respect safe distance inside the kitchens, which meant that staffing had to be reduced and the kitchen productive capacity was smaller than before.
Thanks to Uber’s Realtime Analytics we were able to quickly augment Charon to also address these COVID-related challenges and use this framework to fix the issues beyond the original goals.
Impact
Business Growth (merchant sales, distribution of orders)
Over the last few months, Charon has allowed us to improve the customer experience by preventing orders that are likely to go unfulfilled. Furthermore, we leveraged this framework to adapt our business operations to a fast-changing world affected by the global pandemic. Preventing situations of courier crowding has decreased the risk of spreading COVID-19, and slowing down order inflow for staff-constrained merchants allowed merchants to continue offering a reliable and efficient service with reduced staff. These have been extremely important for helping our business bounce back after the first wave of COVID-19.
COVID Situation Handling
Charon has been very successful in addressing new issues quickly. When restaurants and other merchants started dealing with the reality of doing business during a global pandemic, many of them didn’t think they could reopen safely. Our local teams on the ground realised that the common issues of courier crowding and reduced kitchen capacity were something we had to address.
We started piloting the new COVID-19 rules in a few markets and merchants were eager to scale it further. Especially large restaurant chains saw that with these rules they would be able to reopen more quickly and safely.
Customer Satisfaction
More engaged merchants love that they can have a say in the Charon process by setting merchant-specific thresholds for some of the rules. For example, as Europe is entering into a second wave of COVID-19 lockdowns at the time this article was being published, some merchants have already reached out to re-enable some of the stricter rules we had in place back in March.
Charon Architecture
Charon’s architecture relies heavily on Uber’s realtime analytics systems and data workflow management systems. Following is how Project Charon came to be and how data tools were used at each stage.
High-Level Data and Process Flowchart
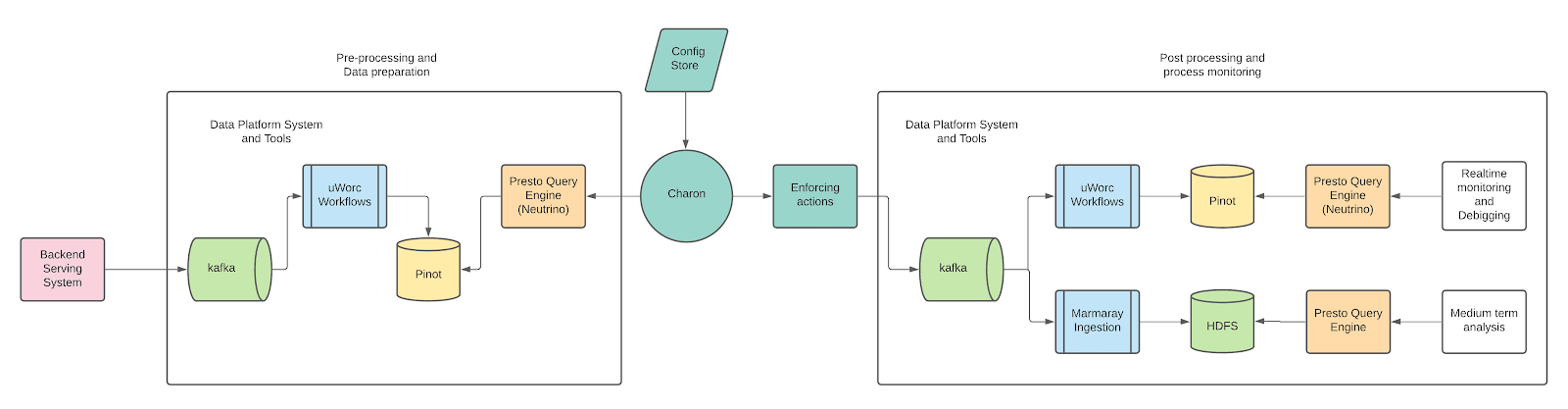
The above diagram shows the lifecycle of data from various upstream services to Charon where the actions are enforced. The action history is then ingested to our data platform for post processing.
More in detail, describing the above flowchart from left to right, we start all the way from the backend microservices that power our order creation and workflow orchestration. These services produce data, which enters Uber’s data infra through Apache Kafka. uWorc is then used to ingest this data into Apache Pinot, and this makes it easily available to Charon for querying. This is the infrastructure that Charon depends on – without this data in Apache Pinot, it would be very difficult for Charon to calculate thresholds and enforce rules.
