
API gateways are an integral part of microservices architecture in recent years. An API gateway provides a single point of entry for all our apps and provides an interface to access data, logic, or functionality from back-end microservices. It also provides a centralized place to implement many high-level responsibilities, including routing, protocol conversion, rate limiting, load shedding, header enrichment and propagation, data center affinity enforcement, security auditing, user access blocking, mobile client generation, and others.
In our last article, we walked through multiple generations of Uber’s API gateway evolution and our design choices in each phase. In this article, we will take a deeper dive into the technical components of a self-serve API gateway system.
At the most abstract level, a gateway is yet another service serving data through APIs. Gateways come in many flavors and cover a wide spectrum, from low-level load balancers acting as API gateway, to a very feature-rich, application-level load balancer that operates on the request and response payloads in those APIs. At Uber, we developed a feature-rich API gateway that is capable of complex operations on the incoming and outgoing data payload across multiple protocols.
API Management
A feature-rich app is powered by interacting with numerous, backed services that provide different pieces of functionality. All these interactions go through a common application gateway layer. API management refers to the creation, editing, removal, and versioning of these gateway APIs.
An engineer configures the parameters of their API in a UI and publishes the functional API to the internet for all Uber apps to consume. The configuration governs the behavior of the API: path, type of request data, type of response, maximum calls allowed, apps allowed, protocols for communication, the specific microservices to call, allowed headers, observability, field mapping validation, and more.
