
With new content every week, our blog showcases the technologies—and the people behind them—that power the Uber platform.
In 2018, we published articles on topics spanning the breadth and depth of our technical stack, from a series detailing our driver app rewrite (codenamed Carbon) to our Michelangelo machine learning platform. We shed light on the experiences and backgrounds of our technologists, including our Q&A with site reliability engineering manager and UberHUE member, Sumbry, and our profile from fabric weaver turned machine learning engineer Samuel Zemedkun, to articles documenting the life and work of our tech offices in Amsterdam and Sofia. We also used our platform to spotlight our organization’s capstone events, including our second annual Uber Tech Day and our first Uber Open Summit.
Below, we highlight some of the year’s most popular articles as well as some of our personal favorites:

Uber’s growth has been accompanied by a corresponding increase in data, and our engineers continually work on systems to securely store and make actionable data available to internal team members who need it to improve our services. The rapid pace of our infrastructure growth made 2018 a perfect time to reflect on three generations of our Big Data platform. Going from our first data warehousing service in 2014, through our move to Hadoop in 2015, to our current generation, where we developed open source tools such as Hudi and Marmaray, we outline the architecture of a Big Data platform built for scale and resilience.
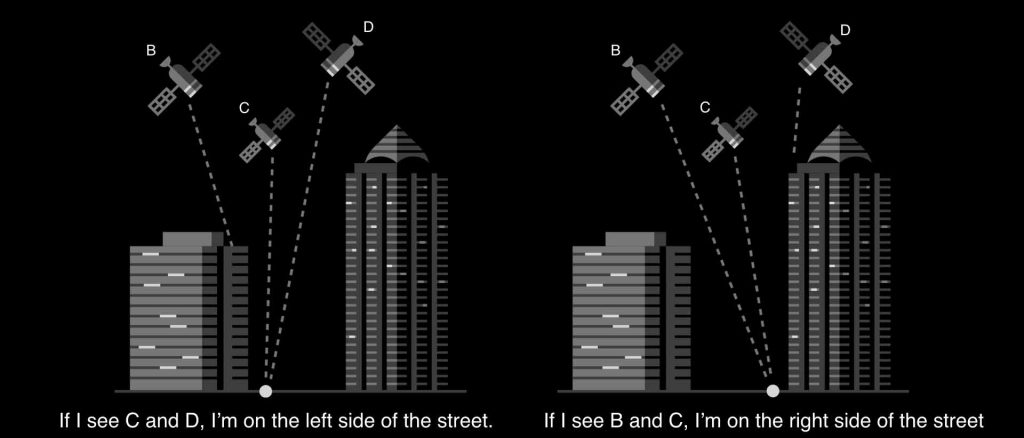
Uber’s transportation and delivery services work real-time in the physical world, and so rely on accurate GPS locations to connect our various customers, from riders to shippers. However, buildings in urban areas can throw off GPS accuracy by as much as 50 meters. To improve our location accuracy, Uber engineers came up with a novel solution for Android phones, using high-definition maps to compensate for blocked signals. This article from 2018 shows one of the many innovative ways we look to improve our services.