Following to the right of Charon (downstream) we continue to heavily leverage Uber’s data infra. After enforcing actions, Charon produces logs to Apache Kafka (just like the upstream backend microservices). These are ingested into Apache Pinot through uWorc for real-time process monitoring and debugging. It allows local ops to query merchant-level actions with very low latency thanks to the Neutrino Presto® Query Engine. Separately, through Marmaray ingestion, the Charon actioning logs are brought into HDFS. There the standard Presto Query Engine (higher latency than Neutrino but with no query limitations) is used to do more involved historical analysis to fine-tune the Charon thresholds.
Data Sources
Granular order-level data (when an order was accepted by a merchant, assigned to a courier, in delivery to the eater, etc.) is generated by upstream microservices that support the mobile app.Apache Kafka acts as a bridge between these data sources and Uber’s data infra. We have trillions of messages flowing per day, which is a major source of our real-time data.
A lot of data is not very useful if the users don’t know how to discover or navigate it. That’s why we also heavily leveraged Databook, Uber’s in-house platform that surfaces and manages metadata about the internal locations and owners of certain datasets, allowing us to turn data into knowledge. Users can look up various topics and their schema available for consumption, and decide for themselves what is useful for them.
Thus, Charon was able to leverage the existing Eats order-level data produced by upstream services.
Realtime Datastore – Apache Pinot
The core building block of our real time platform is Apache Pinot – a distributed, scalable OnLine Analytical Processing (OLAP) system designed for delivering low latency, real-time analytics on TeraByte-scale data. Apache Pinot supports near real-time table ingestion, and is well-suited for low latency, high Queries-Per-Second (QPS) workloads of analytic queries. It supports data ingestion from batch data sources like Hadoop HDFS, as well as stream data sources like Apache Kafka as depicted below.
We operate a multi-tenant Apache Pinot cluster with multi region redundancy, and provide seamless table onboarding and querying tools which enables platform users to build applications on top of Apache Pinot without worrying about operational or functional details.
If you are interested in how we operate Apache Pinot at scale, please read our previous blog post.
Data Workflow Management
To reduce the initial effort required for setting up these data workflows, we have handy self-service tools at Uber that allows teams to create and manage these without much help from the data infrastructure teams.
Real-time ingestion workflows
uWorc is an internal deployment of the open-source project StreamLine that allows, among other things, to set up the ingestion from a Apache Kafka topic to Apache Pinot in just a few clicks. After a recent update, we can even create Apache Pinot tables automatically from Apache Kafka topics by inferring data and column types.
For Charon, we created a uWorc workflow to get the order-level data from Apache Kafka to be ingested into Apache Pinot. To go one step further, when Charon takes an action we also emit this into another Apache Kafka topic and make it available in Apache Pinot for post-process monitoring and debugging purposes.
Ingestion to data warehouse
For medium- and long-term complex analysis that does not require real-time data, we use Marmaray – an open-source generic data ingestion and dispersal framework and library, and Piper – a data workflow management platform that enables users to author, manage and execute data workflows (data applications) that ingest the Apache Kafka topic where we publish the Charon action logs into Apache Hive. This allows us to have indefinite historical retention for the action data, and also to do some more complex analysis, such as threshold fine-tuning by leveraging historical data.
Querying the Data
To make querying the data in Apache Pinot easy, we have integrated Presto with Apache Pinot so that standard Presto SQL can be used to query data with rich SQL operations available for transformations. We have worked on creating a lightweight, microservice-like, REST-based deployment of Presto (internally referred as Neutrino), which adds minimal overhead to Pinot latency to support low query latencies.
We mentioned earlier that reliability and LR was Charon’s first use case. However, when COVID-19 hit EMEA, we realised that we could use this framework to make sure that we could still operate in light of new, pandemic-related regulations and safety measures. These new rules are a good, useful example of how we query Apache Pinot as part of this process. The availability of querying this data through SQL made it very quick and easy to add more rules and cover more use cases with Charon.