Once the configuration is published, the gateway infrastructure converts these configurations into valid and functional APIs that can serve traffic from our apps. The gateway infrastructure also generates the client SDK for the apps to consume these APIs.
All interactions to the gateway systems happen through a UI, which walks the user through a step-by-step process for creating an endpoint. The UI streamlines the process, as well as enforcing various validations on aspects of the API. Additionally, this is where the request timeout, monitoring, and alerting are configured.
The management system provides auxiliary features like review gates before publishing new configuration changes and stored sessions to share or resume API management. Below is a screenshot showing a high-level overview of the UI step that allows adding middleware:
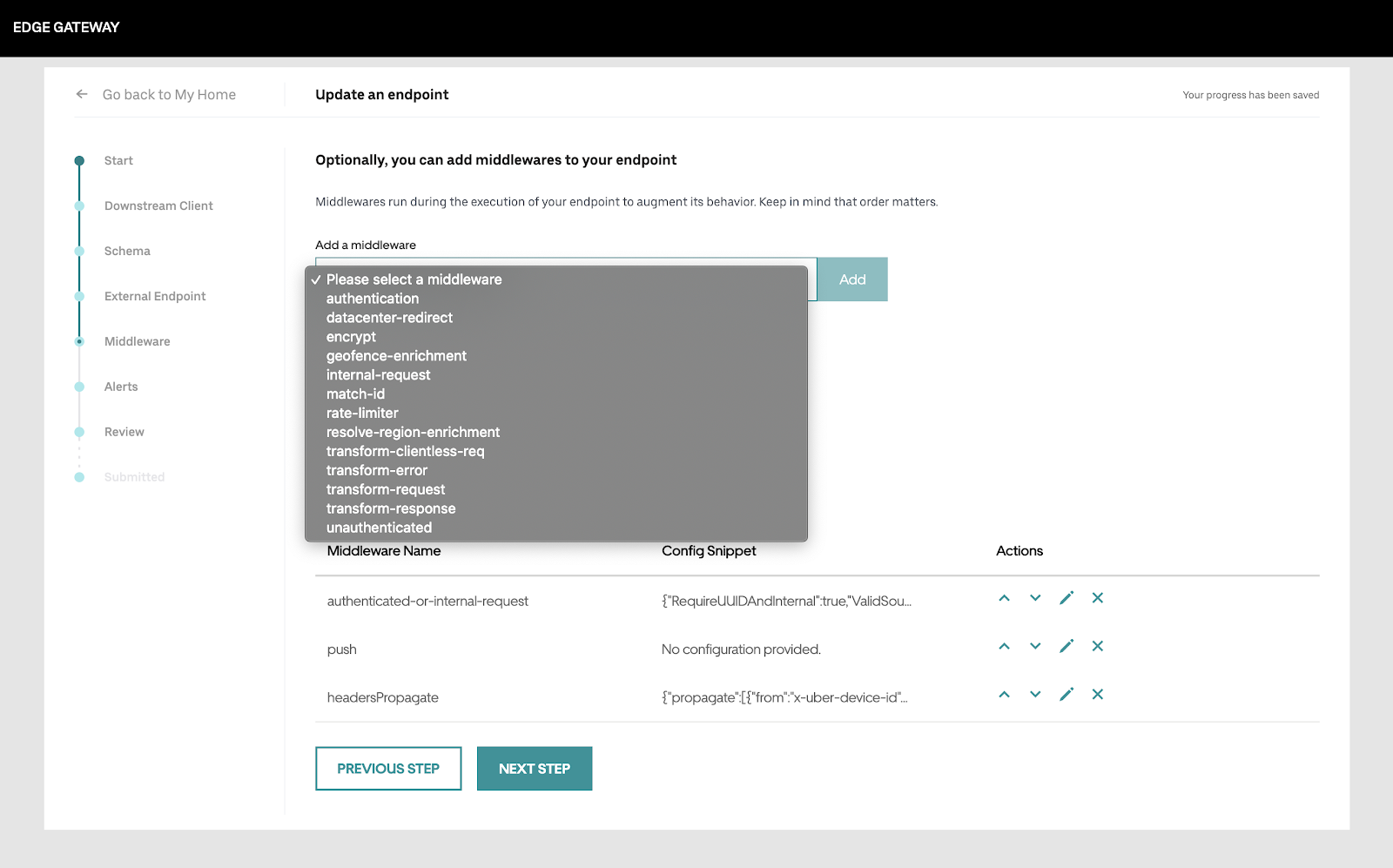
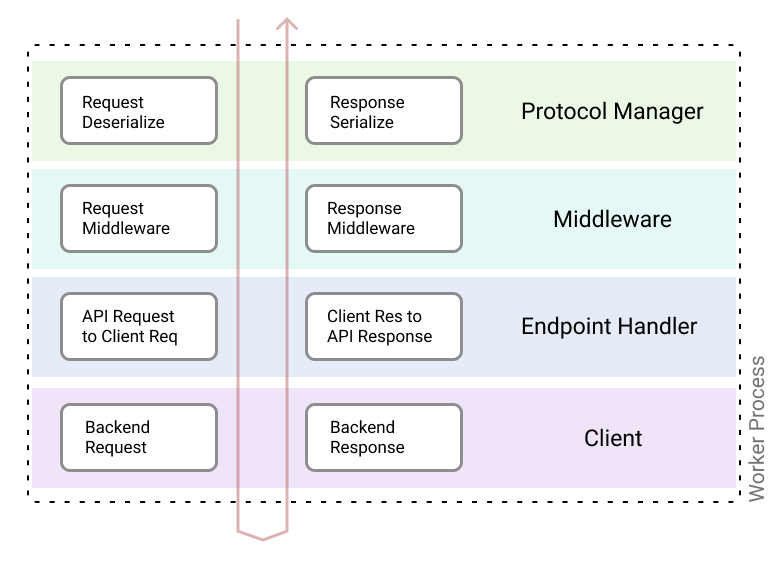
Components in a request lifecycle
To illustrate the various components of a gateway, it is important to understand how a single request flows through the gateway runtime. An incoming request contains a path that is mapped to a handler that serves it. Within the lifecycle of a request, it flows through the following components: protocol manager, middleware, data validation, handler, and a backend client. All components in the request lifecycle are implemented as a stack.
Each of the components, detailed below, operates on the request object on the way in and the same components are run in the reverse order on the response object’s way out.
Protocol manager is the first layer of the stack. It contains a deserializer and a serializer for each of the protocols supported by the gateway. This layer provides the ability to implement APIs that can ingest any type of relevant protocol payload, including JSON, Thrift, or Protobuf. It is also conveniently able to receive an incoming JSON request and respond with a proto encoded response.