Uber’s open source efforts have been going strong in 2018, with our first annual Open Summit and the release of many open source projects. Kepler.gl, one such project created by Shan He and the rest of our Data Visualization team, lets developers show large, geospatial datasets in a map-based, web-friendly format. While we use Kepler.gl to visualize data such as traffic in a city, others have used it to show urban terrain and population. Kepler.gl can be a powerful tool for helping people understand raw data and how it relates to physical spaces. (Post-publishing note: kepler.gl won gold during the 7th annual Information is Beautiful Awards, taking home an award in the Visualization & Information Design category.)
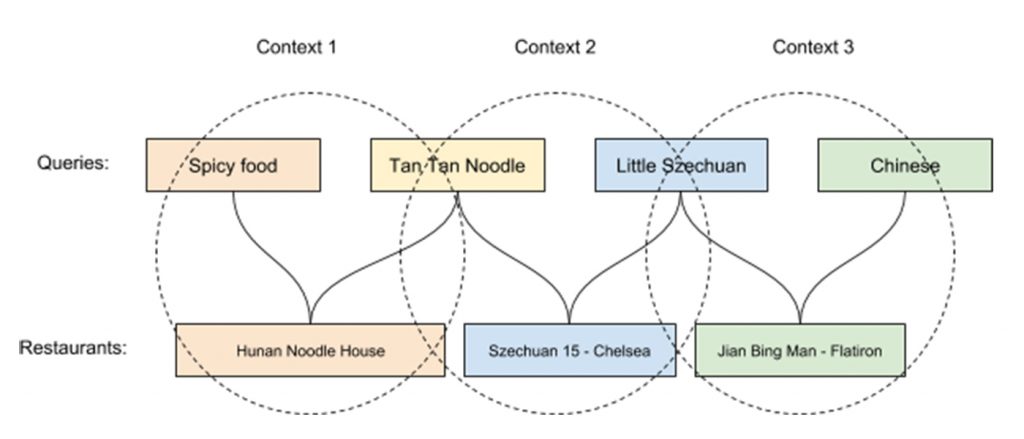
In some ways, Uber Eats grew naturally from our rideshare business, matching eaters and delivery-partners instead of riders and driver-partners. However, Uber Eats opened up new areas of innovation for our engineers. One of the more complicated involves how to help eaters find the food they want. With the growth of Uber Eats in 2018, it was a good time for our engineers to explain how they developed the ability to query the variety of cuisines on offer in any given region, and to go further by actively recommending food options.

Engineers at Uber come from a variety of backgrounds and geographical regions. Of the engineers we have highlighted, Benito Sanchez’s story stands out. His parents brought him across the border from Mexico when he was just ten, and he spent years living in fear of deportation. But the Deferred Action for Childhood Arrivals program gave him a chance to get a college education and realize his aptitude for programming. The story Benito tells about his life is inspirational to all who believe in the American dream.