As mentioned above, the first problem we solved after the first wave of COVID-19 was courier crowding at restaurants while waiting to pick up orders during peak hours. In certain situations, we observed there could be several dozens of couriers picking up orders simultaneously from the same restaurant, and that’s definitely a situation we wanted to avoid. So we defined the “pick up” metric, i.e. how many orders are currently being picked up at the same location. Luckily, Torrent tracks an event for this specific leg of the order, so we were able to compute this metric with a rather simple query, shown below. We used this metric to close merchants that had too many couriers picking up orders simultaneously and keep everyone safe.

Another important way in which we leveraged the Charon framework for COVID-19 was the “prep cap” rule. The problem we wanted to solve here was that, in order to respect distancing in the kitchen, many restaurants told us that they could not prepare orders as quickly as before. This meant that their effective production capacity was reduced, and we worked with individual restaurants to get their inputs regarding what is the maximum number of orders they can prepare at once in their kitchen, taking into consideration the reduced staffing. This then allowed us to close restaurants once they had too many orders in preparation, so they could get rid of the queue before taking in more orders. This is the query we used for this rule:
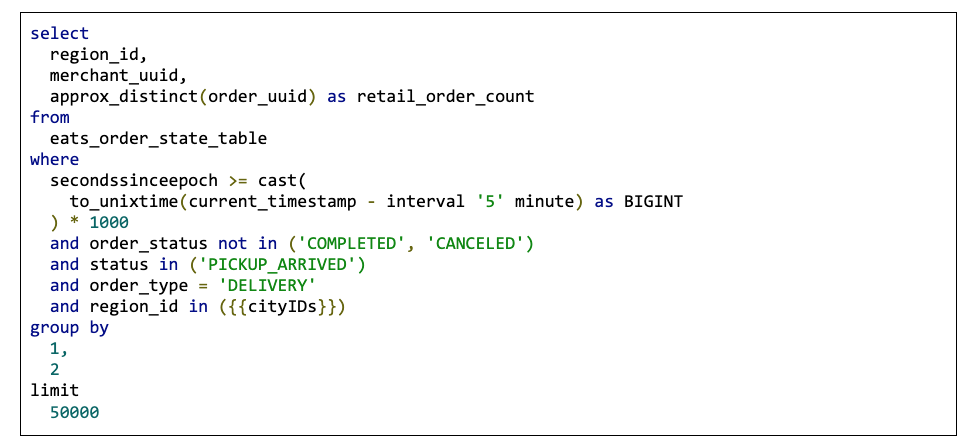
Action and Analytics
Once we have all the data we need to enforce the rules, we need to combine and process this data and also compare it with the thresholds stored in our config. This calculation happens on Data Science Workbench (DSW), an internal Uber tool that provides containerized notebooks for data scientists to use for complex data processing.
Then we enforce the rules calculations outcomes (effectively using our backend to close or reopen merchants), while logging each enforcement action to our Apache Kafka topic. These logs are then used to produce slack alerts in certain cases.
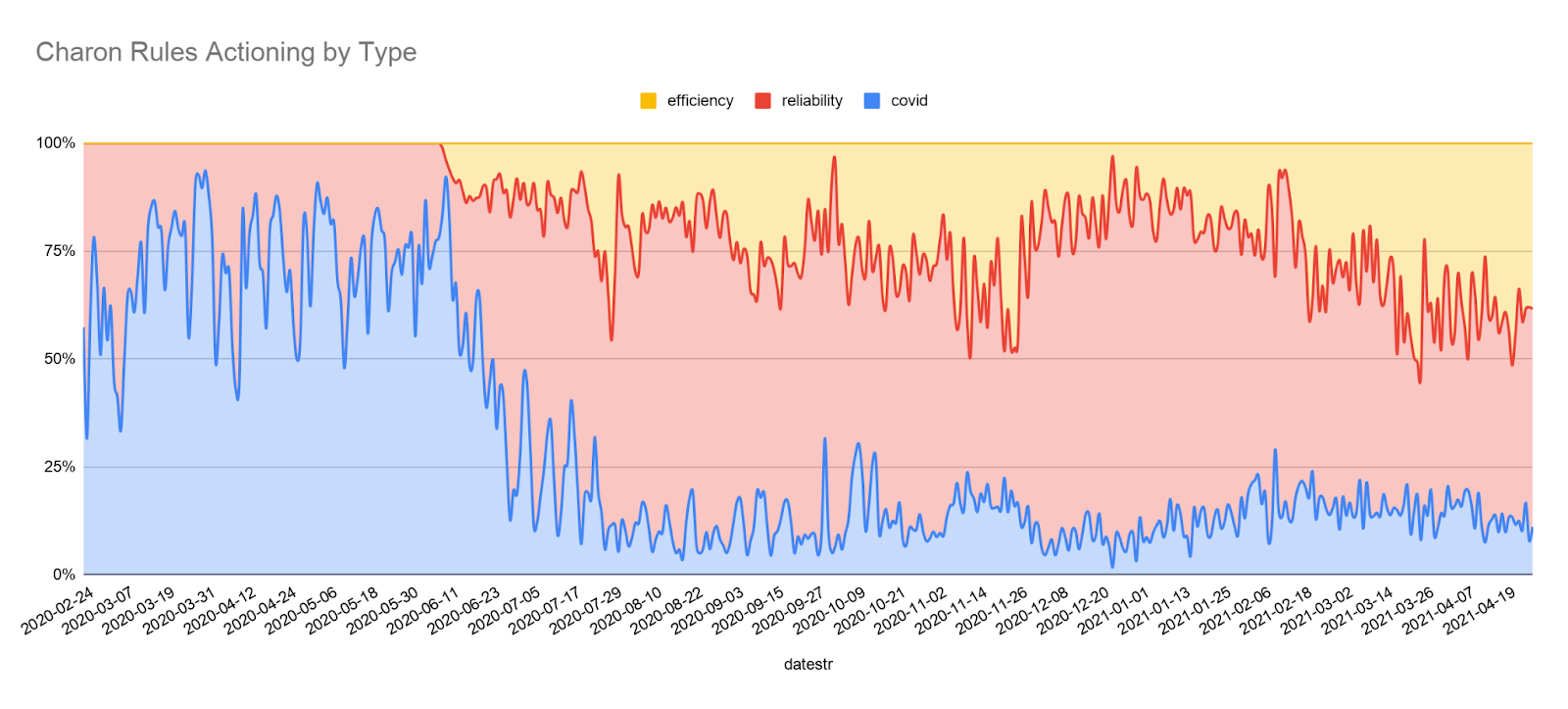
This graph shows the number of types of action taken by Charon over time. You can see in the March-May time period of peak COVID lockdown most of the actions taken were related to COVID, and later Charon actions were mainly related to marketplace efficiency and reliability.