Middleware layer is an abstraction that implements composable logic before the endpoint handler is invoked. Middleware implements cross-cutting concerns, such as authentication, authorization, rate limiting, etc. Each endpoint may choose to configure one or more middleware. In addition to the optional middleware, the platform includes a set of mandatory middleware that is always executed for each request. It is not required for a single middleware to implement both the requestMiddleware as well as responseMiddleware methods. If a middleware fails execution, the call short circuits the remainder of the stack and the response from the middleware will be returned to the caller. In some cases, middleware can be a no-op, depending on the request context.
Endpoint handler is the layer responsible for request validation, payload transformation, and converting the endpoint request object to the client request object. When operating on the response object, the endpointHandler converts the back-end service response to the endpoint response performs any transforms on the response object, response validation based on the schema and serialization.
Client performs a request to a back-end service. Clients are protocol-aware, and generated based on the protocol selected during the configuration. Users can configure the internal functionalities of a client, like a request and response transformation, validation of schema, circuit breaking and retries, timeout and deadline management, and error handling.
Configuring the components
Protocol manager, middleware, handler, and client have a number of behaviors that can be controlled using configurations. A user who is managing an API does not modify any code, but merely configurations to determine the intended endpoint behavior at the gateway. For ease of configurations, these are managed via a UI and backed by a Git repository.
The configurations for each component are captured in Thrift and/or YAML files. YAML files provide the information for components and act as a sort of glue between them. The Thrift files define the payload and the protocol semantics.
The gateway thrift file heavily uses the feature of annotations in thrift IDLs in order to provide a single source of truth for various features and protocols. In the sections below we will dive into the configurations for each component.
Protocol Manager
A protocol manager needs to understand the shape and type of data within the context of the protocol for the request. Similar parameters should be known for the response as well.