At this year’s Uber Technology Day, sponsored by our LadyEng women in technology group, female engineers from across Uber gave presentations on a diverse array of projects. One of those engineers, Chunyan Song, presented and wrote a subsequent article about how Uber created a cutting edge financial planning platform, letting us make smart spending decisions in response to real-time dynamics and forecast economic conditions at the city level. Leveraging machine learning and data science, this financial platform serves as a highlight of Uber’s technical acumen in 2018.
 Uber leverages AI, machine learning, and deep learning to train models in a multitude of areas, from optimizing trip forecasting during high-traffic events to building the sensing and perception technologies that power our self-driving cars. In April 2018, Uber AI Labs’ Felipe Petroski Such, Kenneth O. Stanley, and Jeff Clune released code that makes it possible to conduct deep learning research much faster and cheaper than existing models, benefiting both Uber and the AI research community at large. For perspective, the time it takes to train deep neural networks to play Atari, which takes ~1 hour on 720 CPUs, takes ~4 hours on a single modern desktop when leveraging AI Labs’ code. Most recently, Uber AI Labs developed Go-Explore, a deep learning algorithm that takes their work a step further by successfully scoring over 2,000,000 points on storied Atari game Montezuma’s Revenge.
Uber leverages AI, machine learning, and deep learning to train models in a multitude of areas, from optimizing trip forecasting during high-traffic events to building the sensing and perception technologies that power our self-driving cars. In April 2018, Uber AI Labs’ Felipe Petroski Such, Kenneth O. Stanley, and Jeff Clune released code that makes it possible to conduct deep learning research much faster and cheaper than existing models, benefiting both Uber and the AI research community at large. For perspective, the time it takes to train deep neural networks to play Atari, which takes ~1 hour on 720 CPUs, takes ~4 hours on a single modern desktop when leveraging AI Labs’ code. Most recently, Uber AI Labs developed Go-Explore, a deep learning algorithm that takes their work a step further by successfully scoring over 2,000,000 points on storied Atari game Montezuma’s Revenge.
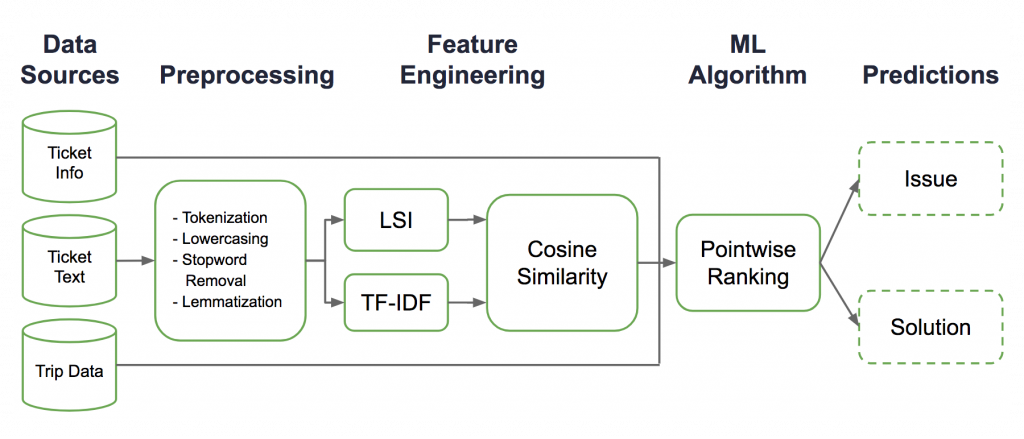
Uber Customer Obsession team leverages an in-house platform that integrates customer support ticket context with information from five distinct customer communication channels for easy ticket resolution. In this article, data scientist Huaixiu Zheng, software engineers Guoqin Zheng, Naveen Somasundaram, and Basab Maulik, data science manager Hugh Williams, and engineering manager Jeremy Hermann discuss how they built our Customer Obsession Ticket Assistant (COTA), a tool that uses machine learning and natural language processing techniques to help agents deliver better customer support. In August 2018, they published a follow-up article that touched on how they scaled COTA with deep learning to broaden its impact and further enhance our support solutions to free up Customer Obsession agents for more demanding tasks.

Engineers follow paths to software engineering as varied and diverse as the types of programming languages they work with, yet the pressure to be experts from the get-go can seem overwhelming. Uber for Business’ Emilee Urbanek knows this firsthand, as she regales in this article about her experience overcoming imposter syndrome as she transitioned to a full-time role as a software engineer at Uber. Her advice? Build confidence, trust your first instinct, and always be teaching, always be learning—valuable learnings to carry into 2019. For more wisdom from our LadyEng community, be sure to check out our Q&As with Sophia Vicent, Director of Technical Program Management, and Shobhana Ahluwalia, Head of Information Technology.
We look forward to bringing you more articles in 2019—to tide yourself over until then, follow the Uber Eng Twitter account, sharing updates daily, and subscribe to the Uber Engineering Newsletter for more from our blog.

Molly Vorwerck
Molly Vorwerck is the Eng Blog Lead and a senior program manager on Uber's Tech Brand Team, responsible for overseeing the company's technical narratives and content production. In a previous life, Molly worked in journalism and public relations. In her spare time, she enjoys scouring record stores for Elvis Presley records, reading and writing fiction, and watching The Great British Baking Show.

Wayne Cunningham
Wayne Cunningham, senior editor for Uber Tech Brand, has enjoyed a long career in technology journalism. Wayne has always covered cutting edge topics, from the early days of the web to the threat of spyware to self-driving cars. In his spare time he writes fiction, having published two novels, and indulges in film photography.
Posted by Molly Vorwerck, Wayne Cunningham
Related articles



How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global

Most popular

Uber Health and Findhelp support patients beyond the four walls of a medical office

Stopping Uber Fraudsters Through Risk Challenges

Scaling AI/ML Infrastructure at Uber

Information for driving during the week of Super Bowl LVIII
Products
Company