Future Plans
When Charon first started, we needed to address certain problems in a matter of days. It was built very fast and without leveraging other products that might have more solid infrastructure in place.Charon was built as a framework that can easily support new use-cases through the creation of new rules. Charon will continue supporting Ops customers to address real time problems merchant and marketplace opportunities,
Be the future of Uber Data
At Uber Data, we are building scalable and reliable data platforms that enable the accelerated delivery of new features across multiple business units like Uber Eats, Uber Freight, Uber Rent, Machine Learning, etc. If you are interested in knowing challenges at Uber scale and building next-gen data platforms, do check out our Engineering openings.
Apache®, Apache Kafka®, Apache Pinot, Apache Hadoop®, Apache Hive, Kafka®, Pinot, Hadoop®, and Hive are trademarks of the Apache Software Foundation.
Presto is a registered trademark of LF Projects, LLC.

Marco Vita
Marco Vita is an Automation Ops Manager at Uber Eats EMEA. He works on improving marketplace efficiency with realtime data and automated workflows, combining his on-the-ground operational experience with software development.

Ujwala Tulshigiri
Ujwala Tulshigiri is an Engineering Manager on the Real-time Analytics team within the Uber Data Org. She leads a team that builds a self-served, reliable, and scalable real-time analytics platform based on Apache Pinot and Presto to power various business critical use cases and real-time dashboards at Uber.

Dharak Kharod
Dharak Kharod is a Senior Software Engineer at Uber, and has contributed to areas such as Driver Growth, Rider Access, and Data Infrastructure. He is currently on the Real-Time Analytics Platform team working on the core Apache Pinot storage and query layers.
Posted by Marco Vita, Ujwala Tulshigiri, Dharak Kharod
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Balancing HDFS DataNodes in the Uber DataLake

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale
The Easter Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules

UberX Priority FAQ
Products
Company