A three-line YAML configuration below provides the protocol type, a Thrift file path, and the method to be used by the protocol manager to process an incoming request:

The above configuration says that the new API is of type “HTTP” protocol and all the other details about schema and the protocol are provided in the apiSample.thrift file below.
The Thrift file apiSample.thrift is feature-rich, and describes the data types of the JSON request and response payloads, HTTP path, and the HTTP verb. The HTTP protocol is defined within the Thrift schema using the annotations feature of Thrift.


Not all API calls result in success. The following sample schema provides an error response from a handler into an appropriate HTTP protocol. This is done using annotations as shown below:
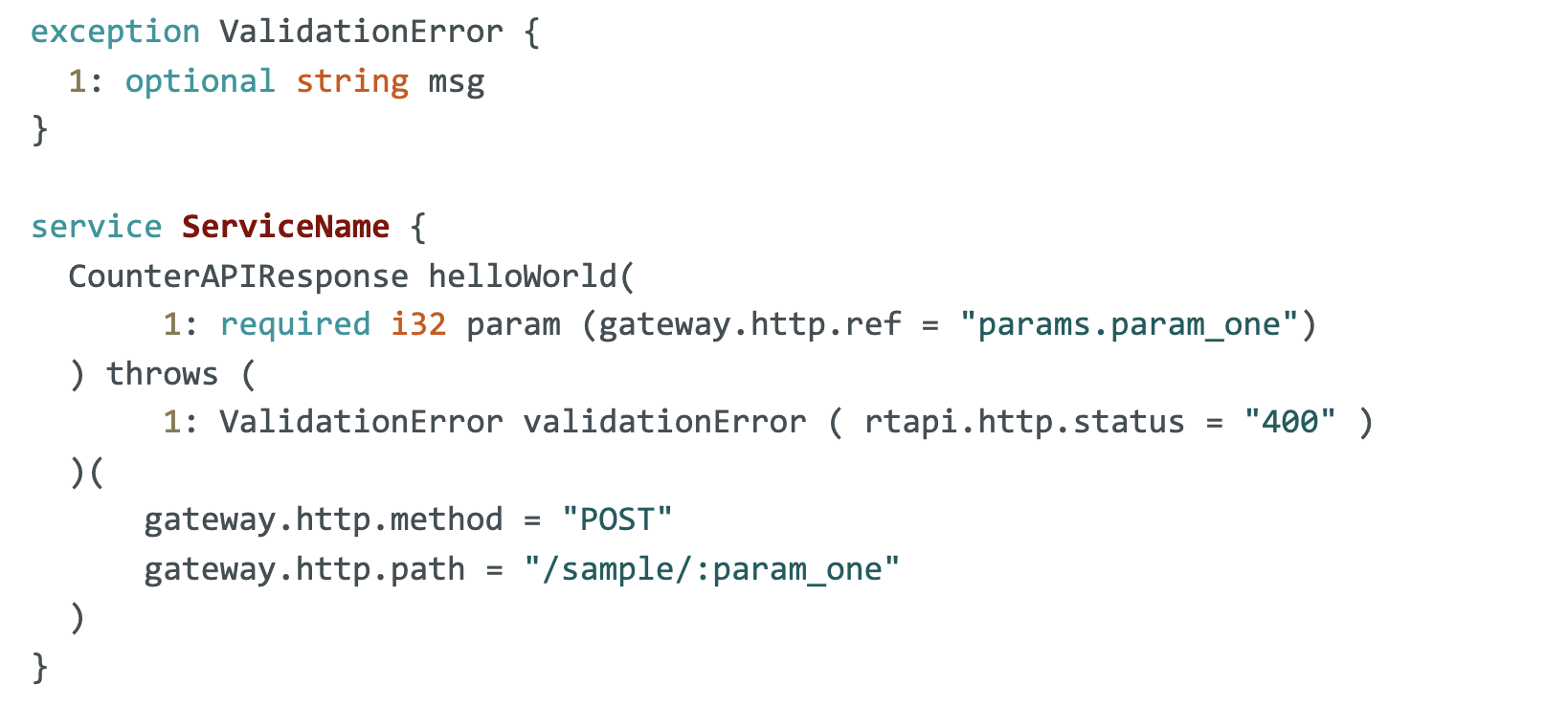

There are more than a dozen other annotations to help the protocol manager manage the behavior of an HTTP request using thrift annotations.
Middleware
The middleware is the most flexible and feature-rich component in the stack. It allows for the gateway platform to expose higher-order features to an API gateway user. We will cover detailed features powered by middleware in the unlocking features section. Here we will focus on the middleware configuration in a YAML file.

In the configuration above, the authentication middleware is added to the API. The authentication middleware will receive the configured path parameter from the value of header.x-user-uuid. The second middleware configured above is the transformRequest middleware, which is instructed to copy region from the incoming request to regionID in the call to the backend service. When developing a new middleware, it defines a schema for all the configurable parameters that the API developer needs to provide.
Handler
The primary configurations that power a handler revolve around validation and mapping an incoming request to backend client request parameters.

The above configuration provides the input a handler needs for understanding the back-end client to which a request should be mapped. If the incoming request fields exactly match the back-end service, the above configuration will suffice. If the fields are differently named, they will have to be mapped using a transformRequest middleware.
Client
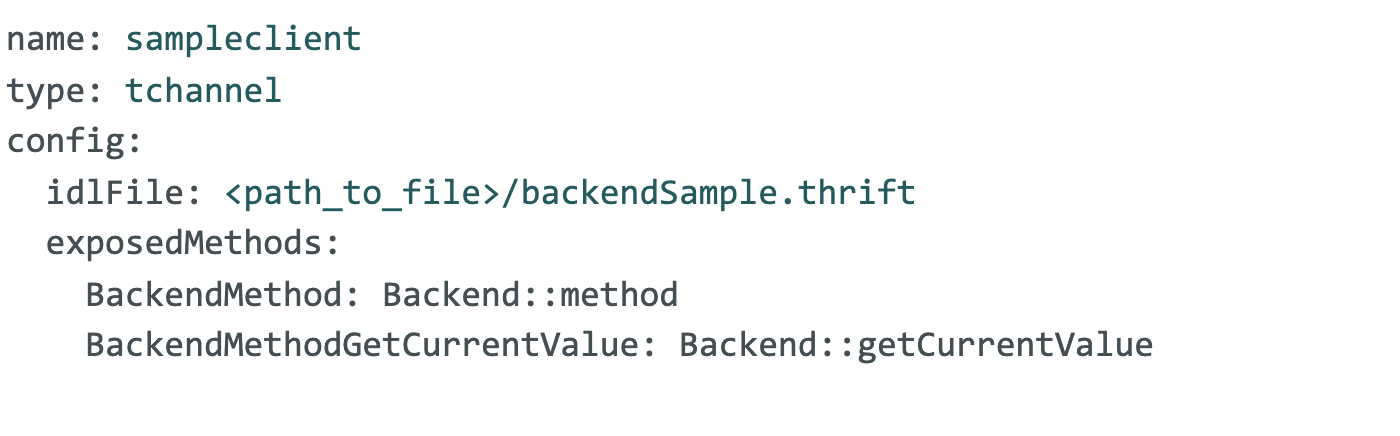
The configuration of a back-end client is split between a YAML file and thrift files. In the example below, a new back-end service with the TChannel protocol is configured with request and response definitions defined in the backendSample.thrift file, with two methods that can be called.
Note again that the method Backend::method could also truly be HTTP APIs, with a path like /backend/method represented equivalently in the Thrift spec, with the help of annotations.
Runnable Artifact
The YAML and Thrift configurations of all the components described in the previous section are necessary to completely describe one single API configuration. The self-served gateway is responsible for ensuring that these component configurations come together to provide a gateway runtime.
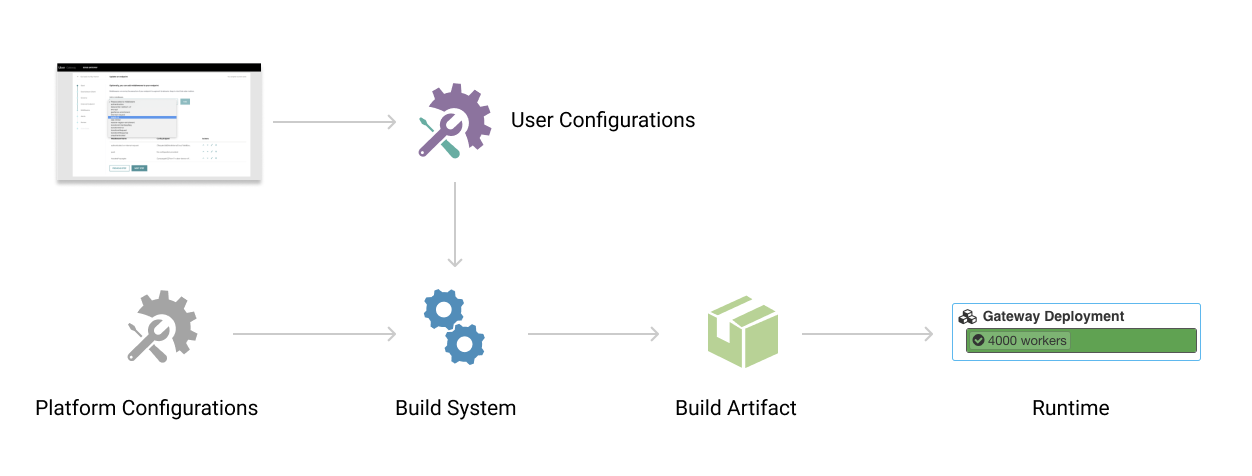
There are two flavors of gateways: one takes configurations and dynamically serves APIs based on them (much like kong, tyk, and reverse proxies like envoy, Nginx); another generates a build artifact using a code generation step based on the input configurations. At Uber, we chose the latter, code generation approach to create a runnable build artifact.
Generate schema objects: All schema files are run through processors to output native golang code for thriftrw and protoc. This is needed for serialization/deserialization and for code generation of the client interfaces.
Generate custom serialization: API contracts with mobile apps need custom serialization related to i64, enum types, and multiple protocols.
DAG of dependendencies: Code for endpoints, backend clients, and middleware are generated statically. There are inherent dependencies in code generations. Clients are independent and can be generated immediately. Middleware can depend on zero or more clients for their functionality. Endpoints can depend on zero or more middleware and zero or one client. This DAG (directed acyclic graph) is resolved at build time.
Since the clients are generated independently from the endpoints, an endpoint can be an HTTP, while a backend service can be gRPC. The binding is done in this step of the Edge Gateway’s build.
API generation: In this final step, iteration over the DAG is done to generate all endpoints. A single generation step is as follows: load the template, generate endpoint request to client request mapping and vice versa, inject dependencies, and hydrate idl objects with request-response transformations.
The entire working of code generation is abstracted as an Uber OSS lib, Zanzibar.
Unlocking features
An advantage of centralized systems is to build features that can benefit all onboarded users. With a feature-rich gateway like the Edge Gateway, there are multiple avenues to build features that can be leveraged by all APIs accessing Uber’s internal services.
Here are some examples of features that are already developed, as well as some still in the pipeline.
Auditing pipeline
The Edge Gateway emits an access log with rich metadata that is persisted for auditing. It is critical to maintain an audit record of all the API access patterns from all our products. It allows for security audits when malicious actors try to access our APIs using automated systems, and helps build a profile of various products across versions, geographies, and apps.
This pipeline helps to capture bugs, issues, and anomalies quickly across specific SDK versions, apps, geographies, or internet providers. The audit pipeline is enabled across all our apps.
Authentication
Every external API request is Authenticated (AuthN) and/or Authorized (AuthZ). The platform provides several reusable implementations for AuthX as middleware that the user can select from their endpoint. This removes the concerns on how these AuthN/AuthZ are implemented as well as enforces that an endpoint uses at least one of the provided implementations. Updates to these implementations can be seamlessly made by the platform owners that will automatically apply to all the endpoints.
Circuit breaking
Each of the clients used to call a back-end service is wrapped with a circuit breaker. Anytime a back-end service experiences increased latency or error rate (which are configurable), the circuit breaker will kick in, preventing any cascading outages. This also provides room for recovering a service that has already deteriorated.
Rate limiting
An endpoint owner may elect to rate limit an API. Some examples of provided implementations are rate limiting based on userID, user-agent, IP, combinations of some of the attributes of the request, etc. Limits can be enforced based on specific fields from path/query params, headers, or body. This allows the flexibility to provide application-aware rate-limiting policies more granular than a simple user-level API access. Each endpoint can be independently assigned a quota dynamically without needing redeployment.
Documentation
All configurations in YAML and Thrift completely describe an API. This provides an option to auto-generate documentation for all the gateway APIs in a consistent way.
Mobile client generation
All of Uber’s mobile apps generate services and models based on the Thrift IDL to interact with the server. A CI job fetches all of the endpoint IDL from the gateway and runs a custom code-generation for the various models. The mobile code-gen also depends on various custom Thrift annotations, such as exception status codes, URL path, and HTTP method. Any backward-incompatible change to an endpoint schema is prevented by a CI job that runs against the generated code review.
Response field trimming
Since the creation of APIs is easy and multiple endpoints can be backed by the same underlying client service. We have the ability to create APIs that granularly select specific fields required for a user experience instead of responding with the full size of a back-end response.
Data center affinity
Having redundant data centers and zones is the current, de facto architecture for large-scale web companies. APIs that belong to different business units or domains are hosted on the gateway and each business unit can define their workload sharding across multiple data centers. Edge Gateway provides a cache that business units can write into to configure a user, region, or version affinity to the appropriate data center. The gateway would then ensure rerouting the incoming APIs from specific users, devices, or apps by respecting the data center affinity information.
Short-term users bans
Account-level bans are the hammer to deal with malicious actors. For users who are temporarily abusing the system, the gateway provides a central place for preventing API access from specific users for a short period of time. This approach is similar to the data center affinity where the gateway can provide an external cache to store blocked users with a TTL. The fraud and security systems can provide the users, app versions, or other identifiers for blocking. The Edge gateway will ensure enforcement of these short-term bans to protect our users.
Challenges and Lessons
During the development of the gateway, we had to make choices on multiple aspects of the design. Some choices led us to very exciting outcomes while some did not provide the expected return on investment. We will briefly touch on a few of the challenges.
Language
At the time of development of the gateway, our language choices were Go and Java. Our previous generation was in Node.js. While that was a very suitable language for building an IO-heavy gateway layer, we decided to align with the languages supported by the language platform teams at Uber. Go provided significant performance improvements. The lack of generics resulted in a significant amount of generated code during build time to a point where we were hitting the limits of the Go linker. We had to turn off the symbol table and debug information during the binary compilation. Language naming conventions like ID, HTTP, and reserved keywords in Go (but not in Thrift) created failures that exposed the internal implementation details to the end users.
Serialization Format
Our gateway’s protocol manager is able to implement multiple protocols. This feature exposed itself to complex compatibility issues, such as the data type mismatch in representing Union, Set, List, and Maps in JSON schema vs Thrift schema. We had to come up with homegrown conventions for that mapping.
Config Store
As previously stated, user configurations are stored in Git. However, some of these configs are dynamic in nature, like API rate limits. Previously a change there needed code generation and deployment. This is time-consuming, and hence we now store the dynamic portion of user configuration in a config store.
Gateway UI
Development of single APIs is easy in the gateway UI, but it becomes harder to manage in developing batch edit flows. This is especially true when Thrift files refer to other Thrift files and the nesting can be arbitrarily deep. Once a user provides the configuration and the build system takes over, surfacing build failures to the UI can get challenging as the build system evolves independently of the UI. It is critical to keep a consistent contract between them to surface errors.
Understanding the payload
Most gateway features can be developed without the need to deserialize the incoming or outgoing payload. Our use case of protocol interoperability forces us to deserialize the payload. This adds to the complexity of the build system and also the performance of the runtime. If the backend and mobile protocol are the same, it might benefit to limit the gateway to access only the protocol verbs and headers without deserializing the body. It however would limit some complex gateway features.
A rich gateway, like the one we described, is a complex undertaking. If you are interested to follow the same path, zanzibar can provide an extensible module from which to bootstrap. At Uber, we are developing a flavor of API gateway runtime for gRPC requests from our apps to back-end services based on envoy, with no significant user experience changes to our self-serve UI. If you are interested and passionate, come talk to us!
Acknowledgment
This work was not possible without the significant contributions of so many people who participated in the development of the gateway. Some key acknowledgments are – Abhishek Panda, Alex Hauser, Aravind Gopalan, Chao Li, Chuntao Lu, Gregory Trowbridge, Jake Verbaten, Karthik Karuppaiya, Maximiliano Benedetto, Michael Sindler, Olivia Zhang, Pavel Astakhov, Rena Ren, Steven Bauer, Tejaswi Agarwal, Uday Medisetty, and Zhenghui Wang.
Appendix

Madan Thangavelu
Madan Thangavelu is a Director of Engineering at Uber. Over the last 7 years, he has witnessed and contributed to the exciting hyper-growth phase of Uber. He spent 4 years leading the API gateway and streaming platform teams at Uber. He is currently the engineering lead for Uber's Fulfillment Platform that powers real-time global scale shopping and logistics systems.

Abhishek Parwal
Abhishek Parwal is a Sr. Software Engineer II at Uber. Over the last 3+ years at Uber, he has led & built multiple large-scale infrastructure platforms from the ground up. This includes the Edge Gateway platform, which lays a solid foundation to expose API for all teams at Uber. Currently, he is helping in building the next generation Fulfillment platform powering real-time global scale shopping and logistics systems.

Rohit Patali
Rohit Patali is a Sr. Software Engineer II at Uber. Over the last 3 years, he has helped build Uber’s API Gateway from the ground up, led multiple large-scale projects to productionalize the gateway as well as safely migrate 1500+ APIs from the NodeJS legacy system, and helped scale it up to 500K QPS.
Posted by Madan Thangavelu, Abhishek Parwal, Rohit Patali
Related articles




How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Network IDS Ruleset Management with Aristotle v2

Load Balancing: Handling Heterogeneous Hardware

Using Uber: your guide to the Pace RAP Program

Balancing HDFS DataNodes in the Uber DataLake
Products
Company
